NVMe驱动解析-响应I/O请求
在机械硬盘统治天下的时代,由于其随机访问性能差,Linux内核开发者把重点放在缓存I/O, 合并I/O等方面,并没有考虑多队列的设计;Flash的出现改变了这一切,Flash的低延迟,高并发潜质急需一种新的内核协议栈来发挥其潜能,NVMe解决了这个问题。下面就来看看NVMe驱动是如何做到的。
前面的文章提到了NVMe对系统中队列配置的建议,Linux的NVMe驱动采用一个Core独占一个Queue(由Completion Queue和Submission Queue组成)的方式。这种设计避免了一个队列被多个Core竞争访问,大家都各自使用自己的Queue,互不干扰。
创建NVMe Queue
在建立这些队列之前,驱动通过内核函数num_online_cpus获取当前系统中运行的CPU数量n,然后通过Set Feature命令咨询SSD的Queue数量限制m,选择两者较小值在host端创建队列(Queue),同时通过NVMe创建队列命令请求SSD也创建同样的数量。
关于Queue有一个重要的概念,那就是队列深度。简单说就是这个Queue能够放多少个成员(比如NVMe Command)。在NVMe中,这个队列深度是由NVMe SSD决定的,存储在NVMe设备的BAR空间里。另外,NVMe驱动没有区分Namespace,也就是一个设备上的多个Namespace共享这些队列资源。
队列用来存放NVMe Command,NVMe Command是Host与SSD Controller交流的基本单元,应用的I/O请求也要转化成NVMe Command。前面提到,传统的Linux内核无法适应新的需求,但是极具灵活性的Linux提供了blk_queue_make_request函数。调用这个函数注册自定义的队列处理方法,就可以bypass Block层的队列处理。只要内核的Block层收到上层发送的IO请求,就会选择该方法处理(这里特指read,write等系统调用,由于NVMe兼容了SCSI命令,也可以通过IOCTL发送IO请求,但不经过此路径)。
通过Submission Queue提交I/O请求
Block层下发的IO请求以BIO表示。我们需要通过DMA发送这些数据,Command使用dma_alloc_coherent分配DMA地址,但是BIO是存放在普通的内核线程空间的(线程的虚拟空间不能直接作为DMA地址,因为写入的数据可能被Cache,而且也不是物理地址),使用dma_alloc_coherent分配再将BIO中的数据拷贝显然不是有效的方法。这里linux提供了另一个函数dma_map_single,这个函数能够将虚拟空间地址(BIO数据存放地址)转换成DMA可用地址,并且多个IO请求的DMA地址可以通过scatterlist来表示。有了DMA地址就可以把BIO封装成NVMe Command发送出去。从BIO到NVMe Command有可能会经过拆分,放入等待队列等。我们知道,驱动会给每个CPU分配一个Queue,那么I/O请求到来时,该由哪个Queue来存放这个Command呢?你可能已经想到,应该由当前线程运行的CPU所属的Queue,这样才能保证Queue不被其他Core抢占,驱动使用get_cpu()获得当前处理I/O请求的CPU号来索引对应的Queue。
227 struct nvme_queue *get_nvmeq(struct nvme_dev *dev)
228 {
229 return dev->queues[get_cpu() + 1];
230 }BIO封装成的Command会顺序存入Submission Queue中。如下,对于Submission Queue来说,使用Tail表示最后操作的Command Index(nvmeq->sq_tail)。每存入一个Command,Host就会更新Queue对应的Doorbell寄存器中的Tail值。Doorbell定义在BAR空间,通过QID可以索引到(参见附录)。NVMe没有规定Command存入队列的执行顺序,Controller可以一次取出多个Command进行批量处理,所以一个队列中的Command执行顺序是不固定的(可能导致先提交的请求后处理)。
684 result = nvme_map_bio(nvmeq, iod, bio, dma_dir, psegs);
685 if (result <= 0)
686 goto free_cmdid;
687 length = result;
688
689 cmnd->rw.command_id = cmdid;
690 cmnd->rw.nsid = cpu_to_le32(ns->ns_id);
691 length = nvme_setup_prps(nvmeq->dev, &cmnd->common, iod, length,
692 GFP_ATOMIC);
693 cmnd->rw.slba = cpu_to_le64(nvme_block_nr(ns, bio->bi_sector));
694 cmnd->rw.length = cpu_to_le16((length >> ns->lba_shift) - 1);
695 cmnd->rw.control = cpu_to_le16(control);
696 cmnd->rw.dsmgmt = cpu_to_le32(dsmgmt);
697
698 if (++nvmeq->sq_tail == nvmeq->q_depth)
699 nvmeq->sq_tail = 0;
700 writel(nvmeq->sq_tail, nvmeq->q_db);通过Completion Queue获得处理结果
SSD Controller根据Doorbell的值,获取NVMe Command和对应数据,待处理完成后将结果存入Completion Queue中。Controller通过中断的方式通知Host,驱动为每一个Queue分配一个MSI/MSI-X中断。创建NVMe Queue时,调用pci_enable_msix(pdev, dev->entry, nr_io_queues)申请nr_io_queues(与NVMe Queue数量相等)个中断,并将中断信息存入dev->entry中,dev->entry是msix_entry类型。其中vector是kernel用来标识中断号,entry则由驱动管理(主要用来索引中断号,计作Index_irq)。
1118 struct msix_entry {
1119 u32 vector; /* kernel uses to write allocated vector */
1120 u16 entry; /* driver uses to specify entry, OS writes */
1121 };驱动使用request_irq()将所有的dev->entry[Index_irq].vector注册到kernel,并且绑定中断处理函数nvme_irq。此中断函数先将Completion Command从Completion Queue中取出,然后把队列的head值加1,并调用上层的Callback函数(完成BIO处理)。由于NVMe Command可以批量处理,这里使用for循环取出所有新的Completion Command。
731 static irqreturn_t nvme_process_cq(struct nvme_queue *nvmeq)
732 {
733 u16 head, phase;
734
735 head = nvmeq->cq_head;
736 phase = nvmeq->cq_phase;
737
738 for (;;) {
739 void *ctx;
740 nvme_completion_fn fn;
741 struct nvme_completion cqe = nvmeq->cqes[head];
742 if ((le16_to_cpu(cqe.status) & 1) != phase)
743 break;
744 nvmeq->sq_head = le16_to_cpu(cqe.sq_head);
745 if (++head == nvmeq->q_depth) {
746 head = 0;
747 phase = !phase;
748 }
749
750 ctx = free_cmdid(nvmeq, cqe.command_id, &fn);
751 fn(nvmeq->dev, ctx, &cqe);
752 }
753
754 /* If the controller ignores the cq head doorbell and continuously
755 * writes to the queue, it is theoretically possible to wrap around
756 * the queue twice and mistakenly return IRQ_NONE. Linux only
757 * requires that 0.1% of your interrupts are handled, so this isn't
758 * a big problem.
759 */
760 if (head == nvmeq->cq_head && phase == nvmeq->cq_phase)
761 return IRQ_NONE;
762
763 writel(head, nvmeq->q_db + (1 << nvmeq->dev->db_stride));
764 nvmeq->cq_head = head;
765 nvmeq->cq_phase = phase;
766
767 return IRQ_HANDLED;
768 }不过,有一个问题要面对,Controller写入Command后,只有中断触发通知Host,没有类似于Head/Tail机制告诉Host可以取哪些Completion Command。机智的NVMe设计者在Completion Command中加了一个Phase Tag状态位,这个状态位在每次队列写满后,发生反转,这样只要Host端维护一个同样的状态位(nvmeq->cq_phase),就可以判断要取的Command(每次Head置0时,host端同样也反转一次)。
处理完Command后,往Completion Queue的Doorbell写入Head值,通知NVMe Controller操作完成。中断处理结束。
到这里,似乎就结束了。但是有一点似乎不明晰,SSD Controller写完Completion Command后,准备发送MSI消息时,它是怎么知道要触发哪个中断呢?而且所有的中断都注册到这个中断处理函数上了,中断函数怎么去找对应的Queue。主要有两点:
1,在Host向SSD Controller发送创建Completion Queue时,传递了中断Vector值和QID。这样Host和Controller两端QID对应的Queue就与Vector绑定起来了。
2,在使用request_irq()注册中断处理函数时,有一个参数可以传递自定义类型地址,这个地址会在kernel调用中断函数时,作为参数传递给驱动。那么把中断Vector对应的Queue对象地址作为这个参数传递进去,就可以实现在处理函数中找到对应的Queue了。
Head/Tail机制
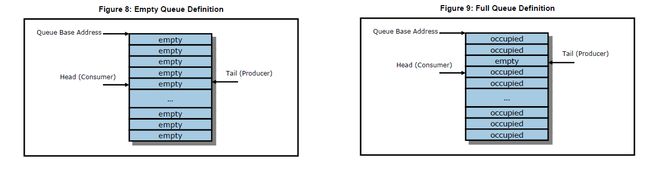
从前面的解读得知,Submission Queue使用Tail,Completion Queue使用Head,两者均由Host操作。处理完一个Command,Tail或Head加1,当大于Queue Depth时,则回到0。通过对比Head和Tail的值,就知道一个Queue中有多少未处理的Submission Command。下面的图摘自NVMe Spec,有兴趣的同学可以据此琢磨下Empty Queue和Full Queue的定义。
总结
这篇文章着重介绍了NVMe I/O 请求的处理过程,至此,整个NVMe的驱动框架大致介绍完,由于篇幅限制,很多细节没有描述。随着越来越多的企业参与开发和使用NVMe,NVMe技术正在从追求性能走向成熟稳定。但是企业的需求是多样的,技术的创新是无止尽的,下一期将向大家介绍Host端NVMe的另一种实现方式,SPDK。
参考
Linux Kernel V3.10
NVM Express V1.1b
本文作者——张元元
张元元是Memblaze SSD事业部应用工程师,研究方向涉及PCIe SSD在VSAN、Docker等环境中的应用及优化。对于服务器虚拟化、NVMe驱动的实现、Linux内核及容器技术有深入的研究。本系列文章为张元元对于NVMe驱动及相关技术的全面解读,更多张元元的文章请关注他的微信公众号:yuan_memblaze
