【atomic】再谈从atomic关键字说到多线程安全(内含iOS给代码加锁方法总结)
再谈从atomic关键字说到多线程安全(内含iOS给代码加锁方法总结)
atomic是什么
- 原子性:在默认情况下,由编译器所合成的方法会通过锁定机制确保其原子性(atomicity)。如果声明属性时不显式地声明nonatomic关键字,那这个属性就是“原子的”(atomic)。如果属性具备nonatomic特质,则不使用同步锁。
- atomic 和 nonatomic这对属性关键字是和线程安全挂钩的,虽然 atomic 属性关键字会给该 property 的 getter和setter方法加锁,但它也不能保证多线程安全。另外,atomic由于加锁也会带来一些性能损耗,所以我们在编写iOS代码的时候,一般声明property为nonatomic,在需要做多线程安全的场景,自己去额外加锁做同步。
- 那么我们下面就来看看多为什么线程会不安全
多线程到底不安全在哪
白话来讲,主要还是因为属性的set方法不只是有一行代码的方法体
换句话讲,就是set方法中的多行代码可能执行在不同的线程中,就是说一个实例变量在一个线程已经release了,但在另外一个线程中还在对它赋值,这样会导致崩溃
Property(属性)
-
我们可以简单的将property分为值类型和对象类型,值类型是指primitive type,包括int, long, bool等非对象类型,另一种是对象类型,声明为指针,可以指向某个符合类型定义的内存区域。
Memory Layout(内存布局)
-
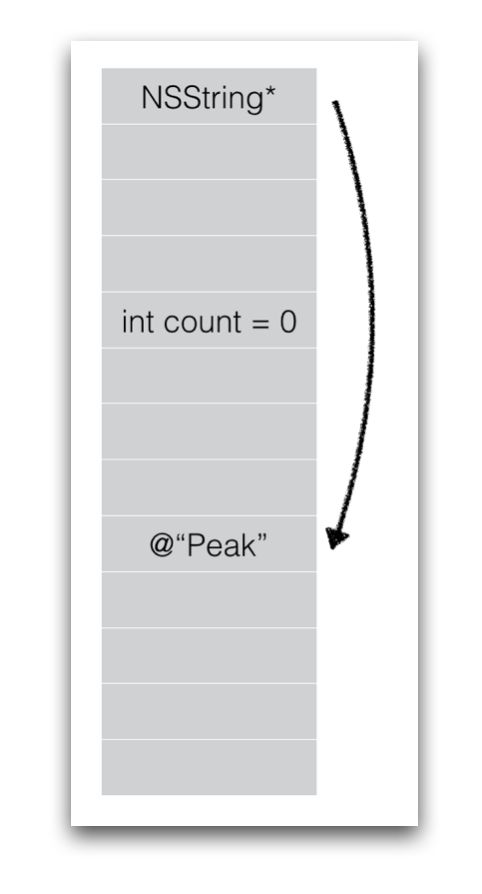
以64位系统为例,指针NSString*是8个字节的内存区域,int count是个4字节的区域,而@“Peak”是一块根据字符串长度而定的内存区域。
当我们访问property的时候,实际上是访问上图中三块内存区域。
self.userName = @"peak"; 1是修改第一块区域。
self.count = 10; 1是在修改第二块区域。
[self.userName rangeOfString:@"peak"]; 1是在读取第三块区域。
-
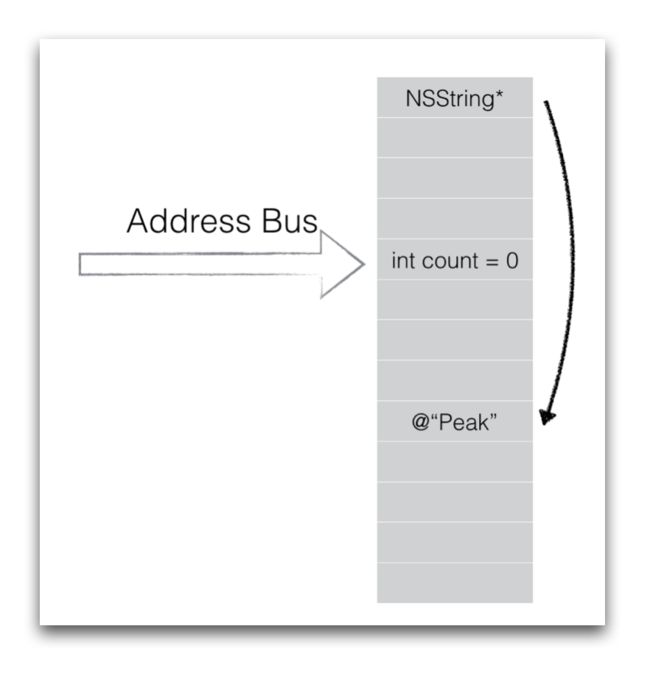
从上图中可以看出,我们只有一个地址总线,一个内存。即使是在多线程的环境下,也不可能存在两个线程同时访问同一块内存区域的场景,内存的访问一定是通过一个地址总线串行排队访问的,所以在继续后续之前,我们先要明确几个结论:
**结论一**:内存的访问时串行的,并不会导致内存数据的错乱或者应用的crash。 **结论二**:如果读写(load or store)的内存长度小于等于地址总线的长度,那么读写的操作是原子的,一次完成。比如**bool,int,long在64位系统下的单次读写都是原子操作**。 接下来我们根据上面三种property的分类逐一看下多线程的不安全场景。 12345
值类型Property
-
先以BOOL值类型为例,当我们有两个线程访问如下property的时候:
@property (nonatomic, assgin) BOOL isDeleted; //thread 1 bool isDeleted = self.isDeleted; //thread 2 self.isDeleted = false; 1234567线程1和线程2,一个读,一个写,对于BOOL isDeleted的访问可能有先后之分,但一定是串行排队的。而且由于BOOL大小只有1个字节,64位系统的地址总线对于读写指令可以支持8个字节的长度,所以对于BOOL的读和写操作我们可以认为是原子的,所以当我们声明BOOL类型的property的时候,从原子性的角度看,使用atomic和nonatomic并没有实际上的区别
-
同理int类型长度为4字节,读和写都可以通过一个指令完成,所以理论上读和写操作都是原子的。从访问内存的角度看nonatomic和atomic也并没有什么区别。
那atomic到底有什么用呢?:
-
用处一: 生成原子操作的getter和setter。
设置atomic之后,默认生成的getter和setter方法执行是原子的。也就是说,当我们在线程1执行getter方法的时候,线程B如果想执行setter方法,必须先等getter方法完成才能执行。举个例子,在32位系统里,如果通过getter返回64位的double,地址总线宽度为32位,从内存当中读取double的时候无法通过原子操作完成,如果不通过atomic加锁,有可能会在读取的中途在其他线程发生setter操作,从而出现异常值。如果出现这种异常值,就发生了多线程不安全。
-
用处二:设置Memory Barrier(内存屏障)
对于Objective C的实现来说,几乎所有的加锁操作最后都会设置memory barrier,atomic本质上是对getter,setter加了锁,所以也会设置memory barrier。
1、谈谈内部实现
在 objc4-723 的 Objective-C runtime 实现中,property 的 atomic 是采用 spinlock_t 也就是俗称的自旋锁实现的。
// getter
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic)
{
// ...
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
id value = objc_retain(*slot);
slotlock.unlock();
// ...
}
1234567891011121314
// setter
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
// ...
if (!atomic)
{
oldValue = *slot;
*slot = newValue;
}
else
{
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
// ...
}12345678910111213141516171819
2、能否保证线程安全?
atomic通过这种方法,在运行时保证 set,get方法的原子性。
仅仅是保证了set,get方法的原子性。
这种线程是不安全的。
@property (atomic, assign) int intA;
//线程A
for (int i = 0; i < 10000; i ++)
{
self.intA = self.intA + 1;
NSLog(@"Thread A: %d\n", self.intA);
}
//线程B
for (int i = 0; i < 10000; i ++)
{
self.intA = self.intA + 1;
NSLog(@"Thread B: %d\n", self.intA);
}
123456789101112131415161718
self.intA 是原子操作,但是self.intA = self.intA + 1这个表达式并不是原子操作。
所以线程是不安全的。
threadA 在执行表达式 self.intA之后 self.intA = self.intA + 1;并没有执行完毕
此时threadB 执行self.intA = self.intA + 1;
再回到threadA时,self.intA的数值就被更新了
所以仅仅使用atomic并不能保证线程安全。
指针Property
指针Property一般指向一个对象,比如:
@property (atomic, strong) NSString *userName;
1
无论iOS系统是32位系统还是64位,一个指针的值都能通过一个指令完成load或者store。但和primitive type不同的是,对象类型还有内存管理的相关操作。在MRC时代,系统默认生成的setter类似如下:
- (void)setUserName:(NSString *)userName {
if(_uesrName != userName) {
[userName retain];
[_userName release];
_userName = userName;
}
}
1234567
不仅仅是赋值操作,还会有retain,release调用。如果property为nonatomic,上述的setter方法就不是原子操作,我们可以假设一种场景,线程1先通过getter获取当前_userName,之后线程2通过setter调用[_userName release];,线程1所持有的_userName就变成无效的地址空间了,如果这个时候再给这个地址空间发消息就会导致crash(因为这会已经被释放了),出现多线程不安全的场景。
到了ARC时代,Xcode已经替我们处理了retain和release,绝大部分时候我们都不需要去关心内存的管理,但retain,release其实还是存在于最后运行的代码当中,atomic和nonatomic对于对象类的property声明理论上还是存在差异,不过我在实际使用当中,将NSString*设置为nonatomic也从未遇到过上述多线程不安全的场景,极有可能ARC在内存管理上的优化已经将上述场景处理过了,所以我个人觉得,如果只是对对象类property做read,write,atomic和nonatomic在多线程安全上并没有实际差别。
指针Property指向的内存区域
这一类多线程的访问场景是我们很容易出错的地方,即使我们声明property为atomic,依然会出错。因为我们访问的不是property的指针区域,而是property所指向的内存区域。可以看如下代码:
@property (atomic, strong) NSString *stringA;
//thread A
for (int i = 0; i < 100000; i ++) {
if (i % 2 == 0) {
self.stringA = @"a very long string";
}
else {
self.stringA = @"string";
}
NSLog(@"Thread A: %@\n", self.stringA);
}
//thread B
for (int i = 0; i < 100000; i ++) {
if (self.stringA.length >= 10) {
NSString* subStr = [self.stringA substringWithRange:NSMakeRange(0, 10)];
}
NSLog(@"Thread B: %@\n", self.stringA);
}
1234567891011121314151617181920
虽然stringA是atomic的property,而且在取substring的时候做了length判断,线程B还是很容易crash,因为在前一刻读length的时候self.stringA = @"a very long string";,下一刻取substring的时候线程A已经将self.stringA = @"string";,立即出现out of bounds的Exception,crash,多线程不安全。对集合类数组元素个数的操作也同理,十分容易出现越界crash的情况。
是不是使用了atomic就一定多线程安全呢?
-
当使用atomic时,虽然对属性的读和写是原子性的,但是仍然可能出现线程错误:当线程A进行写操作,这时其他线程的读或者写操作会因为该操作而等待。当A线程的写操作结束后,B线程进行写操作,然后当A线程需要读操作时,却获得了在B线程中的值,这就破坏了线程安全,如果有线程C在A线程读操作前release了该属性,那么还会导致程序崩溃。所以仅仅使用atomic并不会使得线程安全,我们还要为线程添加lock来确保线程的安全。
-
上述指针指向的内存区域举的例子描述的也是一种不安全的情况。
-
也就是要注意:atomic所说的线程安全只是保证了getter和setter存取方法的线程安全,并不能保证整个对象是线程安全的。
-
比如:@property(atomic,strong)NSMutableArray *arr;
如果一个线程循环的读数据,一个线程循环写数据,那么肯定会产生内存问题,因为这和setter、getter没有关系。如使用[self.arr objectAtIndex:index]就不是线程安全的。好的解决方案就是加锁。
如何做到多线程安全?
- 说来也简单,重点还是原子性。这的原子性并不是指属性关键字atomic,而是一个相对概念,它所针对的对象粒度可大可小,小到一个属性的访问,大到一整段代码的执行,都可以视为一个粒子。而实现原子性的方法,就是对粒子加锁。
iOS给代码加锁的方式:
- 虽然说是加锁,但在下面给出的几种加锁方式中,也包含了GCD中信号量的方法,首先我们来了解一下信号量(Semaphore)和互斥锁(Mutex)的异同。
-
@synchronized
@synchronized是 iOS 中最常见的锁,用法很简单:
- (void)viewDidLoad { [super viewDidLoad]; [self synchronized]; } - (void)synchronized { NSObject * obj = [NSObject new]; dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ @synchronized(obj){ NSLog(@"线程1开始"); sleep(3); NSLog(@"线程1结束"); } }); dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ sleep(1); @synchronized(obj){ NSLog(@"线程2"); } }); } 1234567891011121314151617181920212223控制台输出: Thread-Lock[24855:431100] 线程1开始 Thread-Lock[24855:431100] 线程1结束 Thread-Lock[24855:431101] 线程2 12345从上面的控制台输出时间可以看出来,在线程 1 内容全部输出之后,才输出了线程 2 的内容,“线程1结束”与“线程2”都是在“线程1开始”3 秒后输出的。
- @synchronized(obj) 指令使用的 obj 为该锁的唯一标识,只有当标识相同时,才为满足互斥,如果线程 2 中的 @synchronized(obj) 改为 @synchronized(self) ,那么线程 2 就不会被阻塞。@synchronized是几种iOS多线程同步机制中最慢的一个,同时也是最方便的一个。苹果建立@synchronized的初衷就是方便开发者快速的实现代码同步。
- 慎用@synchronized(self) ,原因是因为self很可能会被外部对象访问,被用作key来生成一锁,类似上述代码中的
@synchronized (objectA)。两个公共锁交替使用的场景就容易出现死锁。如下例:
//class A @synchronized (self) { [_sharedLock lock]; NSLog(@"code in class A"); [_sharedLock unlock]; } //class B [_sharedLock lock]; @synchronized (objectA) { NSLog(@"code in class B"); } [_sharedLock unlock]; 12345678910111213class A和class B用了两把相同的?(@synchronized的参数一样,objectA是一个class A的对象),如果同时上锁,第二把锁上锁前会相互等待相应的第二把锁开锁,这样就形成了死锁。
所以正确的做法是传入一个类内部维护的NSObject对象,而且这个对象是对外不可见的。
- 传入的obj参数的作用:**synchronized中传入的object的内存地址,被用作key,通过hash map对应的一个系统维护的递归锁。**所以不管是传入什么类型的object,只要是有内存地址,就能启动同步代码块的效果。
- @sychronized(obj){} 内部 obj 被释放或被设为 nil 不会影响锁的功能,但如果 obj 一开始就是 nil,那就会丢失了锁的功能了。
-
NSLock
在Cocoa程序中NSLock中实现了一个简单的互斥锁,实现了NSLocking protocol。
常用相关API:
lock //加锁 unlock //解锁 tryLock //尝试加锁,如果失败了,并不会阻塞线程,只是立即返回 123用法:
- (void)viewDidLoad {
[super viewDidLoad];
[self nslock];
}
- (void)nslock {
NSLock * cjlock = [NSLock new];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[cjlock lock];
NSLog(@"线程1加锁成功");
sleep(2);
[cjlock unlock];
NSLog(@"线程1解锁成功");
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
sleep(1);
[cjlock lock];
NSLog(@"线程2加锁成功");
[cjlock unlock];
NSLog(@"线程2解锁成功");
});
}
12345678910111213141516171819202122232425
控制台输出:
Thread-Lock[39059:846493] 线程1加锁成功
Thread-Lock[39059:846493] 线程1解锁成功
Thread-Lock[39059:846492] 线程2加锁成功
Thread-Lock[39059:846492] 线程2解锁成功
123456
-
dispatch_semaphore
dispatch_semaphore 使用信号量机制实现锁,等待信号和发送信号。
- dispatch_semaphore 是 GCD 用来同步的一种方式,与他相关的只有三个函数,一个是创建信号量,一个是等待信号,一个是发送信号。
- dispatch_semaphore 的机制就是当有多个线程进行访问的时候,只要有一个获得了信号,其他线程的就必须等待该信号释放。
常用相关API:
dispatch_semaphore_create(long value); dispatch_semaphore_wait(dispatch_semaphore_t _Nonnull dsema, dispatch_time_t timeout); dispatch_semaphore_signal(dispatch_semaphore_t _Nonnull dsema); 123用法:
- (void)viewDidLoad { [super viewDidLoad]; [self dispatch_semaphore]; } - (void)dispatch_semaphore { dispatch_semaphore_t semaphore = dispatch_semaphore_create(1); dispatch_time_t overTime = dispatch_time(DISPATCH_TIME_NOW, 6 * NSEC_PER_SEC); dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ dispatch_semaphore_wait(semaphore, overTime); NSLog(@"线程1开始"); sleep(5); NSLog(@"线程1结束"); dispatch_semaphore_signal(semaphore); }); dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ sleep(1); dispatch_semaphore_wait(semaphore, overTime); NSLog(@"线程2开始"); dispatch_semaphore_signal(semaphore); }); } 123456789101112131415161718192021222324控制台输出: Thread-Lock[40569:993613] 线程1开始 Thread-Lock[40569:993613] 线程1结束 Thread-Lock[40569:993612] 线程2开始 12345//如果 overTime 改成 3 秒
控制台输出: Thread-Lock[40634:995921] 线程1开始 Thread-Lock[40634:995920] 线程2开始 Thread-Lock[40634:995921] 线程1结束 1234 -
pthread_mutex 与 pthread_mutex(recursive)
pthread 表示 POSIX thread,定义了一组跨平台的线程相关的 API,POSIX 互斥锁是一种超级易用的互斥锁,使用的时候:
- 只需要使用 pthread_mutex_init 初始化一个 pthread_mutex_t,
- pthread_mutex_lock 或者 pthread_mutex_trylock 来锁定 ,
- pthread_mutex_unlock 来解锁,
- 当使用完成后,记得调用 pthread_mutex_destroy 来销毁锁。
常用相关API:
pthread_mutex_init(pthread_mutex_t *restrict _Nonnull, const pthread_mutexattr_t *restrict _Nullable); pthread_mutex_lock(pthread_mutex_t * _Nonnull); pthread_mutex_trylock(pthread_mutex_t * _Nonnull); 123
pthread_mutex_unlock(pthread_mutex_t * _Nonnull);
pthread_mutex_destroy(pthread_mutex_t * _Nonnull);
用法:
```objectivec
//pthread_mutex
- (void)viewDidLoad {
[super viewDidLoad];
[self pthread_mutex];
}
- (void)pthread_mutex {
__block pthread_mutex_t cjlock;
pthread_mutex_init(&cjlock, NULL);
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
pthread_mutex_lock(&cjlock);
NSLog(@"线程1开始");
sleep(3);
NSLog(@"线程1结束");
pthread_mutex_unlock(&cjlock);
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
sleep(1);
pthread_mutex_lock(&cjlock);
NSLog(@"线程2");
pthread_mutex_unlock(&cjlock);
});
}
1234567891011121314151617181920212223242526272829303132
控制台输出:
2017-10-23 14:50:29.842180+0800 Thread-Lock[74478:1647362] 线程1开始
2017-10-23 14:50:32.846786+0800 Thread-Lock[74478:1647362] 线程1结束
2017-10-23 14:50:32.847001+0800 Thread-Lock[74478:1647359] 线程2
12345
由以上内容总结:
- 它的用法和 NSLock 的 lock unlock 用法一致,而它也有一个 pthread_mutex_trylock 方法,pthread_mutex_trylock 和 tryLock 的区别在于,tryLock 返回的是 YES 和 NO,pthread_mutex_trylock 加锁成功返回的是 0,失败返回的是错误提示码。
-
os_unfair_lock
之前苹果还有OSSpinLock自旋锁,这是执行效率最高的锁,不过在iOS10.0以后废弃了这种锁机制,使用os_unfair_lock替换,这个锁解决了优先级反转问题。
“低优先级线程拿到锁时,高优先级线程进入忙等(busy-wait)状态,消耗大量 CPU 时间,从而导致低优先级线程拿不到 CPU 时间,也就无法完成任务并释放锁。这种问题被称为优先级反转。"
YY大神说OSSpinLock不安全实际上就是因为这个原因,具体可以看他的文章。常用相关API:
// 初始化 os_unfair_lock_t unfairLock = &(OS_UNFAIR_LOCK_INIT); // 加锁 os_unfair_lock_lock(unfairLock); // 尝试加锁 BOOL b = os_unfair_lock_trylock(unfairLock); // 解锁 os_unfair_lock_unlock(unfairLock); os_unfair_lock 用法和 OSSpinLock 基本一直,就不一一列出了。 123456789
总结
应当针对不同的操作使用不同的锁,而不能一概而论哪种锁的加锁解锁速度快。
-
其实每一种锁基本上都是加锁、等待、解锁的步骤,理解了这三个步骤就可以帮你快速的学会各种锁的用法。
-
@synchronized 的效率最低,不过它的确用起来最方便,所以如果没什么性能瓶颈的话,可以选择使用 @synchronized。
-
当性能要求较高时候,可以使用 pthread_mutex 或者 dispath_semaphore,由于 OSSpinLock 不能很好的保证线程安全,而在只有在 iOS10 中才有 os_unfair_lock ,所以,前两个是比较好的选择。既可以保证速度,又可以保证线程安全。
-
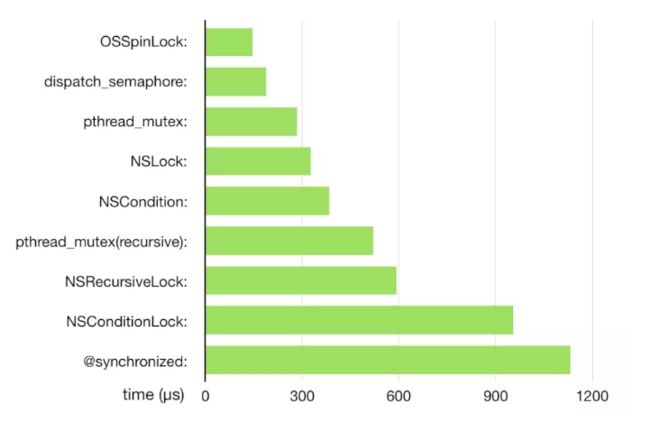
最后贴一张大神ibireme在iPhone6、iOS9对各种锁的性能测试图
参考博客:
- iOS多线程到底不安全在哪里?
- 浅谈iOS中的锁的介绍及使用