本文由中山大学人机物智能融合实验室(HCP Lab)特约供稿。全球计算机视觉三大顶会之一 CVPR 2019 (IEEE Conference on Computer Visionand Pattern Recognition) 于 6月 16~20日 在美国洛杉矶如期举办。
CVPR 作为计算机视觉三大顶级会议之一,一直以来都备受关注。被 CVPR 收录的论文更是代表了计算机视觉领域的最新发展方向和水平。在谷歌学术发表的2018年最新的学术期刊和会议影响力排名中,CVPR排名第20,这是计算机领域顶会第一次进入Top20的行列。

在论文方面,CVPR 2019 年共收到了 5165 篇有效提交论文,比去年 CVPR2018 增加了 56%,论文接收方面,本届大会共接收了 1300 论文,接收率接近 25.2%,据统计共有 288 篇 Oral 论文。
在本届CVPR大会上,中山大学人机物智能融合实验室(HCP Lab)共有12篇论文被收录,在国内研究组里属于顶尖水平。HCP Lab实力强潜力足势头猛,对学术上再创佳绩满怀信心。
以下我们将精选几篇论文展示给大家,欢迎感兴趣的朋友关注CVPR顶会交流小组阅读。
【01】
Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks
通过对抗元适应网络解决混合目标域适应
在大数据时代下,机器学习学家面临着日新月异的无标注数据更新和在这些新数据下进行模型再训练的问题。如何利用以前的标注数据(源域,source domain)对各种各样的无标注数据(目标域,target domain)进行知识迁移,也即所谓的域适应问题,成为学界以及工业界备受关注的研究热点。遗憾的是,目前对于域适应问题,大部分解决方案都基于目标域均由一个或多个显式目标域所组成(如图一a)。而事实上,多种真实应用场景如自动驾驶和云数据处理等,都会面临着多个目标域混合的域适应问题(如图一b)。在多个目标域混合下,每一个目标数据都可以来自其中一个子目标域,但来自于哪一个子域都是不可知的。因此如果直接使用一般的域适应算法去解决混合域适应问题,训练出来的迁移学习模型会忽略混合子域之间的域偏移(domain shift)。这会导致负迁移现象从而损害模型的效果。
为了解决混合目标域情况下面进行有效的域适应训练出有效的模型,我们提出了对抗元适应网络模型(Adversarial Meta-Adaptation Networks,AMEAN),如下图所示:
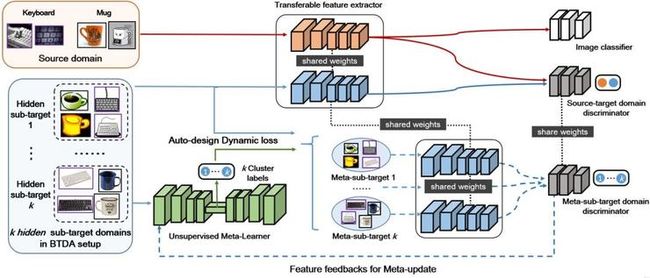
AMEAN模型有两个混合训练的迁移学习过程构建而成。第一部分启发于现有的域适应算法,也就是直接进行源域和混合目标域之间的迁移学习。这个过程可以将源域的类别信息有效迁移到目标域去,但无法消除多个子目标域之间的域偏移。目标子域之间的差异越大,那混合目标域造成的负迁移现象就会越明显。为了克服这个问题,我们构建了元子域适应(meta-sub-target domain adaptation)过程。因为在混合目标域的设定下,每个目标子域没有显式地给出,因此也没办法直接对他们的域偏移进行惩罚。作为代替,我们利用深度无监督聚类算法(Unsupervised Meta Learner)对混合目标域进行划分,将每一个聚类结果看作子目标域的替代。然后,利用对抗域适应的方法对这些子目标域和源目标域一起进行迁移学习。之后每隔一个迭代数间隔,我们利用在学习中的混合目标域迁移特征进行反馈,和混合目标域的数据一起重新更新聚类结果然后动态构建元子域适应过程中的对抗迁移学习关系和其损失函数。聚类过程与两个混合训练的迁移学习过程交替进行直到收敛。
我们的实验结果表明,混合目标域适应的确会为一般域适应算法造成各种各样的负迁移现象,同时我们的AMEAN模型能够有效地克服混合目标域适应带来的负迁移效果,从而取得目前在该新问题下的最佳性能。但作为一个新的迁移学习问题,混合目标域适应远远没去到接近解决的地步。
原文代码链接:https://github.com/zjy526223908/BTDA
【02】
Knowledge-Embedded Routing Network for Scene Graph Generation
面向场景图生成的知识嵌入路由网络模型
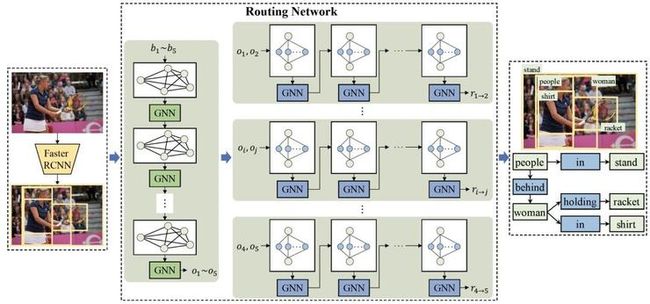
场景图生成不仅仅需要定位和识别图像中物体的位置和类别,还需要进一步推理不同物体之间的视觉关系。然而,现实场景中物体关系的样本分布是非常不均衡的,现有的方法对于样本较多的关系,可以取得较好的结果,但对于样本较为缺乏的关系,其预测结果则明显下降。场景中目标物体和他们可能的视觉关系之间关联的先验知识和图传播网络结合,约束目标物体视觉关系的预测空间,从而降低对样本的依赖。因此,我们提出了知识嵌入的路由网络模型,在统计先验知识的约束下探索目标物体和他们可能的视觉关系的作用,以及挖掘场景中的上下文信息,并应用场景图生成任务。
该模型首先利用物体共存的先验知识构建关联所有物体区域的图,并引入一个图传播网络传播节点信息,学习具有上下文信息的特征以辅助更好地预测物体类别。对于给定类别标签的目标物体,该模型进一步构建他们和可能的视觉关系的统计关联的图,并引入另一个图传播网络探索两者的交互作用,以最终预测目标物体的视觉关系。
相比于现有的方法,本文的模型通过引入先验知识隐式地约束目标物体可能的预测空间,有效地解决不同关系分布不均衡的问题。在大规模场景图生成的数据集Visual Genome上进行大量的实验表明,本文的框架相比于现有的方法取得更好的效果。
论文代码链接:https://github.com/HCPLab-SYSU/KERN
【03】
Adaptively Connected Neural Networks
自适应连接神经网络
我们引入一种新的自适应连接神经网络(ACNet),从两方面改进了传统的卷积神经网络(CNN)。一是ACNet可以自适应地决定神经元连接属于全局连接抑或局部连接,从而进行自适应局部推断或全局推断。我们可以证明,现有的卷积神经网络(CNN)、经典的多层感知器(MLP)和最近提出的非局域网络(NLN)都是ACNet的特例。二是ACNet不仅可以适用于传统的欧氏数据(例如图像、音频等),也可以适用于非欧氏数据(graph data)。实验表明,ACNet在ImageNet-1K/CIFAR图像分类、COCO 2017目标检测和分割、CUHK03行人重识别以及CORA文档分类等任务中达到了State-of-the-art效果。
具体来说,研究人员首先使用自变换操作(Self Trans模块)提取像素级特征、卷积操作(CN N 模块)提取局部特征、多层感知器操作(MLP 模块)提取全局特征,然后使用自适应连接神经网络(ACNET模块)融合三者,得到局部与全局自适应的特征,这样ACNet既有自变换操作和卷积操作所具有的局部推断能力,又具有多层感知器操作所具有的全局推断能力。
代码和预训练模型下载:
https://github.com/wanggrun/Adaptively-Connected-Neural-Networks/blob/master/README.md
【04】
"Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation"
基于结构表征的弱监督3D人体姿态估计
3D 人体姿态估计是计算机视觉领域的一个热门研究课题,旨在从单张彩色图像中恢复出精确的 3D 人体姿态。作为三维人体结构建模的基础,3D 人体姿态估计在动作识别、视频分析、人机交互、虚拟现实和自动驾驶等领域中都起到非常重要的作用。近年来,3D 人体姿态估计取得了较大的发展。但是,相关数据和模型方法只局限于简单的室内场景,极大地限制了该研究问题的探索。主要原因在于,室外复杂场景的 3D 人体数据集的采集十分困难,受限于光学动作采集系统对场地的严格要求,只能捕捉室内场景下的简单人体动作。当测试数据中出现高难度的人体姿态、扰动较大的拍摄视角、各式各样的人物外观以及复杂的拍摄场景时,3D 人体姿态估计模型的泛化性往往较差。
为此本文提出一种解决方法,拟从从大量多视角图像中提取额外的 3D 人体结构信息,使用额外信息辅助单张图像的 3D 人体姿态估计任务。在提取额外信息的过程中,只使用带有 2D 标注的多视角图像作为训练集,选取编解码器作为主干网络,训练编解码器实现不同视角下 2D 人体信息的相互转换。为了让转换仅仅基于人体结构,选取 2D人体骨架作为本文方法的 2D 人体信息,而没有使用原始图像。进一步加入了对 3D 结构的一致性约束,使得抽取到的额外信息的 3D 结构更加稳定。因为抽取的额外信息蕴含了人体的 3D 结构信息,所以将它映射到 3D 关键点坐标将会比直接利用 2D 图像或者 2D 坐标更为容易。继而验证了仅仅使用简单的两层线性全连接层,可以从额外信息中解码出相对合理的 3D 人体姿态。
经过实验验证,本文提取的额外信息可以作为对 3D 人体姿态信息的补充,简单灵活的融合到现有的 3D 人体姿态估计方法中,得到更加准确的预测结果。在标准的大型3D 人体数据库 Human3.6M 上,本文提取的额外信息对三种不同的 3D 人体姿态估计方法都有较大提升。对于现有最好的开源 3D 人体姿态估计方法,在标准 的数据划分下使用评估指标 MPJPE,本文提出的方法仍然有 7% 的提升,在现有的方法中达到最好的效果。
【05】
Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
通用的自适应全局推理网络及在大规模目标检测的应用
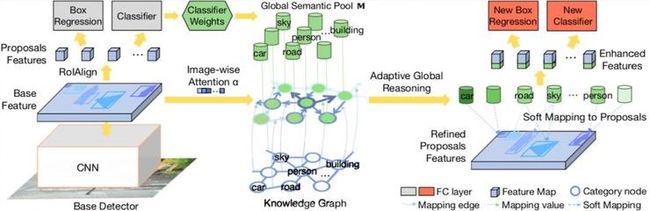
随着深度学习的发展,大规模目标检测问题逐渐成为人们关注的热点,通过这一计算机视觉中的基础技术,软硬件应用产品可以深度定位图片中的物体位置以及类别,并用于新零售、通用多物品识别、自动驾驶等场景。与普通检测问题不同的是,大规模目标检测意味着同时定位并识别数千个类别,面临严重的长尾效应,目标间相互遮挡,以及更多模糊不清的目标。然而主流的目标检测方法通常独立地识别每个区域,并忽略场景中目标之间的关键语义相关性,导致它们面对复杂的大规模数据时检测性能大幅下降。而人类即使看到复杂场景仍能够准确理解并识别目标,因为人类了解很多关联的知识域的常识知识,并且能够借助知识进行学习和推理,这正是当前的检测系统所缺乏的能力。因此,关键问题是如何赋予检测系统视觉推理能力,来模仿人类推理过程。
本文研究了知识导向的图像级的自适应全局推理方法,提出了通用的自适应全局推理模型(Reasoning-RCNN),通过知识提高了对所有目标区域的自适应全局推理能力。该方法不是直接在单一图像上传播视觉特征,而是全局地演化所有类别的高级语义表示,以避免图像中的噪声或不良的视觉特征带来的影响。具体地,基于基础检测网络的特征表示,所提出的网络首先通过收集上层分类层的权重来生成每个类别的全局语义池(Global Semantic Pool),然后通过挑选全局语义池中的不同语义上下文来自适应地增强每个目标区域的特征。本文提出的Reasoning-RCNN不是从可能存在噪声的所有类别的语义信息中传播信息,而是能自动发现与特征演化最相关的类别。
经过实验验证,本文提出的方法是轻量级的,通用的,可扩展的,并且能够融合知识赋予任何检测网络视觉推理的能力。在不引入过多计算代价的前提下,本文提出的方法在大规模检测数据集VisualGenome(1000类/3000类),ADE(445类)和通用检测数据集MS COCO(80类),PASCAL VOC(20类)上均远优于其他现有的先进检测方法。
【06】
Spatial-aware Graph Relation Network for Large-scale Object Detection
空间感知的图关系网络及在大规模目标检测的应用
大规模目标检测框架需要具备同时定位并识别成千上万个具有复杂语义和空间关系的目标,伴随着待处理的类别数越多,面临越多的小目标、越严重的类别之间目标数不平衡、目标之间相互遮挡等问题。众所周知,目标之间复杂的语义和空间关系有助于提高检测精度。而当前的多数研究工作通常单独地对目标进行定位和识别,当这些方法面对大规模类别数据集时,性能会大幅下降。因此本文提出一个空间感知图关系网络(SGRN)框架来主动发现并结合关键的语义和相对空间关系来对每个对象进行推理。我们的方法考虑了目标之间相对位置布局和相互作用,我们提出的SGRN可以很容易地嵌入到任何现存的检测方法中,并提高它们的检测性能。
在没有任何外部知识的情况下,如何正确编码检测系统中对象之间的高阶关系?如何利用对象间的伴随关系和相对位置之间的信息进行更好的推理?这些问题是当今大规模目标检测框架面临的主要挑战。近期,一些工作也尝试通过构建目标之间的知识图来增强检测效果,图1a使用人工设计的知识构建一个类类之间的图。然而,这种方法很大程度上依赖于来自广义的类别视觉的属性标注和语义关系。此外,由于语义和视觉语境之间的差异,某些空间关系可能会被忽略,固定图也无法适应全部的图像。另一些方法试图从的视觉特征中隐式地学习目标之间的全连接图。但是,完全连接的关系由于从无关对象和背景中合并了冗余和不必要的关系而变得低效和嘈杂。因此,本文的工作目标是设计一个基于图卷积神经网络的检测框架,它可以同时利用语义和空间关系,直接从训练集中有效地学习到可解释的稀疏图结构,并根据学到的图结构进行推理和特征传播,增强小目标、罕见类和模糊遮挡目标的特征相应提高检测结果。
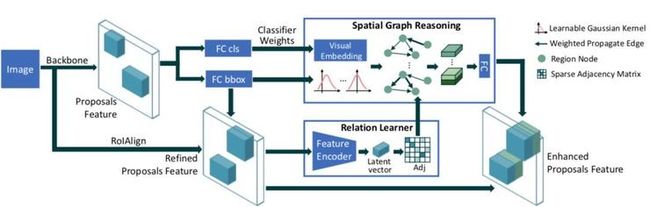
本文提出的SGRN框架由两个模块组成:一个稀疏关系图学习模块(Relation Learner)和一个空间感知图推理模块(Spatial Graph Reasoning)。关系图学习模块首先从视觉特征中学习一个稀疏邻接矩阵,它保持了最相关的T个连接关系。然后,收集前一个分类器的权重,并将其映射到每个目标上,从而成为每个目标的视觉向量。目标之间的相对空间信息(距离、角度)被用来学习高斯核参数,以确定图形卷积的模式。在空间感知图形推理模块中,根据稀疏邻接矩阵和高斯核对不同区域的视觉嵌入进行演化和传播。空间图推理模块的输出与原始区域特征相连接,以改进分类和定位。
【07】
Graphonomy: Universal Human Parsing via Graph Transfer Learning
面向通用人体解析的图迁移模型
人类的视觉系统,具有在简单看一眼人物图像的情况下,完成对图像中人物整体理解的能力。例如,人们只需看一眼图像,就能够把图中人物和背景区分开来,能够知道图中人物的姿势,也能够识别出图中人物的穿着打扮。尽管如此,最近对人物图像理解的研究都致力于为每个单独的应用开发许多种高度独立的特定的模型,譬如人物前景分割任务,粗糙的衣服分割任务和精细的人物部位或服饰解析任务等。这些经过高度调整的网络牺牲了模型的泛化能力,仅仅通过过度拟合来适应不同的数据集和不一致的标注粒度,而忽略了存在于所有人物图像中潜在的人体结构特征和共同的内在语义信息。将在一个数据集上训练的模型直接拿到另一个相关数据集上重新微调是非常困难的事情,因为这需要冗余而繁重的数据标注和大量的计算资源来重新训练每个特定的模型。为了解决这些现实的挑战并避免为相关任务训练冗余的模型,我们做出了一个创新性的尝试,研究面向通用人体解析的问题,通过单个模型来同时处理不同的、从粗粒度到细粒度的人体解析任务,如下图所示。
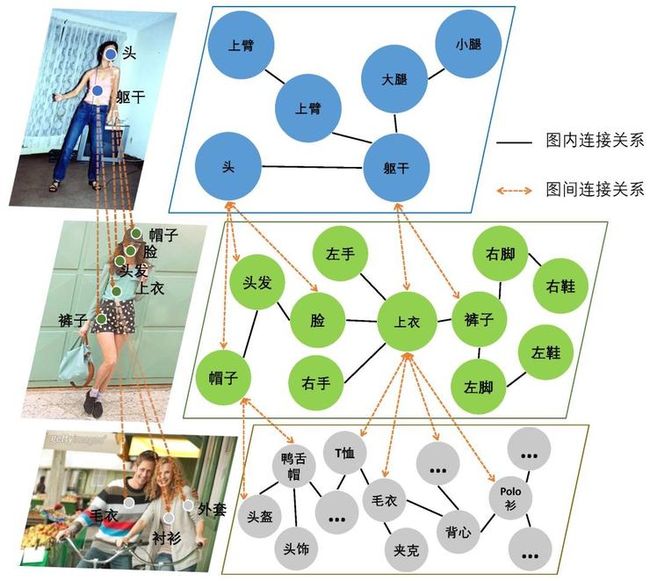
设计一个通用人体解析模型的关键因素是在不同的人体解析任务之间进行准确的迁移学习和知识集成,因为不同数据集之间的标签差异性很大程度上阻碍了模型和数据的统一。为了实现这一目标,我们提出了一个图迁移模型,将人类知识和标签分类法显式地归纳为图表达学习,并且嵌入到卷积神经网络中去。我们的图迁移模型通过图迁移学习来建模多个领域的全局和通用的语义一致性,以此来解决多层次的人体解析任务,并通过信息传播使他们能够相互促进。
我们的图迁移模型集成了两个相互协作的模块,用于图迁移学习,如下图所示。首先,我们提出了一个图内推理模块来逐步改善图结构中的图表达,其中每个图节点表示数据集中的一个语义部位区域。此外,我们还构建了一个图间迁移模块,专注于将相关语义从一个领域的图表达中提取到另一个领域的图表达中去,从而桥接了来自不同数据集的语义标签,更好地利用了不同粒度的标注信息。
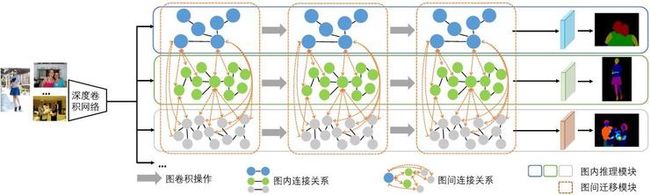
我们在三个人体解析数据集上进行了大量的实验,这些数据集包含了不同种类的语义部位和服饰标签。实验结果表明,通过图内推理模块和图间迁移模块的信息传播,我们的图迁移模型能够关联和提取由不同数据集构建的高级的语义图表达,有效地解决了多层次的通用人体解析任务。
【08】
ClusterNet: Deep Hierarchical Cluster Network with Rigorously Rotation-Invariant Representation for Point Cloud Analysis
一种基于严格旋转不变性的点云表达以及深度层次类簇网络的点云分析方法
在三维世界中,旋转变换是一种十分自然、常见的现象,但是它对于三维物体识别也带来了很大的挑战。理论上,因为SO(3)群是一个无穷集合,同一个三维物体在不同姿态下具有不同的“克隆”。对于人类而言,我们能很轻易地将这些“克隆”判断为同一个物体;但是对于机器学习模型而言,这些克隆却是完全不同的输入数据,这会导致输入空间非常庞大。
为了缓解该问题,前人做了许多尝试。①一个最简单的办法是提升模型容量并且对训练数据集进行旋转增强,这种方法使得训练阶段的计算成本大大增加,而且也无法从根本上保证模型具有旋转不变性。对于同一个物体的某种姿态,模型可能就识别不准确了。②利用空间变换网络(Spatial transformer network)来对输入数据进行校正,这种方法能从一定程度提升模型的旋转鲁棒性,但同样需要增强训练集,而且也缺乏理论上的保证。③利用旋转等变性网络(rotation-equivariant network)来消除旋转对于模型的影响。它设计了一种旋转等变的卷积操作,相当于给神经网络加入了一种旋转等变的先验知识,但是如果对于神经网络的每一层都施加旋转等变的约束,我们很难保证这些约束不会影响模型的容量。
与旋转等变性网络不同,我们提出了一种新的方案:直接对每一个三维物体的点云建立一个旋转不变的统一的表达(简称为RRI表达),直接从源头解决了旋转所带来的问题,将原本冗余的输入空间大大削减。我们不仅从理论上证明了这种表达具有严格旋转不变性,而且在较弱的条件下还具有信息无损性,即:当我们知道了一个点云的RRI表达,不管这个点云如何旋转,只要给定旋转后点云中的一个点以及另一个不共线的k近邻点的坐标,那么我们就可以重建这个旋转后的点云。RRI表达的具体形式还具有直观的几何意义。
我们还提出了一个新的网络结构ClusterNet,架构如图2所示。它首先会对输入点云进行层次聚类,得到关于该点云几何结构的层次聚类树。然后我们沿着这棵层次聚类树去指导特征的聚合,自底向上将较小类簇的特征聚合为较大类簇的特征,直到获得整个点云的特征。
在旋转鲁棒性实验中,我们提出的RRI表达与ClusterNet结合的方法在旋转鲁棒性上取得了最优的表现,并且现存的基于点云的分类网络采用我们的RRI表达作为输入后,在旋转鲁棒性上也有明显的提升。
【09】
Layout-graph Reasoning for Fashion Landmark Detection
一种基于堆叠式层级布局知识推理的服装关键点定位方法
近来在预测定位关键点的方面有了许多的研究方法。一种直接的方法是通过DCNNs,采用端到端的方式进行建模关键点的位置信息,如图1(a)所示。虽然这种方法得益于深度卷积网络的深层建模能力,但缺乏可解释性,对数据依赖敏感,同时在一些具有复杂背景的场景下表现差强人意。另一种引入语法建模的方法是通过对服装关键点之间进行语法建模,比如建立领口点的对称语法,然后利用该语法形成的约束进行引导网络学习,如图1(b)所示。这种引入外部自定义的语法进行建模的方法可以有效提升定位关键点的性能并增强了网络的可解释性,但是该方法没有引入知识来建模点的空间上下文语义关联,比如袖子点属于上半身语义关联。缺乏这种关联容易导致在一些复杂模糊的场景下,上下身的服装关键点预测混乱。同时目前的方法并没有对卷积特征图和图节点特征建模一种有效的转换方法,让知识图谱中节点的知识推理操作无法有效地和卷积网络进行无缝衔接,从而无法达到协同训练的目的。
为了克服现有技术的不足,同时受益于人类在认识事物的过程中,对事物进行归属分类的思想,我们首次提出了一种基于堆叠式层级布局知识推理的服装关键点定位方法,整体框架如图2所示。整体框架主要包括一个基础卷积网络和一系列的层级布局知识推理模块(LGR layer)。其中每个层级布局知识推理模块都包含三个子模块:图-点子模块(Map-to-Node)、层级推理子模块(Layout-graph Reasoning Module)和点-图子模块(Node-to-Map)。每个层级推理子模块包含图节点聚类操作、图节点反卷积操作和图节点信息传播操作。本方法首先利用基础卷积网络对输入的图像提取卷积特征图,再利用图-点子模块将卷积特征图转换为图节点特征;再利用服装关键点空间布局关系的信息结合图节点特征,输入到层级推理子模块实现层级布局知识推理,包括建模各个叶子节点的布局关系,各个中间节点的布局关系等,如图3所示,最终输出得到进化增强的叶子节点特征;最后通过点-图子模块将层级推理子模块的输出节点转换为卷积特征图;再通过后处理将卷积特征图转换为特征定位图,预测出最终的服装关键点位置。
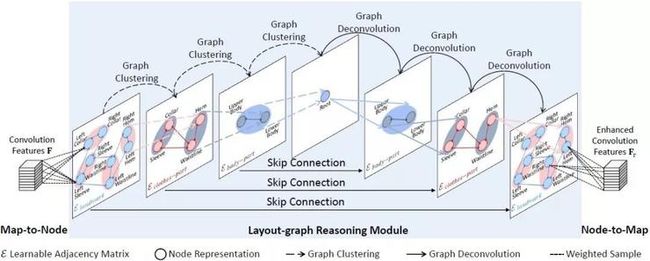
层级布局知识推理模块(LGR layer)
本方法第一次提出层级布局知识推理的方法,并将该方法首次应用到通用服装关键点定位的任务中。相比于最近的基于多阶段预测、空间变换的注意力机制以及利用语法模型约束关键点定位的服装关键点定位方法,我们提出的方法不仅拥有更高的定位精度和可解释性,而且提供了一种将层级知识图谱引入卷积网络进行层级推理的机制。我们的方法在目前已有的两个大型fashion landmark数据集上进行测试并达到state-of-the-art的效果。
附录
1. "Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks”, Ziliang Chen, Jingyu Zhuang, Xiaodan Liang and Liang Lin Proc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
2. "Knowledge-Embedded Routing Network for Scene Graph Generation", Tianshui Chen, Weihao Yu, RIquan Chen, Liang LinProc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
3. “Adaptively Connected Neural Networks”, Guangrun Wang, Keze Wang, and Liang Lin*, Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
4. "Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation", Xipeng Chen, Kwan-Yee Lin, Wentao Liu, Chen Qian and Liang Lin, Proc. of IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2019
5. "Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection", Hang Xu*, ChenHan Jiang*, Xiaodan Liang, Liang Lin, Zhenguo Li, Proc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
6. "Spatial-aware Graph Relation Network for Large-scale Object Detection", Hang Xu*, ChenHan Jiang*, Xiaodan Liang, Zhenguo Li, Proc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
7. Graphonomy: Universal Human Parsing via Graph Transfer Learning,Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang, Liang Lin,Proc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
8.ClusterNet: Deep Hierarchical Cluster Network with Rigorously Rotation-Invariant Representation for Point Cloud Analysis, Chao Chen, Guanbin Li, Ruijia Xu, Tianshui Chen, Meng Wang, Liang Lin, Proc. of IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2019.
9. “Layout-Graph Reasoning for Fashion Landmark Detection”,Weijiang Yu, Xiaodan Liang, Ke Gong, Chenhan Jiang, Nong Xiao, Liang Lin; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
10. “Cross-Modal Relationship Inference for Grounding Referring Expressions”,Sibei Yang, Guanbin Li, Yizhou Yu; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
11. “Learning Personalized Modular Network Guided by Structured Knowledge”,Xiaodan Liang; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
12. “Rethinking Knowledge Graph Propagation for Zero-Shot Learning”,Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, Eric P. Xing; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
附录:中山大学HCP人机物智能融合实验室
“中山大学HCP人机物智能融合实验室“依托于中山大学数据科学与计算机学院,围绕“人工智能原创和前沿技术”布局研究方向与课题,并与产业界开展广泛合作,输出大量原创技术及孵化多个创业团队。在感知计算与智能学习、机器人与嵌入式系统、人机协同技术、大数据挖掘与分析等领域开展研究,以“攀学术高峰、踏应用实地”为工作理念。实验室目前有教授1名,副教授4名,特聘研究员3名,工程师3名。
实验室承担或者已完成各级科研项目40余项,共获得科研经费超过数千万元。科研团队在顶级国际学术期刊与会议上发表论文200余篇,包括在IEEE/ACM Trans汇刊发表论文60余篇,在CVPR/ICCV/NIPS/Multimedia/AAAI/IJCAI等顶级会议发表论文100余篇,获得NPAR 2010 Best Paper Award, ACM SIG CHI Best Paper Award Honorable Mention, ICME 2014 Best Student Paper, The World’s FIRST 10K Best Paper Diamond Award by ICME 2017,Pattern Recognition Best Paper Award等奖励。
今日博客推荐:300篇 CVPR 2019 Oral 论文精选汇总,值得一看的 CV 论文都在这里(持续更新中)
本篇论文精华帖社长将会持续更新,每天不间断推荐高价值论文,并且社长已经把相关论文下载好了,下载链接附在每个板块论文下方。
同时社长希望可爱的你们能够向 AI 研习社推荐自己的论文,自荐论文的用户有机会获得 AI 研习社赠送的大礼一份!
点击链接查看:https://ai.yanxishe.com/page/postDetail/11408