第七章数据压缩技术
第七章 数据压缩技术
转自:http://www.dataguru.cn/article-3856-1.html
本章导读
前面的章节已经介绍了海量数据的存储、查询、分区、容错等技术,这些技术对于海量数据的处理是必不可少的,但要进一步优化海量数据的管理还要用到一些其他的技术,本章主要介绍其中的数据压缩技术。
数据压缩是指在不丢失信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率的一种技术,或者指按照一定的算法对数据进行重新组织,减少数据的冗余和存储的空间。数据压缩包括有损压缩和无损压缩。本章首先介绍数据压缩的基本原理以及传统的压缩算法,然后提出海量数据带来的3V挑战,最后介绍实际应用中的压缩技术,包括Oracle压缩技术、Google压缩技术以及Hadoop压缩技术。
本章要点
-
数据压缩原理
-
传统压缩算法(包括LZ77算法和霍夫曼算法)
-
海量数据带来的3V挑战
-
Oracle压缩技术
-
Google压缩技术
-
Hadoop压缩技术
7.1 数据压缩原理
随着科技的发展,人类社会也在发生着翻天覆地的变化,尤其是计算机的出现,更是将人类带入了前所未有的信息时代。从电报电话,到广播电视,再到手机和各种移动终端,人们的生活越来越方便,但同时也带来了一个不容忽视的问题——信息爆炸!如何管理这些海量数据,如何从中找到有用的信息,这些问题都是人类从未遇到过的。其中最基本的一个问题是:如何把这些信息存储起来?如果这个问题解决不了,其他的问题更是无从入手了。
数据压缩的理论基础是信息论和率失真理论,克劳德•香农在20世纪40年代末期及50年代早期发表了这方面的基础性论文。密码学与编码理论也是与数据压缩密切相关的学科,数据压缩的思想与统计推断也有很深的渊源。以此为基础,人们对于数据压缩技术的研究已经有很长时间。图7-1给出了一个例子。

图7-1中上部的文本如果交给人来看,得出的结论恐怕只能是有很多A。但如果交给计算机来处理就可以得到更多的信息,也就是能准确地求出A的个数。更重要的是,图7-1中下面的内容表达的含义和上面的一样,但是却用了更少的存储空间。
7.1.1 数据压缩的定义
数据压缩是指在不丢失信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率的一种技术,或者指按照一定的算法对数据进行重新组织,减少数据的冗余和存储的空间。
数据压缩其实就是一个数据编码的过程,可以理解为用不同的语言表达同样的含义,只不过有些语言很简练,而有些却很繁琐。我们的目的就是通过数据编码用最简洁的方式表达数据包含的信息,更确切地说是用最少的空间存储最多的信息。
数据编码是一个从源文件到编码文件的映射过程。源文件的内容有多种形式(文本、图像、声音),但它们在计算机中都是以二进制的形式存储的,只不过具体的二进制表示方法不同。了解这一点才能更好地学习数据压缩原理,如表7-1所示的例子。
表7-1 信息的二进制表示
| 源 信 息 |
二进制信息 |
| ab(字符类型) |
11000011100010 |
| 12(整型) |
1100 |
从字面上看,ab和12的长度一样,但正因为它们的数据类型不同,在计算机中存储占用的空间也不同。从计算机的角度考虑问题,能更好地理解压缩的原理和巧妙之处。
7.1.2 数据为什么可以压缩
数据可以被压缩,是因为数据中往往存在着大量的冗余信息。如英语中就有26个字母,由此构成单词、短语等语义单位,然后再加上一些标点符号构成文章。一篇英语文章中会有大量重复的字母、单词或短语,如果能找到一种压缩算法将一篇英语文章压缩成26个字母和一些位置信息的组合,那么应该就能达到最大程度的压缩。我们姑且不谈是否存在这样的算法,只要理解减少信息冗余是压缩的本质。
在实际应用中,多媒体信息的压缩是最常见的。事实上,多媒体信息存在许多数据冗余。例如,一幅图像中的建筑背景、蓝天和绿地,其中许多像素是相同的,如果逐点存储,就会浪费许多空间,称为空间冗余。又如,在电视和动画里相邻的运动图像序列中,只有运动物体有少许变化,仅存储差异部分即可,称为时间冗余。此外还有结构冗余、视觉冗余等,这就为数据压缩提供了条件。
7.1.3 数据压缩分类
数据压缩的方式有很多,一般来说可以分为无损压缩和有损压缩。
无损压缩是指使用压缩后的数据进行解压缩,得到的数据与原来的数据完全相同;无损压缩用于要求重构的信号与原始信号完全一致的场合。一个很常见的例子是磁盘文件的压缩。根据目前的技术水平,无损压缩算法一般可以把普通文件的数据压缩到原来的1/2~1/4。一些常用的无损压缩算法有霍夫曼(Huffman)算法和LZW(Lenpel-Ziv & Welch)压缩算法。
有损压缩是指使用压缩后的数据进行解压缩,得到的数据与原来的数据有所不同,但不影响人对原始资料表达的信息的理解。有损压缩适用于重构信号不一定非要和原始信号完全相同的场合。例如,图像和声音的压缩就可以采用有损压缩,因为其中包含的一些数据往往超过我们的视觉系统和听觉系统所能接收的范围,丢掉一些也不至于使人对声音或者图像所表达的意思产生误解,但可大大提高压缩比。
7.2 传统压缩技术[1]
常见的无损压缩算法有行程长度(run-length)编码、字典编码(LZ系列编码)、霍夫曼编码、算术编码等;常见的有损压缩算法有离散余弦变换、分形压缩、小波压缩、线性预测编码等。在这里我们仅介绍无损压缩中的两种经典算法:霍夫曼编码和LZ77编码。
7.2.1 霍夫曼编码
根据ASCII码的规定,我们用8比特代表一个字符,但是如果提前知道了文件中各个字符出现的频率,就可以对这些字符重新编码。对于出现频率高的字符用较少的比特表示;对于频率较低的字符用较多的比特表示。由于使用频率高的字符为字符集的子集,从总体上来说,还是减少了总共需要的比特数,达到了压缩的目的,这正是霍夫曼编码的思想。
使用霍夫曼编码进行压缩,首先要扫描整个文件,统计每个字符的频率,然后根据频率建立霍夫曼树,由霍夫曼树得到每个字符的编码。由于频率高的字符在霍夫曼树中离根更近,它们的霍夫曼编码长度更短;相反,频率低的字符的编码更长。最后,用霍夫曼编码替换原文件中的字符。
建立霍夫曼树的步骤如下。
(1)将所有的字符看成仅有一个节点的树,节点的值是字符出现的频率。
(2)从所有树中找出值最小的两棵树,并为它们建立一个父节点,从而构成一棵新的树,父节点的值为两棵子树的根节点值的和。
(3)重复步骤(2),直到得到最后一棵树,这就是我们需要的霍夫曼树。
有了霍夫曼树就该考虑如何得到霍夫曼编码。霍夫曼树是一颗二叉树,所有的叶子节点就是需要编码的字符。我们在霍夫曼树中所有父节点到左子树的路径上标0,到右子树的路径上标1。对于每个叶子节点,从根节点到它的路径就是一个0和1构成的序列,这就是叶子节点字符的霍夫曼编码。
显然,对于出现次数多的字符,得到的霍夫曼编码较短,出现次数少的字符,编码较长,因此霍夫曼编码是一种变长编码。对于变长编码,在解码的时候会遇到如下问题:比如a的编码是000,b的编码是0001,c的编码是1,那么当遇到0001时,无法区分是ac还是b。出现这个问题的原因在于a的编码是b的编码的前缀。但霍夫曼编码不会存在这个问题,因为霍夫曼树中从根节点到一个叶子节点的路径不可能是到另一个叶子节点路径的前缀,所以一个霍夫曼编码不可能是另一个霍夫曼编码的前缀。我们称霍夫曼编码是一种前缀编码。
7.2.2 LZ77算法
LZ77算法是一种词典编码,它用的词典就是前面经过编码的信息序列。编码器利用一个滑动窗口查询输入的文本信息,如图7-2所示。

图7-2 滑动窗口
滑动窗口包括两部分:查询缓冲区和预见缓冲区。查询缓冲区包含了最近刚经过编码的序列,预见缓冲区包含接下来需要编码的序列。在图7-2中的查询缓冲区包含了8个字符,预见缓冲区包含了7个字符。实际应用时,缓冲区的大小要比这个大得多,在这里只是为了方便说明而设置小一点。
为了对预见缓冲区中的序列进行编码,编码器在查询缓冲区中从后往前移动一个匹配指针,直到这个指针指向与预见缓冲区中第一个字符匹配的字符为止。从预见缓冲区到匹配指针之间的距离称为偏移量,记作offset。接下来,编码器会继续检查匹配指针后面的连续字符是否与预见缓冲区中的连续字符相匹配。查询缓冲区和预见缓冲区中最长的匹配字符串长度称作匹配长度,记作length。编码器要查找最长的匹配字符串,当编码器找到这个最长匹配串时,会用一个三元组对它进行编码。三元组中的o代表offset,l代表length,c代表预见缓冲区中最长匹配串后的第一个不匹配字符。例如,在图7-2中查询指针指向了最长匹配串的开头,offset等于7,匹配长度为4,预见缓冲区中的第一个不匹配字符为r。设置第三个元素c的原因是为了便于处理查询缓冲区和预见缓冲区中没有匹配字符串的情形。这种情况下,三元组中的offset和length都被设置为0,c被设置为不匹配字符本身。
如果设查询缓冲区的大小为S,窗口(包括查询缓冲区和预见缓冲区)的大小为W,源文件中的字符集大小为A,那么用定长的三元组进行编码需要的比特数是[log2S]+[log2W]+[log2A],其中[]表示上取整。注意,第二项是[log2W]而不是[log2S],因为匹配长度可能会超出查询缓冲区,这种情况将在下面例子中说明。
在下面的例子中,我们将会考虑如下编码中可能遇到的三种情形。
(1)没有匹配字符。
(2)有一个匹配字符。
(3)匹配字符串超出了查询缓冲区的范围。
例如编码序列如下:
... cabracadabrarrarrad ...
假设窗口的大小为13,那么预见缓冲区的大小为6,当前状态如图7-3所示。

图7-3 窗口缓冲区的内容
预见缓冲区中包含了dabrar。我们在查询缓冲区中查找d的匹配字符,但是没有找到,所以输出<0, 0, C(d)>。前两个元素表示没有匹配字符,第三个元素C(d)代表第一个d的编码。
下面,我们继续编码的过程。因为前面对一个字符d进行了编码,所以把窗口向后移动一个字符。现在缓冲区中的情况如图7-4所示。

图7-4 窗口向后移动一个字符
预见缓冲区中包含字符串abrarr。从当前位置往前在查找缓冲区中查找匹配字符,在偏移位置为2的地方找到了一个匹配的a。这个匹配字符串的长度为1。再往前查找,我们又在偏移位置为4的地方找到另一个匹配的a,这个匹配字符串的长度仍然是1。继续向前查找,我们在偏移位置为7的地方找到了第三个匹配的a,但这次匹配字符串的长度为4(见图7-5),我们找到了匹配最长的字符串。于是,我们用三元组<7, 4, C(r)>代替字符串abra,并且将窗口向后移动5个字符。

图7-5 寻找最长匹配字符串
现在的窗口中包含如图7-6所示的内容。

图7-6 匹配字符可以跨过查找缓冲区
预见缓冲区中包含字符串rarrad,向前寻找匹配字符串。第一个匹配字符串的偏移位置是1,长度为1;第二个匹配字符串偏移位置是3,它的长度貌似是3,但实际上我们可以越过查找缓冲区,将重复字符串扩展到预见缓冲区,这一点前面已经提到了。所以这里重复字符串的长度为5,而不是3。
这么做是可行的,通过下面解码的过程可以得到证实。假设已经解压完成的字符串为cabraca,并且我们扫描到了三元组<0, 0, C(d)>,<7, 4, C(r)>,<3, 5, C(d)>。第一个三元组很好解码,它没有和已经解压的字符串重复的字符串,并且下一个字符为d。现在得到的字符串为cabracad。第二个三元组的第一个元素说明了重复字符串的偏移位置为7,于是把指针向前移动7个字符,第二个元素说明重复长度为4。于是连续输出后面的4个字符。具体解码过程如图7-7所示。

图7-7 LZ77解码过程
最后,让我们看看第三个三元组<3, 5, C(d)>是怎样解码的。根据第一个元素我们把指针向前移动3个字符,然后开始重复输出。前三个重复的字符是rar,复制指针继续向后移动,如图7-8所示,输出刚复制过的第一个字符r,同样再输出第一个复制过的字符a。这样一来,虽然在开始时只是复制了3个字符,但是最终我们解码出了5个字符。注意,匹配字符串必须起始于查找缓冲区,但是可以延伸到预见缓冲区。事实上,如果预见缓冲区中的最后一个字符是r而不是d,即后面跟着一连串重复的rar,那么整个rar重复序列可以用一个三元组进行编码压缩。

图7-8 LZ77解码过程
正如我们看到的,LZ77模式是一个非常简单的自适应模式,它不要求知道源文件的任何信息,并且几乎也不需要基于源文件的字符集。
7.3 海量数据带来的3V挑战
谈论海量数据,其实根本不用PB(Petabyte)级的数据,有10TB就足够让人头疼了,因为海量数据的含义不仅仅体现在“量”上。繁多的数据种类和数据的增长速度同样给IT界带来前所未有的挑战。数量、速度、多样是当前海量数据的3V挑战[2]。
1.数量(Volume)
现如今是一个信息爆炸时代,信息量正在以指数级增长,如何有效存储和管理这些数据?也许你会说随着硬盘容量的增长和单位存储成本的降低,这些问题将会得到解决。但是随着信息量的不断增长,成本还是在不断增加。数据压缩对于海量信息管理来说仍然是降低存储成本的有效手段。
2.速度(Velocity)
对于信息管理来说,不单单要降低存储成本,还要从海量数据中快速挖掘出有价值的信息。这里的速度指的是对数据进行有效分析的速度。其实有很多应用场合都是需要对数据进行实时分析的,或者至少是需要在短时间内完成的。比如射频识别(RFID)传感数据和GPS空间数据都要求有很高的时效性。那么如何从海量数据中快速分析出有效数据呢?数据压缩是不可或缺的一个环节,即通过某种合理的方式将数据压缩,从而减小数据量,然后在压缩后的数据中寻求需要的信息。在实际的应用场景中往往借助具有压缩功能的列存储数据库完成对数据的存储和分析。
3.多样(Variety)
数据多样性指的是现今出现的非结构化和半结构化数据,这些数据大多来自Web日志文件、远程传感数据以及安全日志文件等。这些数据不能由传统的关系型数据库进行存储和分析,新兴的NoSQL数据库和Hadoop技术有效地解决了这个问题。Hadoop中的MapReduce技术并行地处理海量数据,将多个节点输出的结果进行整合,得到便于分析的数据,这些数据可以存储到传统关系型数据库中做进一步分析。针对这些非结构和半结构化数据,Hadoop也有其有效的压缩方法。
针对以上提到的3V挑战,我们会在下面的内容中介绍现有的解决方案,包括Oracle提出的混合列压缩方法、Google提出的两趟压缩算法,以及Hadoop采用的LZO压缩算法。
7.4 Oracle混合列压缩
数据存储在传统技术中往往是以“行”的形式,即同一行中的各列数据都是顺序地存放在单个的数据块中。由于不同列数据的类型可能不同,这些不同类型的数据存储在一起,就使得压缩后节省的空间并不是很大。为了获得更高的压缩率,Oracle采用列存储的形式来存储数据,并且采用了混合列压缩(HCC,Hybrid Columnar Compression)技术[3]。
HCC以块(block)的形式来组织数据,它实际上同时利用了行存储和列存储的方法来存储数据。这种混合策略不但达到了很好的列压缩效果,而且还避免了单纯列存储时性能不足的缺点。一个称作压缩单元(compression unit)的逻辑结构被用来存储列压缩后的行数据。数据一旦被定位,一个行集合中的列值会被分组到一起,然后将其进行压缩。当完成这样的压缩后,数据会被存储到压缩单元中。图7-9是对压缩单元概念的说明。

图7-9 压缩单元结构
列压缩之所以能够取得很高的压缩率,是因为同一列的数据类型和值往往都很接近,重复的内容也就较多,为压缩提供了更大的空间。Oracle在实际应用中采用了bzip2压缩方法,bzip2本身是对Burrows–Wheeler算法的实现,这里不做过多介绍,有兴趣读者可以查看相应资料。
HCC对于仓库压缩和存档压缩都是有效的技术,下面来看看它们是如何应用的。
7.4.1 仓库压缩
仓库压缩在典型情况下可以提供10∶1(10x)的压缩率,节省的存储空间大约是行业平均水平的5倍。
仓库压缩提供两个层次的压缩:低级(LOW)和高级(HIGH)。高级仓库压缩通常提供10x的压缩比,而低级仓库压缩提供6x的压缩比。这两种压缩技术都在实际应用中进行了优化,通过减少硬盘存储块来提高检索查询性能。为了最大程度节省存储空间和提高查询效率,默认情况下是进行高级压缩。节省的存储空间多了,但是数据加载的次数却会略微增加。因此,对于那些对数据加载次数有限制的查询来说,低级压缩是更好的选择。
7.4.2 存档压缩
所谓存档数据,就是一些历史数据。由于数据量不断增加,很多IT管理人员都需要花费很多的精力和财力来管理存档数据。一些机构开发出一种信息生命周期管理(ILM,Information Lifecycle Management)的策略来帮助他们存储数据。典型的ILM策略包括将数据移动到更为廉价的存储设备上,比如便宜的硬盘,但更常用的是磁带。HCC的存档压缩技术可以减少存储开销,用更少的磁带来存储这些历史数据。
存档压缩通过一系列优化,压缩比可以到达15∶1(15x)。跟仓库压缩不同的是,存档压缩单纯是为了节省存储空间。运用了存档压缩后,通常都会降低系统的系能,这是采用达到最大压缩比的算法的结果。因此这种压缩方法一般用于那些不常用的历史数据。
Oracle在切分和二次切分中支持各种类型的表压缩。因此,一种OLTP应用程序可以在一个分区中采用存档压缩来存储历史数据,而那些还在使用的数据可以位于使用Oracle OLTP表压缩技术(Table Compression)的分区中。OLTP表压缩技术是一种高级压缩方法,用来压缩那些操作频繁的数据库。OLTP表压缩技术通常能达到2x到4x的压缩比,为OLTP数据库大大节省了存储空间。
7.5 Google数据压缩技术
作为Google三大技术之一的Bigtable,是Google内部开发的一个用来处理大数据量的系统。Bigtable内部存储数据的文件是Google SSTable格式的。SSTable是一个持久化的、排序的、不可更改的Map结构,而Map是一个key-value映射的数据结构,key和value的值都是任意的Byte串。从内部看,SSTable是一系列的数据块(通常每个块的大小是64 KB,这个大小是可以配置的)。
客户程序可以控制一个局部性群组的SSTable是否需要压缩,以什么格式来压缩。很多客户程序使用了“两遍”的、可定制的压缩方式。第一遍采用Bentley-McIlroy方式,这种方式在一个很大的扫描窗口里对常见的长字符串进行压缩;第二遍是采用快速压缩算法,即在一个16 KB的小扫描窗口中寻找重复数据。两个压缩的算法都很快,在现在的机器上,压缩的速率达到100~200 MB/s,解压的速率达到400~1000 MB/s。
在这里我们重点介绍第一遍压缩中的Bentley-McIlroy算法。
7.5.1 寻找长的重复串
数据压缩技术通常都会应用滑动窗口机制,窗口的典型长度是几 KB。但滑动窗口机制存在一个致命的缺点,那就是它不能压缩相距较远的重复字符串。有很多算法可以用来寻找文本文件中的长重复串。其中包括McCreight的后缀树、Manber和Myers的后缀数组。Bentley和McIlroy应用Karp和Rabin的指纹方法。
Karp和Rabin最初是在辅助字符串查找中提出的指纹方法:一个长为n的字符串是否包含一个长为m的查询模式?Karp和Rabin将m个字符的模式定义为以一个大素数为模的多项式,产生的指纹结果可以作为32比特的字来存储。他们的算法顺次扫描输入的字符串,并且针对n-m+1个长度为m的子串与同一个指纹进行比对。如果指纹没有匹配成功,那么我们确定输入的字符串中不包含匹配的模式;如果指纹比对成功,那就要进一步确定子串是否真的包含匹配的模式。
Karp和Rabin证明了指纹算法几点有用的性质。首先,指纹可以被很快地求出来:一个指纹可以在O(m)的时间内初始化,并且通过O(1)的时间滑动一个位置来更新指纹。其次,指纹几乎不会产生错误的匹配:不相等的字符串几乎不可能含有同样的指纹。两个不相等的字符串含有同样32比特指纹的概率大约是2-32。另外,可以通过随机地选择大素数来产生随机算法搜索文本。
Bentley-McIlroy压缩算法[4]利用了上面提出的块大小参数b。b的典型大小介于20到1000之间。理想情况下,我们希望忽略那些长度小于b的重复串,而压缩那些长度大于b的长重复串。Bentley-McIlroy算法要求长度至少为2b-1的字符串才会被压缩,介于b到2b-1之间的字符串有可能被压缩,小于b的字符串肯定不会被压缩。
Bentley和McIlroy提出的基本数据结构存储了每个大小为b字节的不重叠块的指纹。也就是说,依次存储了字节1到b,字节b+1到2b,……的指纹。在一个长度为n的文件中,大约会存储n/b个指纹。Bentley和McIlroy将它们存储在一个哈希表中,同时存储了代表指纹在原文件中位置的整数。当扫描输入文件时,算法会利用哈希表查找指纹并且确定重复串的位置。
7.5.2 压缩算法
因为Bentley-McIlroy算法仅仅表示长重复串,所以不必使用无效的表示。用序列“<开始位置,长度>”来表示重复串,其中“开始位置”代表初始的位置,“长度”代表重复串的长度。比如,美国宪法的开头如下:
The Constitution of the United States PREAMBLE We, the people
of the United States, in order to form a more perfect Union, ...
压缩后的形式如下:
The Constitution of the United States PREAMBLE We, the people
<16,21>, in order to form a more perfect Union, ...
对于字符“<”,会表示成“<<”的形式。
算法中主要的循环在于通过更新信号变量和查找哈希表寻找匹配来处理每一个字符。每b个字符都会存储一个指纹。如果用变量fp代表指纹,那么可以用如下伪码表示此循环:
initialize fp
for (i = b; i< n; i++)
if (i % b == 0)
store(fp, i)
updata fp to include a[i] and exclude a[i-b]
checkformatch(fp, i)
算法中的checkformatch函数在哈希表中寻找fp,当找到的时候对其进行编码。
当匹配成功的时候该怎样处理呢?假设b=100,并且当前长度为b的块和第56个块(也就是第5600个字节到第5699个字节)匹配成功。我们可以用序列<5600, 100>来表示当前块。这种算法不会处理长度小于b的字符串。如果一个块的大小至少是2b-1,那么至少存在一个长度为b的子串能够落在一个块内并且被查找出来。
事实上,Bentley-McIlroy采用了一个稍微聪明点的办法。在查找到一个块与一个指纹匹配成功以后,可以确保它不会是一个错误的匹配(这是指纹的性质之一)。然后Bentley-McIlroy会用贪婪算法尽量向前地查找匹配(但是不能超过b-1的长度,否则会找到前一个长度为b的块),紧接着再尽可能向后查找匹配。如果有若干个块和当前的指纹匹配,算法就选择对其中最长的串进行编码。表7-2所示的这些例子说明了b=1时算法的执行情况。
表7-2 b=1时的Bentley-McIlroy压缩算法
| 输 入 |
输 出 |
| abcdefghijklmnopq<12345 abcdefghijabcdefghij abcdefghijklmnopqrstuvwxijklmnopabcdefghqrstuvwx aaaaaaaaaaaaaaaaaaaaa |
abcdefghijklmnopq<<12345 abcdefghij<0,10> abcdefghijklmnopqrstuvwx<8,8><0,8><16,8> a<0,20> |
从上面的实验结果的最后一行可以看到,算法可以针对a不断进行重复匹配,实现对最长匹配字符串的压缩。
7.6 Hadoop压缩技术
Hadoop中的存储文件(HFile)在被写入(刷新过程或者紧缩过程)时会以块(block)为单位进行压缩,在它们被读取时需要进行解压缩,也就需要花费一定的时间。既然这个过程增加了程序运行的时间,那为什么还要进行压缩呢?有下面几个原因。
- 压缩能够减少从HDFS中读出和写入的字节数。
- 压缩能有效地提高网络带宽和磁盘空间的利用率。
- 压缩能减少读操作时所需的数据量。
为了减少压缩时间,需要选择一种实时压缩方法。Hadoop只装载了Gzip压缩技术,它是比较慢的。为了使效率和优势最大化,必须允许LZO运行在Hadoop上。
7.6.1 LZO简介
LZO是一个数据压缩库,适用于对数据进行实时的压缩和解压缩。根据用户不同的参数设置,LZO可以实现快速压缩,或者实现高比例压缩。但无论采用哪种压缩形式,在解压时速度都是非常快的,这也正是LZO的优势所在。
LZO开始是用ANSI C编写的,源代码和压缩数据的格式都可轻易跨平台。LZO应用一系列算法,这些算法具有以下特点。
- 解压缩很简单而且相当快。
- 解压不需要额外的内存空间。
- 压缩速度很快。
- 压缩时仅需要64 KB的内存空间。
- 允许在压缩部分以损失压缩速度为代价提高压缩率,解压速度不会降低。
- 包括生成预先压缩数据的压缩级别,这样可以得到相当有竞争力的压缩比。
- 另外还有一个只需要8 KB内存的压缩级别。
- 算法是线程安全的。
- 算法是无损的。
LZO是一种块压缩算法,块大小在压缩和解压缩时必须是一样的。LZO将一块数据压缩成与滑动字典匹配的部分以及没有匹配的部分。LZO很注重长的匹配字符串,因为可以在处理高冗余数据以及无法压缩的数据时获得更好的效果。在处理不能压缩的数据时,LZO最多只会让每1024字节数据增加64字节的内容(压缩后会多一些压缩数据,如滑动字典信息等)。
LZO实际上包含很多算法,在最大程度上保证了对这些算法的兼容性。尽管LZO的压缩库中包含了很多可用的压缩算法,在应用的时候只会加载一种压缩算法。这些算法包括LZ01、LZ01A、LZO1B、LZ01F、LZ01X、LZ01Y、LZ01Z等。经过试验,证明LZ01B适用于大的数据块或者存在大量冗余的数据,LZ01F适用于小的数据块或者二进制数据,LZ01X对于所有场景都常常是最好的选择。LZ01Y和LZ01Z几乎同LZ01X是一样的,只不过针对某些文件它们能获得更高的压缩比。
那么如何选择具体使用哪种算法呢?正如上面所说,LZ01X通常都是最好的选择,一般来说有以下几种情境。
- 当想要更快的压缩速度时选择LZ01X-1。
- 当产生与预压缩数据时使用LZ01X-999。
- 如果只有很少的内存可用时,那就选择LZ01X-1(11)或者LZ01X-1(12)。
这些算法在解压时有什么区别?我们还用LZ01X来做代表,因为它是标准的解压器,相当快,所以尽可能选择它。它包含以下几种解码器(decompressor)。
- lzo1x_decompress:这种解码器需要合法的压缩数据,如果压缩数据损坏,那么解压过程可能使你的程序崩溃,因为它并不会做预先的检查。
- lzo1x_decompress_safe:这种“安全”解压器速度有些慢,但是它能够检测出所有压缩数据的错误,并且返回错误代码,它永远不会崩溃。
- lzo1x_decompress_asm和lzo1x_decompress_asm_safe:类似上面两个解码器,只不过它们是用汇编语言编写的。
- lzo1x_decompress_asm_fast:跟lzo1x_decompress_asm相比更快。由于速度快,它会在解压后的数据块后面增加3字节的数据(因为数据以4字节进行传输,这样表示解压数据块的结束)。从一个内存块向另一个内存块解压时可以使用这种解码器,只不过需要提供额外3字节的输出空间。但如果直接往视频内存中解压时别使用这种解码器,因为额外的3字节数据会影响视频显示。
7.6.2 LZO原理[5]
LZO虽然包含了很多小的算法,但是基本原理都与LZSS压缩算法类似,所以首先介绍一下LZSS的原理。LZSS算法在压缩数据时,会设定标识位来说明后续编码的情况,如图7-10所示。
在这里,LZSS利用8 bit的标志位说明其后面紧邻4个位置的情况,每两位为一组,F(01)h=F(00 00 00 01)2,F(00)2表示新字符,F(01)2表示重复字符,F(11)2表示控制字符。需要强调的是,LZSS限制重复字符串的长度不能太小(这里要求不能小于2),所以第二个位置的A被当成新字符看待。这样前三个字符都是新字符,它们对应的标识位都为F(00)2。从第四个位置开始出现重复字符串,所以相应的标识位为F(01)2。((03)h, (06)h)中第一个元素表示重复字符串的位置偏移量,第二个元素表示重复长度,因为与第一个AAB重复,而且第一个A距离当前位置为3,且重复的长度为6,所以这里的就用((03)h, (06)h)表示后续的AABAAB了。

图7-10 LZSS压缩算法示例
LZSS存在一个缺点,就是当用来压缩的内容重复率低时,它仍然需要用标志位F(00)h表示,这就会增加很多不必要的空间开销。另外,由于LZSS在寻找重复串时是找最长的匹配串,所以时间开销也比较大。针对这两个缺点,LZO进行了改进,因此它的效率更高。
还是上面的例子,采用LZO压缩,如图7-11所示。
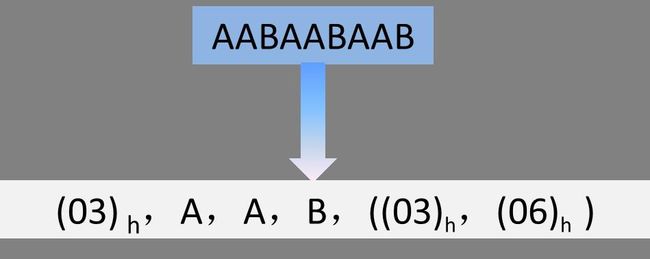
图7-11 LZO压缩算法示例
LZO不会采取标志位,而是直接计算新字符出现的次数,如上面例子中新字符的长度为3,所以就用(03)h表示。在解压的时候读到(03)h就知道后面三个字符为新字符直接输出,到第四个字符是重复串,向前偏移3个位置,输出长度为6的重复串。
在寻找匹配串时,LZO不是寻找最长的重复串,而是通过两次哈希操作,在记忆体(LZO编码过程中需要用记忆体记录编码信息)中寻找位置。如果两次哈希都产生冲突,那么LZO就不再寻找空位置,而是把需要编码的内容当成新字符输出。这样就大大减少了寻找最长匹配串的时间开销。
7.7 小结
本章主要介绍了数据压缩方面的技术。首先简单介绍了数据压缩的基本原理,然后分别介绍了传统压缩技术中的典型代表霍夫曼编码和LZ77算法,接着介绍海量数据带来的挑战,包括数量、时间和多样性。为了应对这些挑战,我们又介绍了Oracle的混合列压缩技术、Google压缩技术中的Bentley-McIlroy算法以及Hadoop中的LZO算法。