一、阻塞I/O
首先,要从你常用的IO操作谈起,比如read和write,通常IO操作都是阻塞I/O的,也就是说当你调用read时,如果没有数据收到,那么线程或者进程就会被挂起,直到收到数据。阻塞的意思,就是一直等着。阻塞I/O就是等着数据过来,进行读写操作。应用的函数进行调用,但是内核一直没有返回,就一直等着。应用的函数长时间处于等待结果的状态,我们就称为阻塞I/O。每个应用都得等着,每个应用都在等着,浪费啊!很像现实中的情况。大家都不干活,等着数据过来,过来工作一下,没有的话继续等着。
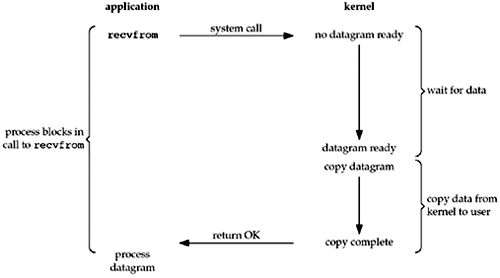
二、非阻塞I/O

三、I/O多路复用

作者:用心阁
链接:https://www.zhihu.com/question/28594409/answer/74003996
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
四、多路复用的三种方式(都是上面的I/O的多路复用,但是进行了改进)
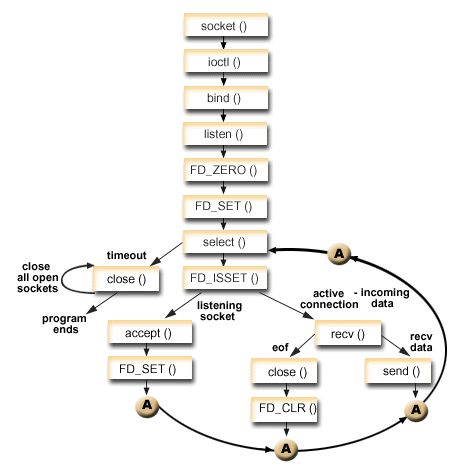
【1】每次调用select()都需要把fd(文件描述符)从用户态拷贝到内核态,开销比较大
【2】每次都需要在内核遍历传入的fd(文件描述符)
【3】select支持文件数量比较小,默认是1024
select/poll只提供了一个函数,selct/poll函数,但是epoll一下子就提供了3个函数,真是人多力量大,难怪这么强,如下3个函数:
epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句 柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
参考:http://www.cnblogs.com/Anker/p/3265058.html
五、python的select模块