前言
《牧神记》有一句话说的好,破心中神。当不再对分布式,微服务,CLR畏惧迷茫的时候,你就破了心中神。
zipkin复习
第一篇: .Net架构篇:思考如何设计一款实用的分布式监控系统?
第二篇:NetCore实践篇:分布式监控客户端ZipkinTracer从入门到放弃之路,我们提到了zipkin的原理和架构说明,以及用zipkintracer实践失败的记录。
今天我们来复习下。
zipkin作用
全链路追踪工具(根据依赖关系)
查看每个接口、每个service的执行速度(定位问题发生点或者寻找性能瓶颈)
zipkin工作原理
创造一些追踪标识符(tracingId,spanId,parentId),最终将一个request的流程树构建出来
zipkin架构
Collector接收各service传输的数据;
Cassandra作为Storage的一种,默认存储在内存中,也支持ElasticSearch和mysql用于生产落库;
Query负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用;
Web 提供简单的web界面;
zipkin分布式跟踪系统的目的
zipkin为分布式链路调用监控系统,聚合各业务系统调用延迟数据,达到链路调用监控跟踪;
zipkin通过采集跟踪数据可以帮助开发者深入了解在分布式系统中某一个特定的请求时如何执行的;
参考如下
zipkin参考
zipkin官网
zipkin4net简介
zipkin4net是.NET客户端库。
它为您提供:
-
Zipkin 原语(跨度,注释,二进制注释,......)【Zipkin primitives (spans, annotations, binary annotations, ...)】
-
异步跟踪发送
-
跟踪传输抽象
简单用法
var logger = CreateLogger(); //它应该实现ILogger
var sender = CreateYourTransport(); //它应该实现IZipkinSender
TraceManager.SamplingRate = 1.0f; //全监控
var tracer = new ZipkinTracer(sender);
TraceManager.RegisterTracer(tracer);
TraceManager.Start(logger);
//运行你的程序
//当关闭时。
TraceManager.Stop();
简介到此为止,剩余您可参考zipkin4net。
Show me the Code
废话少说,一杯代码为敬。
进入代码之前,我先来演示下代码结构。这个结构对应我之前的代码实践。内存队列,爬虫在我的博客内都能找到博客对应。
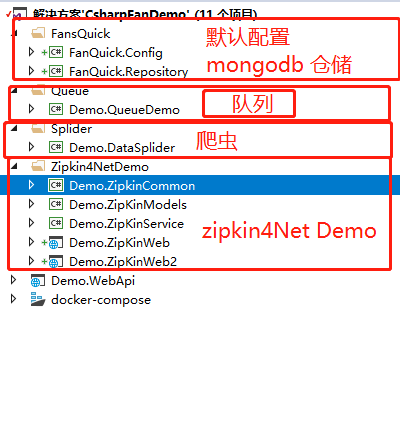
今天我们只说zipkin4Net的实践。为了测试查看zipkin是否能够汇集不同的站点,我特意建立了两个站点Demo.ZipKinWeb和Demo.ZipKinWeb2。类似下图:

为了能真实落库,我创建了FanQuick.Repository,用于提供mongodb存储帮助。IRepository泛型接口声明如下
namespace FanQuick.Repository
{
public interface IRepository where TDocument:EntityBase
{
IQueryable Queryable { get; }
bool Any(Expressionbool >> filter);
/// bool >> filter);
/// Find(Expressionbool>> filter);
/// documents) ;
/// bool >> filter);
TDocument FindOneAndDelete(Expressionbool >> filter);
TDocument FindOneAndUpdate(FilterDefinition filter, UpdateDefinition update) ;
}
}
为了两个站点能够复用调用zipkin4net的通知,我将代码抽离出来放到了 Demo.ZipkinCommon。
可复用的抽象类CommonStartUp,代码如下:重点关注下调用zipkin4net的代码。并将抽象Run方法暴漏给了子类,需要子类实现。要特别注意,appsettings.json需要设置applicationName,不然发送到zipkin就是未命名服务,这就不能区分站点了!
namespace Demo.ZipkinCommon
{
public abstract class CommonStartup
{
// This method gets called by the runtime. Use this method to add services to the container.
// For more information on how to configure your application, visit https://go.microsoft.com/fwlink/?LinkID=398940
public abstract void ConfigureServices(IServiceCollection services);
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
var config = ConfigureSettings.CreateConfiguration();
var applicationName = config["applicationName"];
//if (env.IsDevelopment())
//{
// app.UseDeveloperExceptionPage();
//}
//else
//{
// app.UseExceptionHandler("/Home/Error");
// app.UseHsts();
//}
var lifetime = app.ApplicationServices.GetService();
lifetime.ApplicationStarted.Register(() =>
{
TraceManager.SamplingRate = 1.0f;
var logger = new TracingLogger(loggerFactory, "zipkin4net");
var httpSender = new HttpZipkinSender("http://weixinhe.cn:9411", "application/json");
var tracer = new ZipkinTracer(httpSender, new JSONSpanSerializer());
TraceManager.RegisterTracer(tracer);
TraceManager.Start(logger);
});
lifetime.ApplicationStopped.Register(() => TraceManager.Stop());
app.UseTracing(applicationName);
Run(app, config);
}
protected abstract void Run(IApplicationBuilder app, IConfiguration configuration);
}
}
读取配置类,也独立了出来,可支持读取appsettings.json,每个站点需要把appsettings.json设置允许复制,不然会找不到文件!!
namespace Demo.ZipkinCommon
{
public class ConfigureSettings
{
public static IConfiguration CreateConfiguration()
{
var builder = new ConfigurationBuilder()
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddEnvironmentVariables();
return builder.Build();
}
}
}
公用部分完成了。我们看看站点Demo.ZipKinWeb代码。Startup继承抽象类CommonStartup,并利用.netCore内置依赖注入,将Service和仓储注入进来。由于不支持直接注入泛型,但支持type类型的注入,间接也解决了泛型注入问题。关于依赖注入的讲解,你可以参考上篇文中依赖注入部分,加深理解。
namespace Demo.ZipKinWeb
{
public class Startup : CommonStartup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public override void ConfigureServices(IServiceCollection services)
{
services.Configure(options =>
{
// This lambda determines whether user consent for non-essential cookies is needed for a given request.
options.CheckConsentNeeded = context => true;
options.MinimumSameSitePolicy = SameSiteMode.None;
});
services.AddScoped(typeof(IRepository<>), typeof(BaseRepository<>));
services.AddScoped();
services.AddScoped();
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_1);
}
protected override void Run(IApplicationBuilder app, IConfiguration configuration)
{
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseCookiePolicy();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
}
}
}
为了实现聚合两个站点的效果,在Add的方法内,特意调用一下另外个站点的get
[HttpPost]
public IActionResult Add([FromBody]User user)
{
_userService.AddUser(user);
//模拟调用其他站点请求。
var client = new RestClient($"{ConfigEx.WebSite}");
var request = new RestRequest($"/user/get", Method.POST);
request.AddParameter("id", user.Id); // adds to POST or URL querystring based on Method
IRestResponse response = client.Execute(request);
var content = response.Content;
// return Json(new { data = content });
return Content(content+_addressService.Test());
}
建好必要的Controller和Action后,将两个站点都设为已启动。就可以查看效果了。
postman是个测试接口的好工具,点击Send。
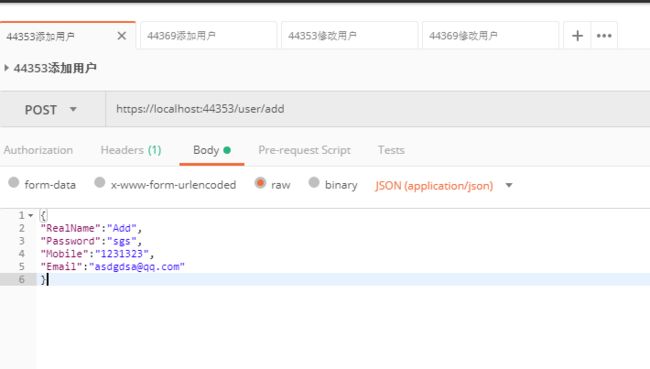
打开我们的zipkin服务器链接,在WebUI上,可以看到两条请求数据。这是正确的,一条是Add,里面又调了另外一个站点的get,也能看到消耗的时间。

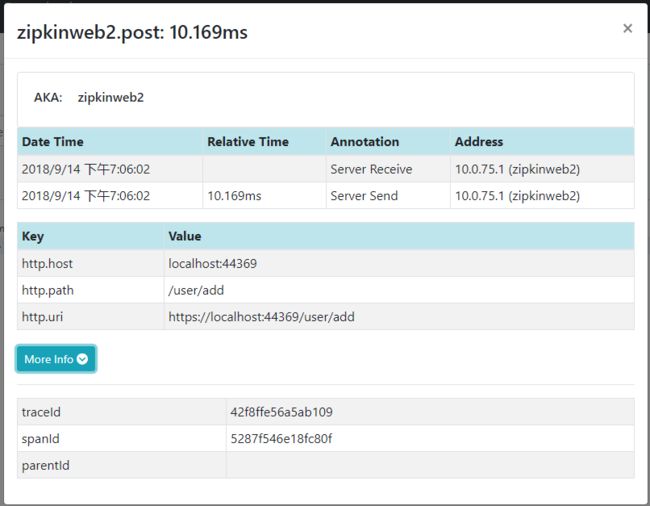

zipkin Dependencies no data
果然网友是万能的。elasticsearch存储,zipkin依赖没有数据
里面有位外国同仁提到了
当你用你elasticsearch 或 Cassandra的时候,需要执行zipkin-dependencies
(you need to run https://github.com/openzipkin/zipkin-dependencies when using elasticsearch or Cassandra)
zipkin-dependencies简介
这是一个Spark作业,它将从您的数据存储区收集跨度,分析服务之间的链接,并存储它们以供以后在Web UI中呈现(例如http://localhost:8080/dependency)。
什么是Spark?
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
此作业以UTC时间分析当天的所有跟踪。这意味着您应该将其安排在UTC午夜之前运行。
支持所有Zipkin 存储组件,包括Cassandra,MySQL和Elasticsearch。
这真是一个弱鸡的设计,作为内存运行的演示,竟然不提供及时汇总分析,还要跑定时任务 【2018-9-17日补充,此处结论有误,内存运行能提供实时汇总,这里不删除,是保留写作时的感悟】
依据官方提示,按最快的方式进行。
wget -O zipkin-dependencies.jar 'https://search.maven.org/remote_content?g=io.zipkin.dependencies&a=zipkin-dependencies&v=LATEST'
STORAGE_TYPE=cassandra3 java -jar zipkin-dependencies.jar
或者用Docker启动
docker run --env STORAGE_TYPE=cassandra3 --env CASSANDRA_CONTACT_POINTS=host1,host2 openzipkin/zipkin-dependencies
用法
默认情况下,此作业解析自UTC午夜以来的所有跟踪。您可以通过YYYY-mm-dd格式的参数解析不同日期的跟踪,如2016-07-16。
# ex to run the job to process yesterday's traces on OS/X
STORAGE_TYPE=cassandra3 java -jar zipkin-dependencies.jar `date -uv-1d +%F`
# or on Linux
STORAGE_TYPE=cassandra3 java -jar zipkin-dependencies.jar `date -u -d '1 day ago' +%F`
执行失败
STORAGE_TYPE=cassandra3 java -jar zipkin-dependencies.jar `date -u -d '1 day ago' +%F`
18/09/14 20:24:50 INFO CassandraDependenciesJob: Running Dependencies job for 2018-09-13: 1536796800000000 ≤ Span.timestamp 1536883199999999
18/09/14 20:24:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/09/14 20:24:51 ERROR SparkContext: Error initializing SparkContext.
java.lang.IllegalArgumentException: System memory 466288640 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:217)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:330)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:175)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:256)
at org.apache.spark.SparkContext.(SparkContext.scala:423)
at zipkin2.dependencies.cassandra3.CassandraDependenciesJob.run(CassandraDependenciesJob.java:181)
at zipkin2.dependencies.ZipkinDependenciesJob.main(ZipkinDependenciesJob.java:57)
Exception in thread "main" java.lang.IllegalArgumentException: System memory 466288640 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:217)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:330)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:175)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:256)
at org.apache.spark.SparkContext.(SparkContext.scala:423)
at zipkin2.dependencies.cassandra3.CassandraDependenciesJob.run(CassandraDependenciesJob.java:181)
at zipkin2.dependencies.ZipkinDependenciesJob.main(ZipkinDependenciesJob.java:57)
意思是系统内存太小了。。。渣渣。
搜索到相关链接,如下:
Zipkin 使用api调用没有数据 Zipkin api traces为空
Zinkin进阶篇-Zipkin-dependencies的应用
zipkin提供的接口标准
spark内存介绍
更简易的格式显示内存错误信息
ERROR SparkContext: Error initializing SparkContext.
System memory..must be at least ... Please use a larger heap
spark 内存管理
如何设置spark.executor.memory和堆大小
Spark Misconceptions
如何在Eclispe环境中设置spark的堆大小?
里面似乎有个有用的答案
您可以通过编辑“
{SPARK_HOME} / conf /”,但是有一个文件“spark-defaults.conf.template”,您可以使用以下命令创建“spark-defaults.conf”文件:
cp spark-defaults.conf.template spark-defaults.conf
然后,编辑它:
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.driver.memory
但我没查到SPARK_HOME的环境变量。
Linux下设置和查看环境变量
继续调整工作重心。
java.lang.IllegalArgumentException:系统内存
里面作者或网友提到:
gc是可选的JAVA_OPTS=-verbose:gc -Xms1G -Xmx1G,https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html#BABDJJFI
JAVA_OPTS的一些介绍
JAVA_OPTS设置
谈一谈JVM内存JAVA_OPTS参数
Tomcat之——内存溢出设置JAVA_OPTS
JAVA_OPTS参数说明与配置
Linux下vi查找关键字
按照以上操作修改仍未成功。。。有某位仁兄知道处理办法,可否告知?
罢了,罢了,不留个尾巴,怎么能引起我的求知欲。原本只是想简简单单看看zipkin,却迈向了Spark,JVM之路,留个问题待以后深思。
下篇将继续zipkin熟悉之路,持久化mysql,还有今天未结束的主题,zipkin-dependencies
总结
标题是.NetCore,大部分是在找java问题,我也是醉了。没办法用的监控是java开源的,不要抱怨,继续研究。这应该是个小问题。这就是写博客扩展的学习范围,原本不在我的计划之类。坚持就有收获,至少我现在知道了Spark的一些介绍,jvm的一些参数。
感谢观看,本篇结束。