FPGA技术的未来发展:谁与AI平分秋色

参加 2019 Python开发者日,请扫码咨询 ↑↑↑
作者 | 老石
来源 | 老石谈芯(公众号id:gh_5ce1d0cb1568)
责编 | Jane
任何科学技术的发展和进步都离不开两个主要的推动力量,一个是相关领域各大公司的研发,另一个就是各大高校与科研院所的科学研究。这两者往往是相互补充、相互促进的关系,既能涵盖短期的实用性研究,又有长期技术难题的攻关与突破。
这样的技术发展模式,FPGA行业也不例外。除了英特尔、赛灵思等大公司的研发投入之外,世界上各大顶尖高校对于FPGA的研究也在不断帮助FPGA技术取得新的成就。
在诸多决定着FPGA技术发展的新成就里,那些最为突出的成果,也就是所谓的“皇冠上的明珠”,都会集中发表在一年一度的“FPGA国际研讨会”上(简称ISFPGA)。从1993年举办至今,ISFPGA一直是FPGA领域的旗舰级顶会,没有之一。在ISFPGA上发表的文章,都代表着FPGA最前沿和最优秀的研究成果,也被业界人士看成是预测FPGA今后发展方向的风向标。
在2019年2月结束的ISFPGA会议上,再一次涌现出了诸多崭新的研究成果。从整体上看,业界的研究方向主要集中在两个方面:
一个是和人工智能和机器学习相关的各个领域,比如FPGA微架构、FPGA编程工具与编程语言,以及FPGA在AI的各种应用等。
另一个是FPGA的高层次综合(High-Level Synthesis,HLS),也就是使用高层语言,如C++/OpenCL/Python等,对FPGA进行有效的编程和使用。
其中,这届会议中与AI相关的文章有8篇,与高层次综合相关的文章有6篇,占会议接收的全部24篇论文的超过一半。
老石在之前详细介绍过赛灵思在这次会议上发表的有关ACAP架构的论文。在今天的这篇文章中,老石又挑选了另外五篇具有代表性的论文,为各位逐一点评和解析。同时,我也会简单介绍论文主要作者的背景和代表性研究,方便各位把握当前最新的FPGA发展动态。
一、FPGA微架构:低精度乘加单元

一句话总结
随着软硬件技术的不断发展,DNN算力的瓶颈已逐渐从内存带宽转向乘加(MAC)操作效率,因此本文提出了面向英特尔FPGA的全新低精度乘加单元微架构。
对行业发展的影响和意义
显著提升了FPGA低精度乘加操作的性能与资源利用率,是针对DNN应用的“杀手级”微架构创新。提出的新架构专为英特尔FPGA设计,预计会带来巨大的竞争优势。
技术细节
本论文来自多伦多大学的Vaughn Betz课题组。多伦多大学的FPGA研究一直被公认是世界顶尖水平,归功于这里的一群大牛教授,比如Jonathan Rose, Vaughn Betz, Jason Anderson, Paul Chow等。他们的研究基本涵盖了FPGA的各个层面,包括架构、工具、应用等各个领域。
他们很多人都曾经担任过FPGA公司高管,有多年的工业界一线研发经历,转向学术界后仍然与工业界结合非常紧密,这使得他们的研究有着极强的实用性,对于FPGA行业发展有着很重要的推动作用。

这篇论文研究的大背景,是当前在DNN中使用低精度算术运算可以取得极大的性能提升。DNN中的两类核心算法:CNN和LSTM,都可以在很大程度上受益于低精度的乘加运算。为了实现这种低精度的DNN数据通路,FPGA往往是超越CPU和GPU的第一选择,因为它在灵活性和性能等方面有着很好的平衡。例如,微软的脑波项目就使用了自定义的低精度(8~9位)浮点数表示。
另一方面,作者指出随着FPGA器件和云端部署等技术的发展,内存带宽已经逐渐不再是DNN的算力瓶颈,取而代之的是单周期可以完成的乘加操作数量,这其实是一个非常新颖的观点。
作者发现,传统的FPGA架构在执行乘加操作时,会浪费大量逻辑资源,进而导致性能无法达到最优。因此本文提出了三种针对英特尔Stratix 10 FPGA的微架构创新,以提升DNN里乘加操作的性能和资源使用率。例如,一种方法是在传统ALM结构里增加一条额外的进位链,如下图所示。这样避免了使用多余的ALM完成最后一级加法操作,从而节省了逻辑资源,也减少了ALM间的传输延时。
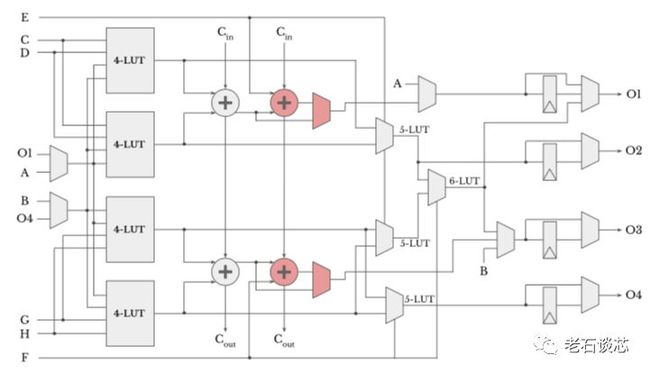
使用这种方法,乘加操作的平均延时会缩短21%,乘加单元的面积会减小35%。文中提出的另外两种微架构在这里不再详述,这篇文章的文笔很棒,可读性很强,推荐有兴趣的读者看看。
二、名为HetroCL的可重构计算编程语言框架

一句话总结
基于Python的FPGA编程模型与编译工具,为DNN应用而优化。
对行业发展的影响和意义
降低了FPGA的编程难度,有效解决了一些当前高层次综合存在的问题与痛点。相比传统的FPGA开发与编程模型,这个新提出的名为HetroCL的领域专用语言和编程框架兼顾了性能与开发效率,使开发者可以专注于算法实现,而无需考虑FPGA底层逻辑的实现与优化。
技术细节
这篇文章由康奈尔大学的张志如副教授、以及UCLA的丛京生教授及两位的团队合作完成,并获得了本次大会的最佳论文奖。这两位也是FPGA领域的顶级学者,主要专注于FPGA的高层次综合等领域,而丛教授也是张教授的博士导师。在博士研究期间,二人创办了AutoESL公司,并随后被赛灵思收购,其主要软件产品也正是赛灵思Vivado HLS的前身。

FPGA的高层次综合(High-Level Synthesis)指的是将诸如C++、OpenCL等高层语言,通过特定编译工具直接转化成FPGA上可以运行的硬件代码。有关HLS的研究一直是学术界和工业界的研究热点,英特尔和赛灵思都有各自的HLS工具和开发套件。
然而,使用HLS并没有想象中那么简单。虽然算法和模型可以使用高层语言编写,但为了达到最优的硬件性能,开发者仍然需要清楚的了解底层FPGA的硬件架构,并通过特殊的预处理指令指导HLS编译器生成期望的硬件结构。这也使得HLS在很多时候并没有体现出它的便利性优势。
例如,一个简单的点积函数的HLS描述如下图所示,可以看到算法部分包含很多与底层硬件相关的#pragma,用以指导特定的编译器行为,严重影响开发效率与代码可读性。

为了解决这个问题,这篇论文提出了一种基于Python的领域专用语言(Domain Specific Language),名为HeteroCL。它的最主要特点是能将算法描述与底层硬件结构进行完全解耦,使得算法设计师不需要关心底层硬件的数据类型、计算单元实现以及存储器架构优化等,如下图所示。

关于HeteroCL的语法和语义在这里不再详述,有兴趣的读者可以自行查阅论文原文。
三、使用P4语言编程FPGA

一句话总结
使用高层语言“P4”构建网络算法和应用,并直接映射到FPGA上执行。
对行业发展的影响和意义
这是一种快速开发FPGA的新方法。与基于RTL的传统FPGA开发方法、以及基于C/C++的高层次综合HLS相比,这种方法在性能和灵活性达到了很好的平衡。P4适用于诸如网络数据包处理等算法和应用,使用者不需要掌握Verilog或VHDL等硬件描述语言,就可以快速完成网络算法的建模与FPGA硬件实现。
技术细节
这篇论文的作者来自斯坦福大学、赛灵思和剑桥大学,作者之一的Nick McKeown教授就是P4语言的发明者。这篇论文主要介绍了如何使用P4编写计算机网络算法,并如何通过新提出的软件工具将其自动映射到FPGA上。
P4语言的全名为“Programming Protocol-independent Packet Processors”。与C/C++/Python等通用语言不同,P4是一种领域专用语言,主要被设计用来描述各类网络算法与应用,如数据包处理、分类、查找、路由等等。顾名思义,P4语言的主要设计目标有以下三点:
协议无关:即P4语言及其底层硬件可以支持各类网络协议
现场可编程:即部署后仍然具有可编程能力
可扩展:即P4可以在多种硬件平台上使用
与ASIC相比,FPGA在性能上有着大约一个量级的差距。即便如此,FPGA有着很好的灵活性,能够实现多种网络算法并在其中灵活切换,因此被广泛用于网络数据处理的场合,例如之前讲过的智能网卡等等。
然而,FPGA对于非硬件工程师而言有着很大的开发难度,因此使用P4这种领域专用语言进行FPGA的高层次开发就成了十分自然的考虑。
这篇论文提出的开发流程如下图所示。简单来说,就是将P4程序,借助赛灵思的P4和SDNet编译器生成底层的Verilog模块,然后映射到名为“NetFPGA”的参考设计上。

在生成Verilog模块的过程中,使用了定义好的模块库和元组。因此这种方法本质上是一种FPGA虚拟化方法,即在FPGA底层硬件之上,增加了一层虚拟的模块层,并可以通过P4语言直接映射。
四、将DNN模型映射到FPGA云的开源架构

一句话总结
一个开源的工具链,用于将训练完成的CNN模型映射到亚马逊AWS FPGA云服务上运行。
对行业发展的影响和意义
这篇论文与微软脑波项目(Project Brainwave)完成的工作非常类似,不同之处在于采用了高层次综合HLS的方法,针对公有云的FPGA服务,并且开源。因此为从事云端DNN加速研究的相关人员和机构提供了应用平台与经验借鉴。
技术细节
这篇论文的作者来自新加坡和美国伊利诺伊厄巴纳-香槟分校(UIUC),作者之一来自UIUC的陈德铭教授是硬件加速器研究领域的知名学者。
这篇论文与微软脑波项目完成的目标非常类似,只是实现方法有所不同。之前介绍过,脑波项目将训练好的DNN模型转化成数据流图表示,然后根据单一FPGA的资源情况,对数据流图进行拆分,并映射到FPGA的软核NPU上。
在这篇论文中,直接使用HLS工具对DNN模型进行综合,见下图,这在很大程度上减少了开发的难度,但与脑波方案相比,不可避免的会有较大的性能差距。同时,这个工作只支持Caffe,而不支持其他DNN框架。

在脑波项目中,FPGA基础架构是源于Catapult项目的大规模FPGA互联和资源池,而本论文主要面向的是亚马逊AWS-F1实例的FPGA公有云。这样的好处是能为广大AWS开发者或其他希望进行FPGA DNN加速的用户提供参考平台和经验借鉴,但同样的也会有明显的性能限制。
相比CPU而言,使用FPGA对DNN进行硬件加速仍然可以取得可观的性能提升。比如在这篇论文中,针对不同的DNN模型,使用FPGA可以取得47倍~104倍的加速性能。
五、多线程代码的高层次综合工具:EASY

一句话总结
使用形式化(formal)方法,有效减少高层次综合多线程代码时使用的内存仲裁器数量与逻辑复杂度。
对行业发展的影响和意义
极大的提高了FPGA的高层次综合工具的性能,尤其是对多线程代码有了更好的支持。
技术细节
这篇论文由伦敦帝国理工大学的George Constantinides教授团队和多伦多大学的Jason Anderson教授团队合作完成。这两位都是FPGA学术界鼎鼎大名的人物,George Constantinides有着很深的数学功底,研究方向主要集中在针对FPGA内存优化的高层次综合,以及和数学相关的FPGA字长优化,还有近年兴起的近似计算等领域。
帝国理工大学在FPGA研究领域也处于世界顶尖水平,除了George之外,还有Peter Cheung和Wayne Luk两位华裔教授,这两位对于现代FPGA技术的发展做出了举足轻重的贡献,本文不再展开。

这篇论文研究的主要问题是,当对多线程代码进行FPGA的高层次综合时,多个线程之间对内存的读写需要额外的仲裁机制,这主要用来判断某块内存会被哪些线程所访问。而这个仲裁机制在硬件实现上会有很大的额外开销,对性能也有很大的消极影响,如下图所示。
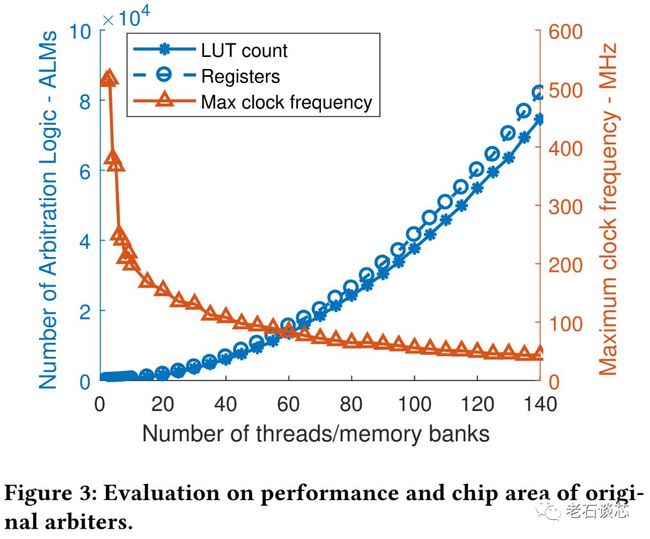
不过作者注意到,线程往往不会访问所有内存块,因此很多情况下仲裁器不需要支持全部的线程-内存块映射,这样就大大减少了仲裁器的逻辑复杂度,从而提高了系统性能。
为了判断某个线程是否会访问某个内存块,作者使用了形式化方法,通过将多线程代码转换成一种单线程的形式化描述语言Boogie,并通过形式化工具证明某个线程与内存块的访问关系,这样就能完全确定仲裁器需要支持的线程与内存块的映射。
这个思路十分简洁但有效,它的完整流程图如下图所示。这篇文章使用这种方法取得了高达39%的性能提升,以及高达87%的面积缩减。

六、结语
展望2019年FPGA技术的发展趋势,人工智能与高层次综合必将是两大值得关注的重点领域。随着新技术的不断涌现,FPGA的易用性和性能都将得到极大提升。在这其中,人工智能和数据中心将会是作者持续关注的重中之重。
(注:本文仅代表作者个人观点,与任职单位无关。)
--【本文完】--
(*本文为AI科技大本营转载文章,转载请联系作者,观点属作者个人)
推荐阅读:
顶会论文9篇,又斩获百度奖学金!哈工大NLP“新生代”正崭露头角
Google用更少标签生成图像,还提出一个用于训练评估GAN的库
如何用TF Object Detection API训练交通信号灯检测神经网络?
Google首页玩起小游戏,AI作曲让你变身巴赫
特斯拉起诉小鹏汽车员工窃取商业机密,何小鹏回应
提升效率,这十个Pandas技巧必不可少!
超常用的Python代码片段 | 备忘单
工作量不断增加的微软Azure,正缩小与亚马逊AWS的差距
理工男的网红生意, 6000万月活50万条日更的背后, 内容链还能这样操作?
曝光!月薪 5 万的程序员面试题:73% 人都做错,你敢试吗?

❤点击“阅读原文”,查看历史精彩文章。