最新干货!Thrift源码解析——深度学习模型的服务器端工程化落地方案
【文章来源】极链AI云(性价比最高的共享算力平台,助力你的技术成长~首次注册可获免费100小时GPU使用时长!官网地址:https://cloud.videojj.com/)
深度学习者常常有疑问,如果有了训练好的模型,怎么用服务调用?很多人可能会想到 Flask 进行 Http 调用。
那如果是内网呢?如果希望去掉 Http 封包解包一系列耗时操作呢?自然我们会想到 Rpc 协议。
RPC(Remote Procedure Call)是一种远程调用协议,简单地说就是,能使应用像调用本地方法一样,调用远程的过程或服务,可以应用在分布式服务、分布式计算、远程服务调用等许多场景。
有很多优秀的 Rpc 框架,如 gRpc、Thrift、Dubbo、Hessian 等,本文来介绍一下 Thrift 框架中的服务模型。
为什么需要了解服务模型?因为为了增大 Rpc 服务端的并发处理能力,需要选择更合适的 Thrift 服务模型,这就需要我们了解各个服务模型的特性。
下面对支持 Python 的各个服务模型做具体介绍:
一、TSimpleServer
TSimpleServer 的工作模式采用最简单的阻塞 IO,实现方法简洁明了,便于理解,但是一次只能接收和处理一个 socket 连接,效率比较低。
1、处理流程
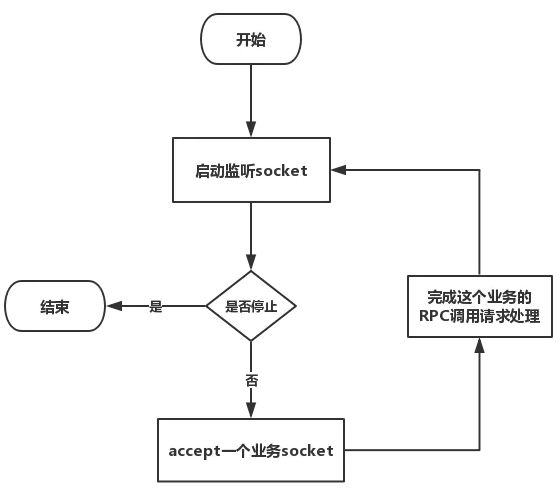
2、源码分析
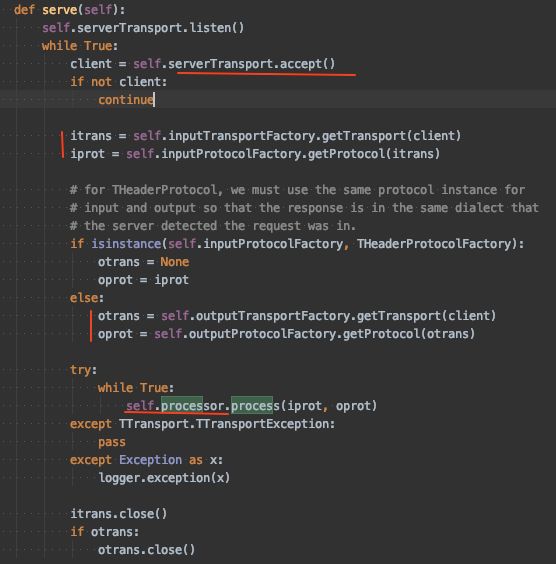
设置 TServerSocket 的 listen() 方法启动连接监听。
以阻塞的方式接受客户端的连接请求,每进入一个连接即为其创建一个 TSocket 对象(封装 socket 连接)。
为客户端创建输入传输通道对象、输出传输通道对象、输入协议对象和输出协议对象。
processor 对象为服务模型创建之前创建的,用来处理具体的业务请求。
二、TNonblockingServer TThreadPoolServer TThreadedServer
这三个服务模型放在一起讲,是因为 python 中多线程有点鸡肋。而这三种模型都是利用了多线程技术。
1、首先来看 TThreadedServer,目的是为每个 client 请求创建单独的线程进行业务处理

2、然后是 TThreadPoolServer,服务启动时先创建好 self.threads 个线程,每个线程负责从队列 clients 中获取客户端连接TSocket 对象。而主线程负责 accept 客户端的连接并创建 TSocket 对象,放入 clients 队列。
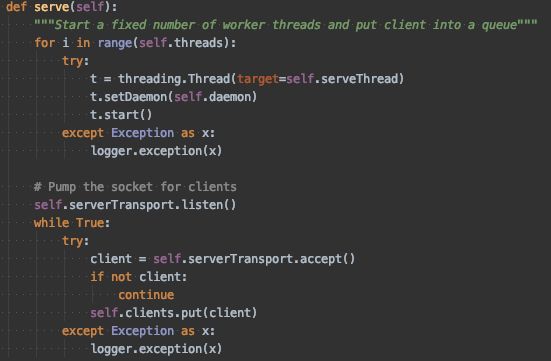

3、最后是 TNonblockingServer,这个稍微复杂一点。类似于 java 版 thrift 中的 THsHaServer,思路是服务启动时创建 threads个线程负责处理 task 队列中的任务消息。而主线程利用 io 多路复用技术将准备好的可读消息放入 task 队列供业务线程处理,同时在处理结束后可写时直接将结果返回给客户端。



三、TForkingServer TProcessPoolServer
这两个服务模型在 java 中并没有发现,目的也是规避 python 的 gil 锁问题。
其中 TForkingServer,服务端每次监听到 client 请求,会 os.fork一个子进程进行业务处理。

而这显然 fork 会消耗一定时间,而且服务端资源不是无限的,推荐还是用下面这个,TProcessPoolServer。服务启动时创建指定个数的进程,负责监听同一个端口的客户端请求,并进行业务处理。

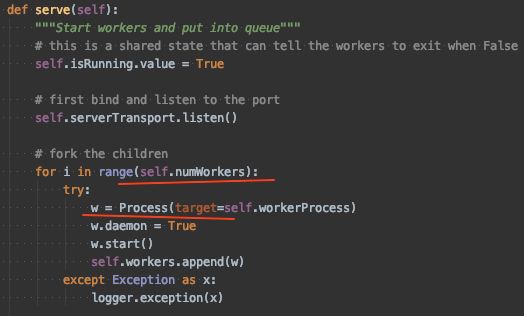
以上就是主要的 python 版 thrift 服务模型介绍。需要注意的是 socket.accept()从全连接队列拿连接,连接队列(全连接和半连接)总大小在 thrfit 里默认是128,可修改。

四、实际应用:
测试环境:
64核 CPU
测试结果:
无 GPU 操作,单次处理0.3s左右,100次请求
1、客户端单个client串行发送100次,或者10线程分别发送10次,共享同一个client,结果均为33秒多。可见对于单个client连接服务器处理均是串行,与代码显示相符。
2、客户端10线程分别发送10次,每个线程创建1个client,服务器端进程池模型(TProcessPoolServer),进程数10。用时3秒多。同样说明对于单个client连接服务器处理均是串行。
3、客户端100线程分别发送1次,每个线程创建1个client,服务器端进程池模型(TProcessPoolServer),进程数10。用时3秒多,比测试2略多一点,可以预见服务端创建销毁client,占据了一点时间。
4、客户端10线程分别发送10次,每个线程创建1个client,服务器端non-blocking模型(TNonblockingServer),处理线程数10。结果和测试1、2差不多时长,说明cpu密集型任务,python不适合多线程。
5、客户端10线程分别发送10次,每个线程创建1个client,服务器端进程模型(TForkingServer),为每个client创建fork进程。用时4秒多。说明fork子进程耗时明显。
6、客户端100线程分别发送1次,每个线程创建1个client,服务器端进程模型(TForkingServer),为每个client创建fork进程。用时11秒多,同样说明fork子进程耗时明显。
本文已获平台作者原创授权,想要认识更多深度学习小伙伴,交流更多技术问题,欢迎关注公众号“极链AI云”(为你提供性价比最高的共享算力平台,官网地址:https://cloud.videojj.com/)