Linux 0.11 系统调用的实现机制
Linux 0.11 系统调用的实现机制
一、系统调用概述
系统调用本质上是一种中断,中断号为0x80,即128号中断。通常我们使用的是库函数,而不是直接使用系统调用,这主要是因为库函数一般都是规定好的,是可以移植的。而系统调用的具体子调用号可能会发生改变,不同平台可能不一样,写出来的程序难以移植。触发系统调用,会进入内核态,并调用绑定的处理函数。内核开发人员必须考虑如何将用户空间的参数传递给内核,同时怎么把系统调用的结果传回用户空间。0.11版本的内核使用寄存器来传递参数和传递返回值,同时用来传递调用号,如read,write的对应的调用号。这个调用号实际上对应一张系统调用表的下标,该系统调用表是一个数组,保存内核态下具体调用函数的入口地址。如果传递的是一个用户态下的地址,则使用指向用户数据段的寄存器fs来对应用户数据区,从而实现对用户数据进行读写。大部分库函数都是用int 0x80实现的,但不是所有库函数都需要系统调用。内核在移入用户态时,需要在用户态下使用部分内核库函数,启动init进程,shell进程。然而库函数并不是内核的一部分,需要交给上一层来实现。
二、内核库函数的实现
2.1 unistd.h文件
在include/unistd.h(p380)中,定义了72个系统调用号:
#define __NR_setup 0 /* used only by init, to get system going */
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
#define __NR_close 6
#define __NR_waitpid 7
#define __NR_creat 8
#define __NR_link 9
#define __NR_unlink 10
#define __NR_execve 11
#define __NR_chdir 12
#define __NR_time 13
#define __NR_mknod 14
#define __NR_chmod 15
#define __NR_chown 16
#define __NR_break 17
#define __NR_stat 18
#define __NR_lseek 19
#define __NR_getpid 20
#define __NR_mount 21
#define __NR_umount 22
#define __NR_setuid 23
#define __NR_getuid 24
#define __NR_stime 25
#define __NR_ptrace 26
#define __NR_alarm 27
#define __NR_fstat 28
#define __NR_pause 29
#define __NR_utime 30
#define __NR_stty 31
#define __NR_gtty 32
#define __NR_access 33
#define __NR_nice 34
#define __NR_ftime 35
#define __NR_sync 36
#define __NR_kill 37
#define __NR_rename 38
#define __NR_mkdir 39
#define __NR_rmdir 40
#define __NR_dup 41
#define __NR_pipe 42
#define __NR_times 43
#define __NR_prof 44
#define __NR_brk 45
#define __NR_setgid 46
#define __NR_getgid 47
#define __NR_signal 48
#define __NR_geteuid 49
#define __NR_getegid 50
#define __NR_acct 51
#define __NR_phys 52
#define __NR_lock 53
#define __NR_ioctl 54
#define __NR_fcntl 55
#define __NR_mpx 56
#define __NR_setpgid 57
#define __NR_ulimit 58
#define __NR_uname 59
#define __NR_umask 60
#define __NR_chroot 61
#define __NR_ustat 62
#define __NR_dup2 63
#define __NR_getppid 64
#define __NR_getpgrp 65
#define __NR_setsid 66
#define __NR_sigaction 67
#define __NR_sgetmask 68
#define __NR_ssetmask 69
#define __NR_setreuid 70
#define __NR_setregid 71显然,exit是1号,fork是2号,read是3号,write是4号。setup仅能调用一次。Linux 0.11可以使用的系统调用是72个。
同时,该文件还定义了几个宏:
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
#define _syscall2(type,name,atype,a,btype,b) \
type name(atype a,btype b) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
#define _syscall3(type,name,atype,a,btype,b,ctype,c) \
type name(atype a,btype b,ctype c) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \
if (__res>=0) \
return (type) __res; \
errno=-__res; \
return -1; \
}这些宏将用具体的函数名、返回值、参数,扩展成一个库函数。其中eax保存的子调用号,ebx是第一个参数,ecx是第二个参数,edx是第三个参数。返回值保存在eax中。使用int 0x80启用系统调用,调用结束之后,执行的下一步骤是检查返回值,没有出错则将返回值返回,出错则将返回值的正值赋给errno,返回-1。这是我们为什么在函数出错时,查看errno的原因,而且必须立即查看。最多可以传递3个参数。
该文件还声明了一些库函数的原型:
int access(const char * filename, mode_t mode);
int acct(const char * filename);
int alarm(int sec);
int brk(void * end_data_segment);
void * sbrk(ptrdiff_t increment);
int chdir(const char * filename);
int chmod(const char * filename, mode_t mode);
int chown(const char * filename, uid_t owner, gid_t group);
int chroot(const char * filename);
int close(int fildes);
int creat(const char * filename, mode_t mode);
int dup(int fildes);
int execve(const char * filename, char ** argv, char ** envp);
int execv(const char * pathname, char ** argv);
int execvp(const char * file, char ** argv);
int execl(const char * pathname, char * arg0, ...);
int execlp(const char * file, char * arg0, ...);
int execle(const char * pathname, char * arg0, ...);
volatile void exit(int status);
volatile void _exit(int status);
int fcntl(int fildes, int cmd, ...);
int fork(void);
int getpid(void);
int getuid(void);
int geteuid(void);
int getgid(void);
int getegid(void);
int ioctl(int fildes, int cmd, ...);
int kill(pid_t pid, int signal);
int link(const char * filename1, const char * filename2);
int lseek(int fildes, off_t offset, int origin);
int mknod(const char * filename, mode_t mode, dev_t dev);
int mount(const char * specialfile, const char * dir, int rwflag);
int nice(int val);
int open(const char * filename, int flag, ...);
int pause(void);
int pipe(int * fildes);
int read(int fildes, char * buf, off_t count);
int setpgrp(void);
int setpgid(pid_t pid,pid_t pgid);
int setuid(uid_t uid);
int setgid(gid_t gid);
void (*signal(int sig, void (*fn)(int)))(int);
int stat(const char * filename, struct stat * stat_buf);
int fstat(int fildes, struct stat * stat_buf);
int stime(time_t * tptr);
int sync(void);
time_t time(time_t * tloc);
time_t times(struct tms * tbuf);
int ulimit(int cmd, long limit);
mode_t umask(mode_t mask);
int umount(const char * specialfile);
int uname(struct utsname * name);
int unlink(const char * filename);
int ustat(dev_t dev, struct ustat * ubuf);
int utime(const char * filename, struct utimbuf * times);
pid_t waitpid(pid_t pid,int * wait_stat,int options);
pid_t wait(int * wait_stat);
int write(int fildes, const char * buf, off_t count);
int dup2(int oldfd, int newfd);
int getppid(void);
pid_t getpgrp(void);
pid_t setsid(void);这也是我们使用系统调用时包含头文件unistd.h的原因。
2.2 include/linux/sys.h文件
include/linux/sys.h(p407)文件中定义了72个内核态下的系统调用实际调用的函数,都是以sys_开头,以及系统调用指针数组:
extern int sys_setup();
extern int sys_exit();
extern int sys_fork();
extern int sys_read();
extern int sys_write();
extern int sys_open();
extern int sys_close();
extern int sys_waitpid();
extern int sys_creat();
extern int sys_link();
extern int sys_unlink();
extern int sys_execve();
extern int sys_chdir();
extern int sys_time();
extern int sys_mknod();
extern int sys_chmod();
extern int sys_chown();
extern int sys_break();
extern int sys_stat();
extern int sys_lseek();
extern int sys_getpid();
extern int sys_mount();
extern int sys_umount();
extern int sys_setuid();
extern int sys_getuid();
extern int sys_stime();
extern int sys_ptrace();
extern int sys_alarm();
extern int sys_fstat();
extern int sys_pause();
extern int sys_utime();
extern int sys_stty();
extern int sys_gtty();
extern int sys_access();
extern int sys_nice();
extern int sys_ftime();
extern int sys_sync();
extern int sys_kill();
extern int sys_rename();
extern int sys_mkdir();
extern int sys_rmdir();
extern int sys_dup();
extern int sys_pipe();
extern int sys_times();
extern int sys_prof();
extern int sys_brk();
extern int sys_setgid();
extern int sys_getgid();
extern int sys_signal();
extern int sys_geteuid();
extern int sys_getegid();
extern int sys_acct();
extern int sys_phys();
extern int sys_lock();
extern int sys_ioctl();
extern int sys_fcntl();
extern int sys_mpx();
extern int sys_setpgid();
extern int sys_ulimit();
extern int sys_uname();
extern int sys_umask();
extern int sys_chroot();
extern int sys_ustat();
extern int sys_dup2();
extern int sys_getppid();
extern int sys_getpgrp();
extern int sys_setsid();
extern int sys_sigaction();
extern int sys_sgetmask();
extern int sys_ssetmask();
extern int sys_setreuid();
extern int sys_setregid();
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid
};其中,fn_ptr定义在include/linux/sched.h(p401)的第40行:
typedef int (*fn_ptr)();
表示一种int function_name()的函数地址类型,从上述的函数中可以看出并没有对应任何参数,但实际sys_exit等可能不止一个参数,这里主要是为了与调用表相对应。这些系统调用函数与上面系统调用号是一一对应的,内核需要实现的便是这些以sys_开头的函数,开放给用户使用的入口便是int 0x80系统调用。
2.3 内核库函数的实现
在lib下,有多个内核库函数的实现,大部分使用了_syscallx嵌入式宏来实现的,例如lib\write.c(p429),定义了write:
#define __LIBRARY__
#include
_syscall3(int,write,int,fd,const char *,buf,off_t,count)
显然,宏展开后将变为:
int write(int fd, const char* buf, off_t count)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_##write),"b" ((long)(fd)),"c" ((long)(buf)),"d" ((long)(count)));
if (__res>=0)
return (int) __res;
errno=-__res;
return -1;
}注意:这里在开头预先定义了一个宏,__LIBRARY__使得_syscall3和__NR_write有定义。
三、128号系统中断
3.1 system_call函数
在kernel/sched.c(p103)的第411行,绑定了系统调用的处理函数:
set_system_gate(0x80,&system_call);
其中,system_call位于kernel/system_call.s(p86)的第80行:
system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
ret_from_sys_call:
movl current,%eax # task[0] cannot have signals
cmpl task,%eax
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
call do_signal
popl %eax
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret该函数首先检查调用号是否超出界限,然后保存参数到堆栈中,将数据段和扩展段改为内核数据段,将FS设置为用户数据段。然后调用系统调用表中的对应的函数,并将返回结果保存到堆栈中。在返回时首先检查当前进程是否处于可执行状态且时间片未用完,否则将切换,回来时将继续往下执行。最后返回时如果发现系统调用发生时处于用户态,则检查当前进程的信号位图,并对信号进行处理。然后返回用户态,可能要先执行信号句柄。
3.2 sys_函数执行前的堆栈
首先,在用户态下使用int 0x80,将切换到内核态,使用进程内核态的堆栈,该堆栈位于进程控制块的末端,最多是一页内存。开始执行system_call前的堆栈的内容为:
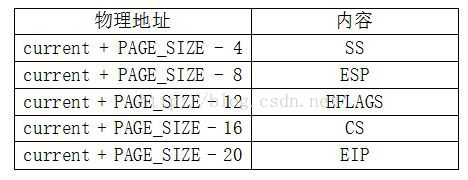
此时SS = 0x10, SP = current + PAGE_SIZE - 20
在调用sys_函数前,堆栈变为:
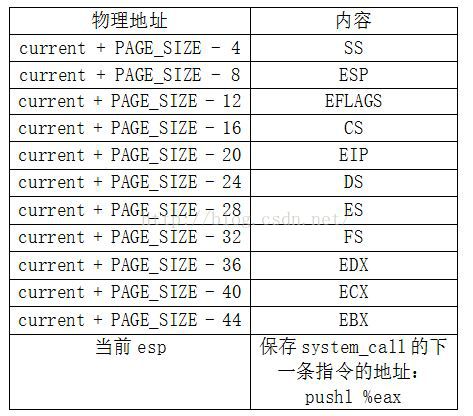
然后DS、ES指向内核数据段,FS指向用户数据段。此时SP = current + PAGE_SIZE - 44。并调用相应的sys_函数:
call sys_call_table(,%eax,4)
其中eax保存的是调用号,第三个参数4表示eax * 4,值为sys_call_table + eax * 4。如果没有则默认第三个参数是1。也就是说,上述场景将是sys_函数执行时的上下文,所有sys_函数都认为FS是用户数据段,而DS,ES都是内核数据段。
3.3 sys_fork函数的执行
sys_fork的定义在kernel/system_call.s的第208行(p89):
.align 2
sys_fork:
call find_empty_process
testl %eax,%eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call copy_process
addl $20,%esp
1: ret它首先调用find_empty_process,位于kernel/fork.c的第135行(p115):
int find_empty_process(void)
{
int i;
repeat:
if ((++last_pid)<0) last_pid=1;
for(i=0 ; ipid == last_pid) goto repeat;
for(i=1 ; i 该函数主要首先获取还没有使用的进程ID,并保存到last_pid中,该last_pid就是独一无二的,没被当前系统任何进程使用。然后再找一个进程号,也就是没被使用的进程下标,然后返回进程号。该进程号保存在eax中,如果符号位为1,返回值是负数,则直接返回出错。否则将调用copy_process,该函数开始执行时,堆栈映像如下:

copy_process函数位于kernel/fork.c第68行(p114):
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
__asm__ volatile ("cld");
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;
p->father = current->pid;
p->counter = p->priority;
p->signal = 0;
p->alarm = 0;
p->leader = 0; /* process leadership doesn't inherit */
p->utime = p->stime = 0;
p->cutime = p->cstime = 0;
p->start_time = jiffies;
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
p->tss.eip = eip;
p->tss.eflags = eflags;
p->tss.eax = 0;
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff;
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr);
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current)
__asm__("clts ; fnsave %0"::"m" (p->tss.i387));
if (copy_mem(nr,p))
{
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
for (i=0; ifilp[i]))
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid;
} 该函数首先使用get_free_page获得一页未使用的内存,作为任务控制块使用,由于是在内核空间中,且基地址为0,所以得到的地址即为物理地址。然后拷贝当前进程的任务控制块作为副本,并将新建的任务的状态设置为不可中断,这样方便对控制块和任务状态段进行修改。
新任务的进程ID修改为last_pid。
父进程ID修改为current->pid。
时间片修改为15个滴答。
信号位图、警报时间、领导权、用户态和内核态运行时间、子进程用户态和内核态运行时间均设置为0。
然后对TSS中的相关字段进行修改,将进程的内核态堆栈修改为任务控制块的末端,EIP指向为int 0x80的下一条地址,EAX设置为0,这是子进程fork之后返回0的原因。copy_process传递进来的参数除了nr和none以外都用来初始化新进程的TSS,这些参数都是父进程fork之前的状态,结束之后都将用于恢复现场。由于当前进程并未运行,且加载时所有寄存器的值都将来自TSS,当子进程被调度时,将直接运行int 0x80的下一条指令,处于用户态下的库函数里,堆栈为到int 0x80这条指令为止的用户态下的堆栈,所以要求int 0x80之前尽量不要有函数调用。得到的返回值为0。内核提供的库函数fork中,使用inline的形式,来避免函数调用,保证用户态堆栈的干净。
init/main.c第23行(p63)中,有
inline _syscall0(int,fork) __attribute__((always_inline));
对于0进程fork出进程1,需要进程0的用户态堆栈足够干净,也就是user_stack足够干净。
新建立的进程将利用任务号建立对应的代码段和数据段基地址,并设置LDT中的基地址,LDT选择子重新设置。复制页表到新的页表,也就是使用相同的页,使用的是写时复制。同时,打开的文件指针、可执行文件、进程的根目录、当前根目录的引用计数将增加,最后设置在GDT中设置TSS和LDT的地址,设置新进程为可运行状态,返回子进程的ID。这些工作都是由父进程完成的,子进程一直未被调度。
新进程代码段和数据段的基地址为NR * 64MB,GDT中的表项为gdt + NR * 2 + FIRST_TSS_ENTRY, gdt + NR * 2 + FIRST_LDT_ENTRY,控制块为task[NR]。
3.4 sys_execve函数的执行
sys_execve定义在kernel/system_call.s的第200行(p88):
sys_execve:
lea EIP(%esp),%eax
pushl %eax
call do_execve
addl $4,%esp
ret对于sys_execve而言,其参数已经保存了(当前堆栈上的ebx,ecx,edx),该函数调用的实际函数是do_execve,其看到的堆栈为

其中do_execve函数位于fs/exec.c第182行(p318),在第344和345行,对堆栈中的EIP和ESP进行了修改:
eip[0] = ex.a_entry; /* eip, magic happens :-) */
eip[3] = p; /* stack pointer */
也就是说,之后系统调用之后不会执行int 0x80下面那条语句,而是执行刚加载的代码,而且参数已经在栈中。这时main函数的形式参数(argc, argv)已经存在,直接跳到main函数执行。
int do_execve(unsigned long * eip,long tmp,char * filename, char ** argv, char ** envp)
{
struct m_inode * inode;
struct buffer_head * bh;
struct exec ex;
unsigned long page[MAX_ARG_PAGES];
int i,argc,envc;
int e_uid, e_gid;
int retval;
int sh_bang = 0;
unsigned long p=PAGE_SIZE*MAX_ARG_PAGES-4;
if ((0xffff & eip[1]) != 0x000f)
panic("execve called from supervisor mode");
for (i=0 ; ii_mode)) /* must be regular file */
{
retval = -EACCES;
goto exec_error2;
}
i = inode->i_mode;
e_uid = (i & S_ISUID) ? inode->i_uid : current->euid;
e_gid = (i & S_ISGID) ? inode->i_gid : current->egid;
if (current->euid == inode->i_uid)
i >>= 6;
else if (current->egid == inode->i_gid)
i >>= 3;
if (!(i & 1) &&
!((inode->i_mode & 0111) && suser()))
{
retval = -ENOEXEC;
goto exec_error2;
}
if (!(bh = bread(inode->i_dev,inode->i_zone[0])))
{
retval = -EACCES;
goto exec_error2;
}
ex = *((struct exec *) bh->b_data); /* read exec-header */
if ((bh->b_data[0] == '#') && (bh->b_data[1] == '!') && (!sh_bang))
{
/*
* This section does the #! interpretation.
* Sorta complicated, but hopefully it will work. -TYT
*/
char buf[1023], *cp, *interp, *i_name, *i_arg;
unsigned long old_fs;
strncpy(buf, bh->b_data+2, 1022);
brelse(bh);
iput(inode);
buf[1022] = '\0';
if ((cp = strchr(buf, '\n')))
{
*cp = '\0';
for (cp = buf; (*cp == ' ') || (*cp == '\t'); cp++);
}
if (!cp || *cp == '\0')
{
retval = -ENOEXEC; /* No interpreter name found */
goto exec_error1;
}
interp = i_name = cp;
i_arg = 0;
for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++)
{
if (*cp == '/')
i_name = cp+1;
}
if (*cp)
{
*cp++ = '\0';
i_arg = cp;
}
/*
* OK, we've parsed out the interpreter name and
* (optional) argument.
*/
if (sh_bang++ == 0)
{
p = copy_strings(envc, envp, page, p, 0);
p = copy_strings(--argc, argv+1, page, p, 0);
}
/*
* Splice in (1) the interpreter's name for argv[0]
* (2) (optional) argument to interpreter
* (3) filename of shell script
*
* This is done in reverse order, because of how the
* user environment and arguments are stored.
*/
p = copy_strings(1, &filename, page, p, 1);
argc++;
if (i_arg)
{
p = copy_strings(1, &i_arg, page, p, 2);
argc++;
}
p = copy_strings(1, &i_name, page, p, 2);
argc++;
if (!p)
{
retval = -ENOMEM;
goto exec_error1;
}
/*
* OK, now restart the process with the interpreter's inode.
*/
old_fs = get_fs();
set_fs(get_ds());
if (!(inode=namei(interp))) /* get executables inode */
{
set_fs(old_fs);
retval = -ENOENT;
goto exec_error1;
}
set_fs(old_fs);
goto restart_interp;
}
brelse(bh);
if (N_MAGIC(ex) != ZMAGIC || ex.a_trsize || ex.a_drsize ||
ex.a_text+ex.a_data+ex.a_bss>0x3000000 ||
inode->i_size < ex.a_text+ex.a_data+ex.a_syms+N_TXTOFF(ex))
{
retval = -ENOEXEC;
goto exec_error2;
}
if (N_TXTOFF(ex) != BLOCK_SIZE)
{
printk("%s: N_TXTOFF != BLOCK_SIZE. See a.out.h.", filename);
retval = -ENOEXEC;
goto exec_error2;
}
if (!sh_bang)
{
p = copy_strings(envc,envp,page,p,0);
p = copy_strings(argc,argv,page,p,0);
if (!p)
{
retval = -ENOMEM;
goto exec_error2;
}
}
/* OK, This is the point of no return */
if (current->executable)
iput(current->executable);
current->executable = inode;
for (i=0 ; i<32 ; i++)
current->sigaction[i].sa_handler = NULL;
for (i=0 ; iclose_on_exec>>i)&1)
sys_close(i);
current->close_on_exec = 0;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
if (last_task_used_math == current)
last_task_used_math = NULL;
current->used_math = 0;
p += change_ldt(ex.a_text,page)-MAX_ARG_PAGES*PAGE_SIZE;
p = (unsigned long) create_tables((char *)p,argc,envc);
current->brk = ex.a_bss +
(current->end_data = ex.a_data +
(current->end_code = ex.a_text));
current->start_stack = p & 0xfffff000;
current->euid = e_uid;
current->egid = e_gid;
i = ex.a_text+ex.a_data;
while (i&0xfff)
put_fs_byte(0,(char *) (i++));
eip[0] = ex.a_entry; /* eip, magic happens :-) */
eip[3] = p; /* stack pointer */
return 0;
exec_error2:
iput(inode);
exec_error1:
for (i=0 ; i 这个函数首先计算参数argv、envp字符串的个数,这两个变量都是字符串指针数组,以NULL结尾。然后根据当前进程的有效用户ID是否为这个可执行文件的属主,有效用户组ID是否为这个可执行文件的属组,或者是其他成员,来确定是否有执行权限。如果当前用户没有执行权限,但却是超级用户,且三种情况中至少有一个执行权限,则可以执行。否则不可以执行。然后读取可执行文件的第一个数据块(1kB),判断是否为脚本文件。如果不是脚本文件则得到可执行文件头,对可执行文件头判断是否合法。
如果是脚本文件(前两个字符#!),则将envp里面的数组的最后一项从32页物理内存的末端(最后的4个字节不用)开始复制字符串(包含0结尾),字符串也是从后往前开始复制,然后将第一个参数去掉,将参数也类似复制,再将脚本文件名复制,并将传递给解释文件(如/bin/bash)的参数串复制(如果有,脚本文件的第一行),将解释文件的文件名复制(不是路径,如bash)。最后读取解释文件,并读取其解释文件(/bin/bash)的可执行文件头,不用再传递参数,开始执行解释文件(/bin/bash)。
如果是一般的可执行文件,则也复制参数,但不去掉第一个参数。
然后将当前进程的旧的可执行节点释放,并指向新的可执行节点,去掉所有从父进程继承过来的信号句柄,并置为默认。然后将部分从父进程继承过来的打开的文件句柄关闭,即将当前close_on_exec中置位的文件句柄关闭。然后close_on_exec清零。接着释放旧的内存页和页表,将LDT中代码段的段长设置为可执行文件中的代码段段长(向上取整,以PAGE_SIZE为基准),将数据段段长设置为64MB。并将设置的参数物理页(最多32页)映射到进程地址空间的末端(64MB * (NR + 1) - 4KB开始,往低地址处走一页一页映射),作为进程的堆栈。接着将每个环境变量的地址继续放到堆栈中,并以NULL指针结束。将参数变量也这么做。最后放置argc,argv,envp的值,表示字符串指针数组的起始位置。这样得到的堆栈指针即为开始时的指针。再设置进程的末尾brk = ex.a_text + ex.a_data + ex.a_bss,初始化最多一页内存,且值为0。重新设置代码入口地址和栈顶。

count函数的工作是计算这个二维指针数组有多少个字符串,计算的依据是以NULL结尾为标志数组结束的。char* p[] = {“HOME=/”, “PATH=/bin”, “CLASSPATH=.”, “hello”, NULL},上述共有4个字符串。
copy_strings这个函数的工作便是把这些字符串(包含0)整理到一维数组中,且一般是从用户空间到内核空间:

create_tables函数的作用是把字符串的起始地址放到字符串所在的数组中,并加入NULL,最后再把字符串指针数组的首地址以及个数放入数组中:
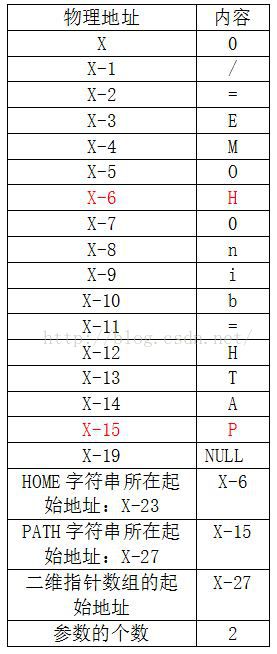
注意:上述两幅图中的PATH和HOME位置必须交换才是正确的。
而对于do_execve()来说,其主要的工作在于布置参数,其堆栈最终结果如下,这也是(启动/bin/bash进程进行解释)或者普通可执行文件开始执行时看到的用户态堆栈,注意堆栈向低地址生长:

由此,我们可以得到进程的地址空间为:
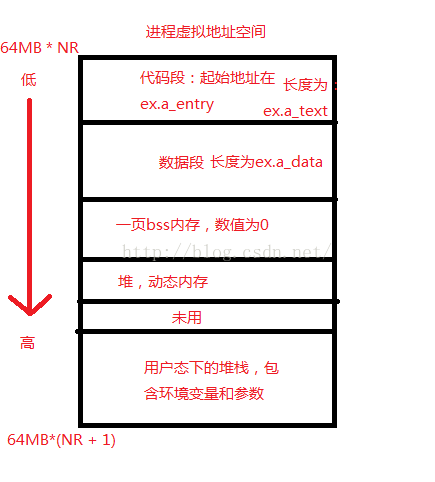
在do_execve函数中,还出现了一些字符串库函数的使用,如strncpy和strchr函数,这两个函数均位于include/string.h(p364)中,strncpy在第38行,strchr在第128行,这两个函数要求DS和ES指向相同的数据空间,如同时是内核空间,或者同时是用户态空间。
static inline char * strncpy(char * dest,const char *src,int count)
{
__asm__("cld\n"
"1:\tdecl %2\n\t"
"js 2f\n\t"
"lodsb\n\t"
"stosb\n\t"
"testb %%al,%%al\n\t"
"jne 1b\n\t"
"rep\n\t"
"stosb\n"
"2:"
::"S" (src),"D" (dest),"c" (count));
return dest;
}
static inline char * strchr(const char * s,char c)
{
register char * __res ;
__asm__("cld\n\t"
"movb %%al,%%ah\n"
"1:\tlodsb\n\t"
"cmpb %%ah,%%al\n\t"
"je 2f\n\t"
"testb %%al,%%al\n\t"
"jne 1b\n\t"
"movl $1,%1\n"
"2:\tmovl %1,%0\n\t"
"decl %0"
:"=a" (__res):"S" (s),"0" (c));
return __res;
}注意这两个函数中地址与寄存器的对应关系,说明地址其实是虚拟地址(还需要段寄存器或者段描述符来指定所在的段),而且是标号,是一个符号。
3.5 do_signal函数的执行
sys_函数执行后,system_call将会把返回值(eax)保存到栈中,如果当前进程时间片结束,或者处于非可运行状态,则切换进程。但不管怎样,都会执行ret_from_sys_call标号处的结束代码(被切换进程再度执行时也会执行)。如果发生系统调用时处于内核态,则直接结束。否则检查当前进程的信号位图,去掉被阻塞的部分,从低位开始检查是否有置位,有则复位,并调用do_signal函数。最后使用iret结束。
对于do_signal,其看到的内核态堆栈内容为:
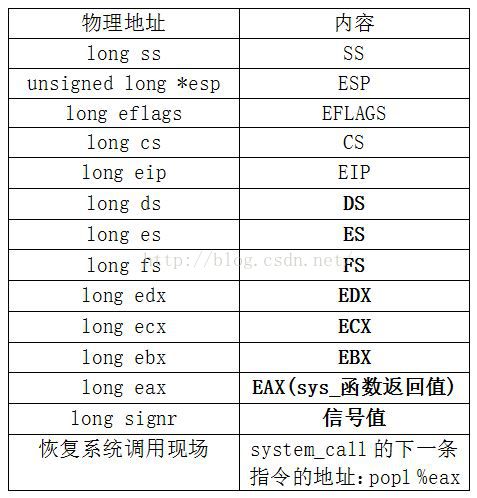
do_signal执行完后,把信号值弹出,并把相应的寄存器弹出,上图加粗的部分。do_signal函数位于kernel/signal.c的第82行(p106)的函数原型:
void do_signal(long signr,long eax, long ebx, long ecx, long edx,
long fs, long es, long ds,
long eip, long cs, long eflags,
unsigned long * esp, long ss)
{
unsigned long sa_handler;
long old_eip=eip;
struct sigaction * sa = current->sigaction + signr - 1;
int longs;
unsigned long * tmp_esp;
sa_handler = (unsigned long) sa->sa_handler;
if (sa_handler==1)
return;
if (!sa_handler)
{
if (signr==SIGCHLD)
return;
else
do_exit(1<<(signr-1));
}
if (sa->sa_flags & SA_ONESHOT)
sa->sa_handler = NULL;
*(&eip) = sa_handler;
longs = (sa->sa_flags & SA_NOMASK)?7:8;
*(&esp) -= longs;
verify_area(esp,longs*4);
tmp_esp=esp;
put_fs_long((long) sa->sa_restorer,tmp_esp++);
put_fs_long(signr,tmp_esp++);
if (!(sa->sa_flags & SA_NOMASK))
put_fs_long(current->blocked,tmp_esp++);
put_fs_long(eax,tmp_esp++);
put_fs_long(ecx,tmp_esp++);
put_fs_long(edx,tmp_esp++);
put_fs_long(eflags,tmp_esp++);
put_fs_long(old_eip,tmp_esp++);
current->blocked |= sa->sa_mask;
}由于C语言约定参数从后往前入栈,由调用者清理堆栈,可以看出这些参数都已经为do_signal的执行准备好。在include/signal.h的第45行(p361)中,定义了信号默认处理句柄和忽视句柄:
#define SIG_DFL ((void (*)(int))0) /* default signal handling */
#define SIG_IGN ((void (*)(int))1) /* ignore signal */
这里首先是判断当前信号对应的函数句柄是否为1,若是则忽视,不做任何事情。然后判断是否为默认句柄,若是则除了SIGCHLD忽视,其他信号均终止进程的执行。
sigaction定义在include/signal.h的第48行(p361):
struct sigaction
{
void (*sa_handler)(int);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};其中sa_restorer用于清理用户态堆栈参数。
开始时,任务0的信号句柄均为0,表示默认处理。当前信号可以捕获时,如果在sa->sa_flags中设置了SA_ONESHOT则该句柄执行一次之后,就会恢复为默认值(通过获取该句柄的地址,对其值设置为0)。这里主要是修改int 0x80后执行的下一条指令为函数句柄,在用户态堆栈下添加参数(使用put_fs_long在内核态下向用户空间写数据),并修改用户态下的堆栈指针,为信号句柄的执行提供环境。并将当前句柄的屏蔽码添加到current->blocked中,这样当信号再次被调用时相关信号将被阻塞,不做处理。这样可以避免重入,因为信号是异步发生的。
假设没有sa->sa_flags为0,也就是SA_NOMASK没有置位,禁止信号重入。这时为信号句柄设置的用户态堆栈将占用8 x 4个字节,而且所有变量都是从内核态栈复制到用户态栈:

注意:上图old_eip <=> int 0x80下一条指令的地址,且old_esp 指在old_eip的上一个变量。
内核态堆栈映像:
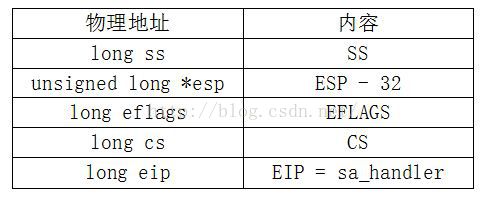
所以系统调用返回后,将在用户态下首先执行该信号的函数句柄,然后再继续执行系统调用之后的指令,开始正常运行。