Fluid: 让大数据和 AI 拥抱云原生的一块重要拼图

作者 | 顾荣、车漾、范斌
得益于容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的 AI 与大数据应用在其上部署和运行。然而,云原生计算基金会(CNCF)全景图中一直缺失一款原生组件,以帮助这些数据密集型应用在云原生场景下高效、安全、便捷地访问数据。
如何驱动大数据、AI 应用在云原生场景下高效运行是一个既有理论意义又具应用价值的重要挑战性问题:
-
一方面,解决该问题需考虑复杂场景下应用协同编排、调度优化、数据缓存等一系列理论与技术难题;
-
另一方面,该问题的解决能够有力地推动广阔云服务场景下的大数据、AI 落地应用。
为系统化解决相关问题,学术界和工业界密切合作,南京大学 PASALab 副研究员顾荣博士、阿里云容器服务高级技术专家车漾、Alluxio 项目创始成员范斌博士联合推动发起了 Fluid开源合作项目。
Fluid 是什么?
Fluid 是一款开源的云原生基础架构项目。在计算和存储分离的大背景驱动下,Fluid 的目标是为 AI 与大数据云原生应用提供一层高效便捷的数据抽象,将数据从存储抽象出来,以便达到:
-
通过数据亲和性调度和分布式缓存引擎加速,实现数据和计算之间的融合,从而加速计算对数据的访问;
-
将数据独立于存储进行管理,并且通过Kubernetes的命名空间进行资源隔离,实现数据的安全隔离;
-
将来自不同存储的数据联合起来进行运算,从而有机会打破不同存储的差异性带来的数据孤岛效应。
通过 Kubernetes 服务提供的数据层抽象,可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源和 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。而具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题。用户只需以最自然的 Kubernetes 原生数据卷方式直接访问抽象出来的数据,剩余任务和底层细节全部交给 Fluid 处理。
Fluid 项目当前主要关注数据集编排和应用编排这两个重要场景。数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点;而应用编排将指定该应用调度到可以或已经存储了指定数据集的节点上。这两者还可以组合形成协同编排场景,即协同考虑数据集和应用需求进行节点资源调度。
为什么云原生需要 Fluid?
云原生环境与更早出现的大数据处理框架在设计理念和机制上存在天然分歧。深受 Google 三篇论文 GFS、MapReduce、BigTable 影响的 Hadoop 大数据生态,从诞生之初即信奉和实践“移动计算而不是数据”的理念。因此以 Spark,Hive,MapReduce 为代表的数据密集型计算框架及其应用为减少数据传输,其设计更多地考虑数据本地化架构。但随着时代的变迁,为兼顾资源扩展的灵活性与使用成本,计算和存储分离的架构在更新兴的云原生环境中大行其道。因此云原生环境里需要类似 Fluid 这样的一款组件来补充大数据框架拥抱云原生带来的数据本地性缺失。
此外,在云原生环境中,应用通常以无状态(Stateless)微服务化方式部署,并不以数据处理为中心;而数据密集型框架和应用通常以数据抽象为中心,开展相关计算作业和任务的分配执行。当数据密集型框架融入云原生环境后,也需要像 Fluid 这样以数据抽象为中心的调度和分配框架来协同工作。
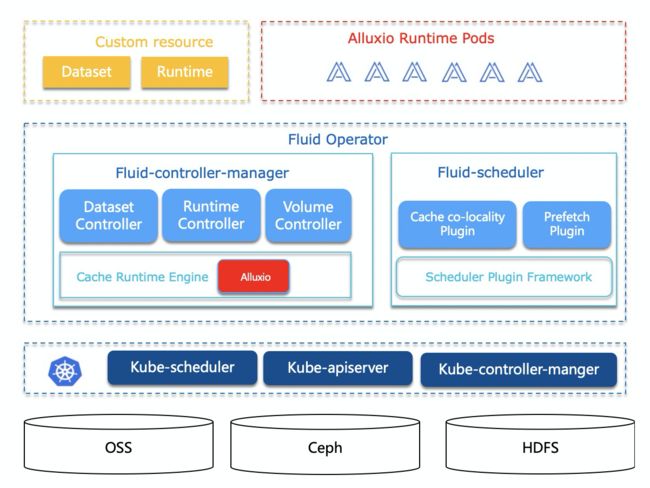
针对 Kubernetes 缺乏对应用数据的智能感知和调度优化的问题,及以 Alluxio 为例的数据编排引擎存在难以直接管控云原生基础架构层的局限,Fluid 提出数据应用协同编排、智能感知、联合优化等一系列创新方法,并且形成一套云原生场景下数据密集型应用的高效支撑平台。
具体的架构参见下图:
演示
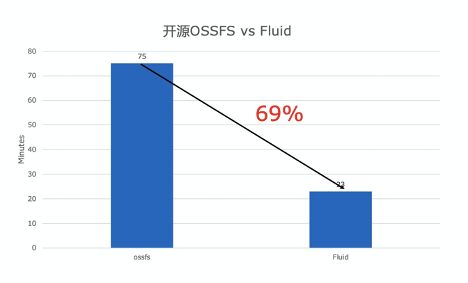
我们提供了视频的 Demo,为您展示如何通过 Fluid 提升云上 AI 模型训练的速度。在这个 Demo 中,使用同样的 ResNet50 测试代码,Fluid 加速和原生的 ossfs 直接访问相比,不论在每秒钟的训练速度,和训练总时长相比都有明显的优势,训练耗时缩短了 69%。
点击链接,即可查看视频 Demo:https://v.qq.com/x/page/t31488r2p2q.html
快速体验 Fluid
Fluid 需要运行在 Kubernetes v1.14 及以上版本,并且需要支持 CSI 存储。Fluid Operator 的部署和管理是通过 Kubernetes 平台上的包管理工具 Helm v3 实现的。运行 Fluid 前请确保 Helm 已经正确安装在 Kubernetes 集群里。你可以参照文档,安装和使用 Fluid。
欢迎加入与反馈
Fluid 让 Kubernetes 真正具有分布式数据缓存的基础能力,开源只是一个起点,需要大家的共同参与。大家在使用过程发现 bug 或需要的 feature,都可以直接在 GitHub 上面提 issue 或 PR,一起参与讨论。
另外我们有一个钉钉群,手机端钉钉点击超链即可加入,欢迎您的参与和讨论!
作者简介
顾荣 南京大学计算机系副研究员,研究方向大数据处理系统,已在 TPDS、ICDE、Parallel Computing、JPDC、IPDPS、ICPP 等领域前沿期刊会议发表论文20余篇,成果落地应用于中国石化、百度、字节跳动等公司和开源项目Apache Spark,获 2018 年度江苏省科学技术一等奖、2019 年度江苏省计算机学会青年科技奖,当选中国计算机学会系统软件专委会委员/大数据专委会通讯委员、江苏省计算机学会大数据专委会秘书长;
车漾 阿里云高级技术专家,从事 Kubernetes 和容器相关产品的开发。尤其关注利用云原生技术构建机器学习平台系统,是 GPU 共享调度的主要作者和维护者;
范斌 Alluxio 开源项目的管理委员会成员(PMC Member)和源码维护者(Maintianer)。加入 Alluxio 项目之前, 范斌就职于谷歌, 从事下一代大规模分布式存储系统的研究与开发。他于 2013 年获得卡内基梅隆大学(Carnegie Mellon University)计算机系博士学位,博士期间从事分布式系统的设计与实现,是 Cuckoo Filter 的作者。
“阿里巴巴云原生:关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”