python面试问题_Python面试问题
python面试问题
Python is the top most programming language these days. I have wrote a lot of python tutorials, here I am providing Python Interview Questions and Answers that will help you in python interview. These python interview questions are good for beginners as well as experienced programmers. There are coding questions too to brush up your coding skills.
如今,Python是最主要的编程语言。 我已经写了很多python教程,在这里我提供了Python面试问答,这将帮助您进行python面试。 这些python面试问题对初学者和经验丰富的程序员都非常有用。 还有一些编码问题可以提高您的编码技能。
Python面试问题 (Python Interview Questions)

Python is getting a lot of attention, specially in the field of data science, pen testing, scientific and mathematical algorithm development, machine learning, artificial intelligence etc.
Python引起了很多关注,特别是在数据科学,笔测试,科学和数学算法开发,机器学习,人工智能等领域。
I have been working on Python for more than 5 years now, all these python interview questions are coming from my learning on the job as well as the interviews I have taken for Python developers role. You should bookmark this post as I will keep on adding more interview questions to this list in future.
我从事Python已有5年以上的经验,所有这些Python面试问题都来自我在工作中的学习以及我为Python开发人员所进行的面试。 您应该将此帖子添加为书签,因为以后我将继续在此列表中添加更多面试问题。
- What is Python? What are the benefits of using Python? 什么是Python? 使用Python有什么好处?
- What is Python? What are the benefits of using Python? 什么是Python? 使用Python有什么好处?
- What is PEP 8? 什么是PEP 8?
- What are the differences between Python 2.x and Python 3.x? Python 2.x和Python 3.x有什么区别?
- Why do you need to make your code more readable? 为什么需要使代码更具可读性?
- How many Keywords are there in Python? And why should we know them? Python中有几个关键字? 为什么我们要认识他们?
- What are the built-in data-types in Python? Python中内置的数据类型是什么?
- How many types of operators Python has? Give brief idea about them Python有几种类型的运算符? 简要介绍一下它们
- What is the output of the following code and why? 以下代码的输出是什么,为什么?
- What is PEP 8? 什么是PEP 8?
- What should be the output of the following code and why? 以下代码的输出应该是什么,为什么?
- What is the statement that can be used in Python if the program requires no action but requires a statement syntactically? 如果程序不需要任何操作但需要语法上的语句,那么在Python中可以使用什么语句?
- What are the advantages of Python Recursion? Python递归的优点是什么?
- What are the disadvantages of Python Recursion? Python递归的缺点是什么?
- What is lambda in python? 什么是python中的lambda?
- Why don’t Python lambda have any statement? 为什么Python lambda没有任何声明?
- What do you understand by Python Modules? 您对Python模块了解什么?
- A module print_number given, what will be the output of the following code? 给定一个模块print_number,以下代码的输出是什么?
- What do you understand by Python Package? 您对Python软件包了解什么?
- What will be the output of the following code? 以下代码的输出是什么?
- Will this code output any error? Explain. 此代码会输出任何错误吗? 说明。
- What will be the output of the following code? 以下代码的输出是什么?
- What will be the output of the following code2? Explain 以下代码2的输出是什么? 说明
- What is namespace in Python? Python中的命名空间是什么?
- Why do we need Python Directories 为什么我们需要Python目录
- How to get current directory using Python? 如何使用Python获取当前目录?
- Why Should We Use File Operation? 为什么要使用文件操作?
- Why should we close files? 为什么要关闭文件?
- What are python dictionaries? 什么是python词典?
- What are the differences between del keyword and clear() function? del关键字和clear()函数之间有什么区别?
- What is Python Set? 什么是Python集?
- How will you convert a string to a set in python? 您将如何在python中将字符串转换为集合?
- What a blank curly brace initialize? A dictionary or a set? 空白花括号初始化什么? 字典还是一组?
- Explain split() and join() function. 解释split()和join()函数。
- What is Python Decorator? 什么是Python Decorator?
- What do you understand by Python Generator? 您对Python生成器了解什么?
- What do you understand by Python iterator and Iterable elements? 您对Python迭代器和Iterable元素了解什么?
- What do you know about iterator protocol? 您对迭代器协议了解多少?
- What will be output of the following code? Explain (Python Inheritance) 以下代码将输出什么? 解释(Python继承)
- Why do we need operator overloading? 为什么我们需要运算符重载?
- What is the difference between tuples and lists in Python? Python中的元组和列表有什么区别?
- How to compare two list? 如何比较两个清单?
- How can you sort a list? 您如何排序列表?
- How can you sort a list in reverse order? 如何以相反的顺序对列表进行排序?
- How will you remove all leading and trailing whitespace in string? 如何删除字符串中的所有前导和尾随空格?
- How can you pick a random item from a list or tuple? 如何从列表或元组中选择随机项目?
- How will you change case for all letters in string? 您如何更改字符串中所有字母的大小写?
- In Python what is slicing? 在Python中,切片是什么?
- How will you get a 10 digit zero-padded number from an original number? 您如何从原始号码中获得10位零填充数字?
- What is negative index in Python? Python中的负索引是什么?
Python面试问答 (Python Interview Questions and Answers)
什么是Python? 使用Python有什么好处? (What is Python? What are the benefits of using Python?)
Python is a high level object-oriented programming language. There are many benefits of using Python. Firstly, Python scripts are simple, shorter, portable and open-source. Secondly, Python variables are dynamic typed. So you don’t need to think about variable type while coding. Thirdly, Python classes has no access modifiers which Java have. So, you don’t need to think about access modifiers. Lastly, Python provides us different library, data-structure to make our coding easier.
Python是一种高级的面向对象的编程语言。 使用Python有很多好处。 首先,Python脚本简单,简短,可移植且开源。 其次,Python变量是动态类型的。 因此,您在编码时无需考虑变量类型。 第三,Python类没有Java具有的访问修饰符。 因此,您无需考虑访问修饰符。 最后,Python为我们提供了不同的库,数据结构,使我们的编码更加容易。
Python是否使用解释器或编译器? 编译器和解释器有什么区别? (Does Python use interpreter or compiler? What’s the difference between compiler and interpreter?)
Python uses interpreter to execute its scripts. The main difference between an interpreter and a compiler is, an interpreter translates one statement of the program to machine code at a time. Whereas, a compiler analyze the whole script and then translate it to machine code. For that reason the execution time of whole code executed by an interpreter is more than the code executed by compiler.
Python使用解释器执行其脚本。 解释器和编译器之间的主要区别是,解释器一次将程序的一条语句转换为机器代码。 而编译器会分析整个脚本,然后将其转换为机器代码。 因此,解释器执行的全部代码的执行时间比编译器执行的代码的执行时间更长。
什么是PEP 8? (What is PEP 8?)
Basically PEP 8 is a style guide for coding convention and suggestion. The main objective of PEP 8 is to make python code more readable.
基本上,PEP 8是用于编码约定和建议的样式指南。 PEP 8的主要目标是使python代码更具可读性。
Python 2.x和Python 3.x有什么区别? (What are the differences between Python 2.x and Python 3.x?)
Python 2.x is an older version of Python while Python 3.x is newer. Python 2.x is legacy now but Python 3.x is the present and future of this language. The most visible difference between them is in print statement. In Python 2 it is print “Hello” and in Python 3, it is print (“Hello”).
Python 2.x是Python的旧版本,而Python 3.x是更新的。 Python 2.x现在是传统,但Python 3.x是该语言的现在和将来。 它们之间最明显的区别是在print语句中。 在Python 2中,它是打印“ Hello”,而在Python 3中,它是打印(“ Hello”)。
为什么需要使代码更具可读性? (Why do you need to make your code more readable?)
We need to make our code more readable so that other programmer can understand our code. Basically for a large project, many programmers work together. So, if the readability of the code is poor, it will be difficult for other to improve the code later.
我们需要使我们的代码更具可读性,以便其他程序员可以理解我们的代码。 基本上对于一个大型项目,许多程序员一起工作。 因此,如果代码的可读性很差,其他人以后将很难改进代码。
Python中有几个关键字? 为什么我们要认识他们? (How many Keywords are there in Python? And why should we know them?)
There are 33 keywords in Python. We should know them to know about their use so that in our work we can utilize them. Another thing is, while naming a variable, the variable name cannot be matched with the keywords. So, we should know about all the keywords.
Python中有33个关键字。 我们应该认识他们,以了解它们的用途,以便在我们的工作中可以利用它们。 另一件事是,在命名变量时,变量名称不能与关键字匹配。 因此,我们应该了解所有关键字。
Python中内置的数据类型是什么? (What are the built-in data-types in Python?)
The built-in data-types of Python are
Python的内置数据类型是
- Numbers 号码
- Strings 弦乐
- Tuples 元组
- List 清单
- Sets 套装
- Dictionary 字典
Among them, the first three are immutable and the rest are mutable. To know more, you can read our
Python Data Types tutorial.
其中,前三个是不可变的,其余是可变的。 要了解更多信息,您可以阅读我们的
Python数据类型教程。
Python有几种类型的运算符? 简要介绍一下它们 (How many types of operators Python has? Give brief idea about them)
Python has five types of operators. They are
Python有五种运算符。 他们是
- Arithmetic Operators : This operators are used to do arithmetic operations 算术运算符:此运算符用于进行算术运算
- Comparison Operators : This operators are used to do compare between two variables of same data-type. 比较运算符:此运算符用于在相同数据类型的两个变量之间进行比较。
- Bitwise Operators : This kind of operators are used to perform bitwise operation between two variable 按位运算符:这种运算符用于在两个变量之间执行按位运算
- Logical Operators : This operators performs logical AND, OR, NOT operations among two expressions. 逻辑运算符:此运算符在两个表达式之间执行逻辑AND,OR,NOT运算。
- Python Assignment Operators : This operators are used to perform both arithmetic and assignment operations altogether. Python赋值运算符:此运算符用于同时执行算术和赋值运算。
Read more at Python Operators tutorial.
在Python Operators教程中阅读更多内容。
以下代码的输出是什么,为什么? (What is the output of the following code and why?)
a = 2
b = 3
c = 2
if a == c and b != a or b == c:
print("if block: executed")
c = 3
if c == 2:
print("if block: not executed")The output of the following code will be
以下代码的输出将是
if block: executedThis happens because logical AND operator has more precedence than logical OR operator. So a == c expression is true and b != a is also true. So, the result of logical AND operation is true. As one variable of OR operation is true. So the result of Logical operation is also true. And that why the statements under first if block executed. So the value of variable c changes from 2 to 3. And, As the value of C is not true. So the statement under second block doesn’t execute.
发生这种情况是因为逻辑AND运算符比逻辑OR运算符具有更高的优先级。 因此, a == c表达式为真, b!= a也为真。 因此,逻辑与运算的结果为真。 OR运算的一个变量为true。 因此,逻辑运算的结果也是正确的。 那就是为什么首先执行if语句的原因。 因此,变量c的值从2变为3。而且,由于C的值不正确。 因此,第二个块下的语句不会执行。
编写一个可以确定输入年份是year年的程序 (Write a program that can determine either the input year is a leap year or not)
The following code will determine either the input year is a leap year or not.
以下代码将确定输入年份是否为a年。
try:
print('Please enter year to check for leap year')
year = int(input())
except ValueError:
print('Please input a valid year')
exit(1)
if year % 400 == 0:
print('Leap Year')
elif year % 100 == 0:
print('Not Leap Year')
elif year % 4 == 0:
print('Leap Year')
else:
print('Not Leap Year')Below image shows the sample output of above program.
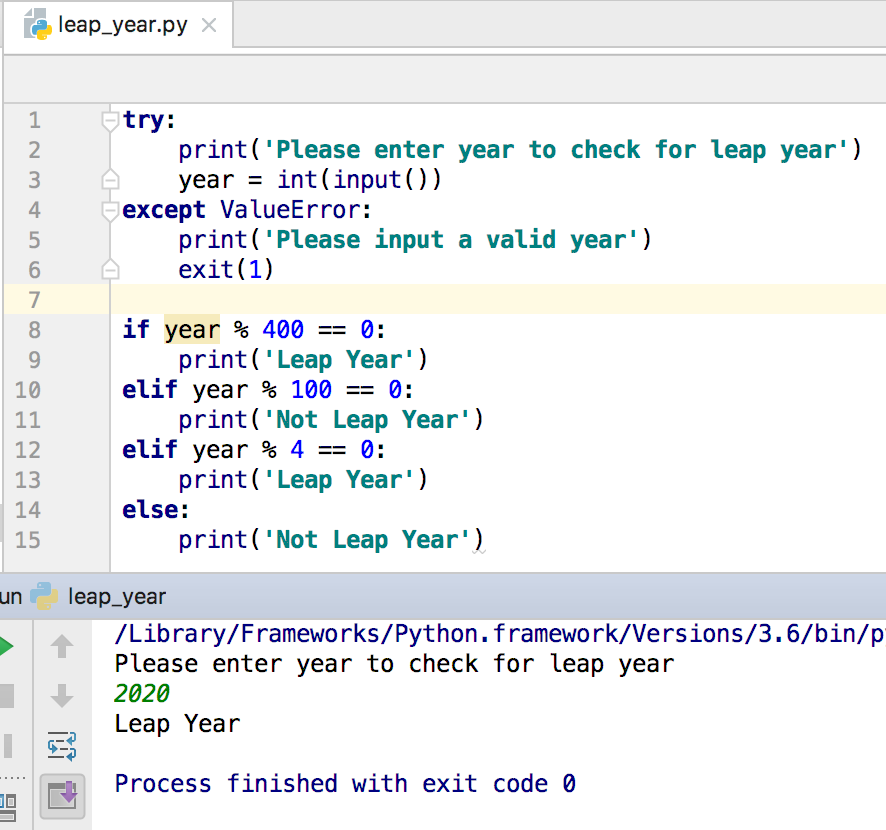
下图显示了以上程序的示例输出。
以下代码的输出应该是什么,为什么? (What should be the output of the following code and why?)
a = 10
while a > 0:
print(a)
else:
print('Now the value of a is ',a);
breakThe following code will result in SyntaxError. Because the break statement is not in a loop. It should be under the scope of a loop.
以下代码将导致SyntaxError。 因为break语句不在循环中。 它应该在循环范围之内。
如果程序不需要任何操作但需要语法上的语句,那么在Python中可以使用什么语句? (What is the statement that can be used in Python if the program requires no action but requires a statement syntactically?)
Python pass statement can be used if the program requires no action but requires a statement syntactically. Python pass statement has no action. But it is a statement. Read more at python pass statement tutorial.
如果程序不需要任何操作,但是在语法上需要一个语句,则可以使用Python pass语句。 Python pass语句不起作用。 但这是一个声明。 在python pass语句教程中了解更多信息。
Python递归的优点是什么? (What are the advantages of Python Recursion?)
Implementing something using Python recursion requires less effort. The code we write using recursion will be comparatively smaller than the code that is implemented by loops. Again, code that are written using recursion are easier to understand also.
使用Python递归实现某些工作所需的精力更少。 我们使用递归编写的代码将比循环实现的代码小。 同样,使用递归编写的代码也更容易理解。
Python递归的缺点是什么? (What are the disadvantages of Python Recursion?)
Python recursion requires more function call. Each function call stores some state variable to the program stack. If your code requires too many function calls, it will consumes too much memory. So, there may be some possibilities of causing memory overflow if your code is not that much efficient. Again, it takes some time to call a function, if the task of the function is done, the it recall the parent function which also cause some time to re-execute the parent function from the previous state. So, recursive function consumes more time to perform it’s task.
Python递归需要更多的函数调用。 每个函数调用都将一些状态变量存储到程序堆栈中。 如果您的代码需要太多的函数调用,则会消耗太多的内存。 因此,如果您的代码效率不高,则可能会导致内存溢出。 同样,调用一个函数需要花费一些时间,如果该函数的任务完成了,它将调用父函数,这也会导致一些时间从先前的状态重新执行父函数。 因此,递归函数会花费更多时间来执行其任务。
For examples, see our Python Recursion example.
有关示例,请参见我们的Python递归示例。
什么是python中的lambda? (What is lambda in python?)
Python lambda is a single expression anonymous function which has no name. Therefore, we can use Python lambda for a small scope of program.
Python lambda是一个没有名称的单表达式匿名函数。 因此,我们可以将Python lambda用于较小范围的程序。
为什么Python lambda没有任何声明? (Why doesn’t Python lambda have any statement?)
Python lambda doesn’t have any statement because statement does not return anything while an expression returns some value. The basic syntax of python lambda is
Python lambda没有任何语句,因为在表达式返回某些值时,语句不返回任何内容。 python lambda的基本语法是
lambda arguments : expressionThe value of the expression for those arguments is returned by Python lambda.
To know more with examples, read our Python Lambda tutorial.
这些参数的表达式的值由Python lambda返回。
要了解更多有关示例的信息,请阅读我们的Python Lambda教程。
您对Python模块了解什么? (What do you understand by Python Modules?)
A file containing Python definitions and statements is called a python module. So naturally, the filename is the module name which is appended with the suffix .py.
包含Python定义和语句的文件称为python模块。 因此,文件名自然是模块名,后缀.py 。
给定一个模块print_number,以下代码的输出是什么? (A module print_number given, what will be the output of the following code?)
# module name: print_number
def printForward(n):
#print 1 to n
for i in range(n):
print(i+1)
def printBackwards(n):
#print n to 1
for i in range(n):
print(n-i)from print_number import printForward as PF
PF(5)The output of the program will be like this.
程序的输出将是这样。
1
2
3
4
5Because PF refers the function printForward. So it passes the argument to the function and the result will be like given one.
因为PF引用了函数printForward。 因此它将参数传递给函数,结果将像给定的那样。
Read our tutorial on Python modules to have clear idea on this.
阅读我们有关Python模块的教程,以对此有清晰的认识。
您对Python软件包了解什么? (What do you understand by Python Package?)
Python package is a collection of modules in directories that give a package hierarchy. More elaborately, python packages are a way of structuring python’s module by using “dotted module names”. So A.B actually indicates that B is a sub module which is under a package named A.
Python软件包是目录中提供软件包层次结构的模块的集合。 更详细地说,python包是通过使用“点分模块名称”来构造python模块的一种方式。 因此,AB实际上表明B是一个子模块,位于名为A的程序包下。
以下代码的输出是什么? 解释输出 (What will be the output of the following code? Explain the output)
print(10)
print(0x10)
print(0o10)
print(0b10)The output of the following code will be:
以下代码的输出将是:
10
16
8
2Because 0x10 is a hexadecimal value which decimal representation is 16. Similarly 0o10 is a octal value and 0b10 is a binary value.
因为0x10是一个十六进制值的十进制表示是16。类似地0o10是一个八进制值和0b10是一个二进制值。
此代码会输出任何错误吗? 说明。 (Will this code output any error? Explain.)
a = 3 + 4jThis will not produce any error. Because 3 + 4j is a complex number. Complex number is a valid data-type in Python.
这不会产生任何错误。 因为3 + 4j是一个复数。 在Python中,复数是有效的数据类型。
Read more at Python Number tutorial for more details.
在Python Number教程中了解更多信息,以获取更多详细信息。
以下代码的输出是什么? (What will be the output of the following code?)
def func():
try:
return 1
finally:
return 2
print(func())The code will output 2. Because whatever statements the try block has, the finally block must execute. So it will return two.
该代码将输出2。因为try块具有任何语句,所以必须执行finally块。 因此它将返回两个。
以下代码2的输出是什么? 说明 (What will be the output of the following code2? Explain)
def func():
a = 2
try:
a = 3
finally:
return a
return 10
print(func())The code will output 3. As no error occurs, the try block will execute and the value a is changed from 2 to 3. As the return statement of finally block works. The last line of the function will not execute. So the output will be 3, not 10.
代码将输出3。如果没有错误发生,将执行try块,并将a的值从2更改为3。由于finally块的return语句起作用。 函数的最后一行将不执行。 因此输出将是3,而不是10。
Python中的命名空间是什么? (What is namespace in Python?)
Namespace is the naming system to avoid ambiguity and to make name uniques. Python’s namespace is implemented using Python Dictionary. That means, Python Namespace is basically a key-value pair. For a given key, there will be a value.
命名空间是一种避免歧义并使名称唯一的命名系统。 Python的名称空间是使用Python字典实现的。 这意味着Python命名空间基本上是一个键值对。 对于给定的键,将有一个值。
为什么我们需要Python目录? (Why do we need Python Directories?)
Suppose, you are making some a software using Python where you need to read/write files from different directories. The directories can be dynamic so that you cannot fix the directory from your code, rather you need to choose the directory dynamically. After choosing the directory, you may have to create a new directory or write a file or read a file from that directory. To do so, Python has introduced this facility.
假设您正在使用Python开发一些软件,需要从不同目录读取/写入文件。 目录可以是动态的,因此您无法从代码中修复目录,而是需要动态选择目录。 选择目录后,您可能必须创建一个新目录或写入文件或从该目录读取文件。 为此,Python引入了此功能。
如何使用Python获取当前目录? (How to get current directory using Python?)
To get current Directory in Python, we need to use os module. Then, we can get the location of the current directory by using getcwd() function. The following code will illustrate the idea
要使用Python获取当前目录,我们需要使用os模块。 然后,我们可以使用getcwd()函数获取当前目录的位置。 以下代码将说明这个想法
import os #we need to import this module
print(os.getcwd()) #print the current locationTo get more examples, see our tutorials on Python Directories.
要获取更多示例,请参阅我们的Python目录教程。
为什么要使用文件操作? (Why Should We Use File Operation?)
We cannot always rely on run-time input. For example, we are trying to solve some problem. But we can’t solve it at once. Also, the input dataset of that problem is huge and we need to test the dataset over and over again. In that case we can use Python File Operation. We can write the dataset in a text file and take input from that text file according to our need over and over again.
Again, if we have to reuse the output of our program, we can save that in a file. Then, after finishing our program, we can analysis the output of that program using another program. In these case we need Python File Operation. Hence we need Python File Operation.
我们不能总是依靠运行时输入。 例如,我们正在尝试解决一些问题。 但是我们无法立即解决。 同样,该问题的输入数据集非常庞大,我们需要反复测试数据集。 在这种情况下,我们可以使用Python File Operation。 我们可以将数据集写入文本文件中,然后根据需要一遍又一遍地从该文本文件中获取输入。
同样,如果我们必须重用程序的输出,则可以将其保存在文件中。 然后,在完成程序后,我们可以使用另一个程序分析该程序的输出。 在这种情况下,我们需要Python文件操作。 因此,我们需要Python文件操作。
如何关闭文件? 为什么要关闭文件? (How to close file? Why should we close files?)
To close a file in Python we should use close() function. Mainly there is two reasons why we should close files after use. Firstly, Python does not promise that it will close the files for us. The operating system does, when the program exits. If your program does something else for a while, or repeats this sequence of steps dozens of times, we could run out of resources, or overwrite something. Second, some operating system platforms won’t let the same file be simultaneously open for read-only and for write. So, if the two filenames happened to be the same file, we might get an error trying to write without having closed the input file.
要在Python中关闭文件,我们应该使用close()函数。 主要有两个原因使我们在使用后关闭文件。 首先,Python不保证它将为我们关闭文件。 程序退出时,操作系统执行此操作。 如果您的程序暂时执行其他操作,或重复执行此步骤数十次,则可能会耗尽资源或覆盖某些内容。 其次,某些操作系统平台不允许同时打开同一文件进行只读和写入操作。 因此,如果两个文件名碰巧是同一文件,则在未关闭输入文件的情况下尝试写入可能会出错。
To know more, see our tutorial on Python File.
要了解更多信息,请参阅我们的Python File教程。
什么是python词典? (What are python dictionaries?)
Python dictionary is basically a sequence of key-value pair. This means, for each key, there should be a value. All keys are unique. We can initialize a dictionary closed by curly braces. Key and values are separated by semicolon and and the values are separated by comma.
Python字典基本上是键-值对的序列。 这意味着,对于每个键,都应该有一个值。 所有键都是唯一的。 我们可以初始化一个用花括号关闭的字典。 键和值用分号分隔,值用逗号分隔。
del关键字和clear()函数之间有什么区别? (What are the differences between del keyword and clear() function?)
The difference between del keyword and clear() function is, del keyword remove one element at a time. But clear function removes all the elements. The syntax to use the del keyword is:
del关键字和clear()函数之间的区别在于,del关键字一次删除一个元素。 但是清除功能会删除所有元素。 使用del关键字的语法为:
del dictionary[‘key']While the syntax for clear() function is:
虽然clear()函数的语法为:
dictionary.clear()To know more see our tutorial on Python Dictionary.
要了解更多信息,请参阅我们的Python字典教程。
什么是Python集? (What is Python Set?)
Python Set is an unordered collection of unique elements. Suppose you have a list and you need only the unique items of the list you can use Python Set. Similarly, if you need only unique items from input, Python set can help you to do so. You can add or delete items from it.
You can initialize a set by placing elements in between curly braces.
Python Set是唯一元素的无序集合。 假设您有一个列表,并且只需要可以使用Python Set的列表中的唯一项。 同样,如果您只需要输入中的唯一项,则Python set可以帮助您做到这一点。 您可以从中添加或删除项目。
您可以通过将元素放在花括号之间来初始化集合。
您将如何在python中将字符串转换为集合? (How will you convert a string to a set in python?)
We can convert a string to a set in python by using set() function. For examaple the following code will illustrate the idea
我们可以使用set()函数将字符串转换为python中的set() 。 例如,以下代码将说明这一想法
a = 'Peace'
b = set(a)
print(b)空白花括号初始化什么? 字典还是一组? (What a blank curly brace initialize? A dictionary or a set?)
Well, both Python Dictionary and Python Set requires curly braces to initialize. But a blank curly brace or curly brace with no element, creates a dictionary. To create a blank set, you have to use set() function.
好吧, Python字典和Python集都需要花括号来初始化。 但是空白的花括号或没有元素的花括号会创建字典。 要创建空白集,必须使用set()函数。
解释split()和join()函数。 (Explain split() and join() function.)
As the name says, Python’s split() function helps to split a string into substrings based on some reference sequence. For example, we can split Comma Separated Values(CSV) to a list. On the other hand, join() function does exactly the opposite. Given a list of values you can make a comma separated values using join function.
顾名思义,Python的split()函数有助于根据某些引用序列将字符串拆分为子字符串。 例如,我们可以将逗号分隔值(CSV)拆分为一个列表。 另一方面, join()函数的作用恰恰相反。 给定值列表,您可以使用join函数将值分隔为逗号。
什么是Python Decorator? (What is Python Decorator?)
Python decorator is a function that helps to add some additional functionalities to an already defined function. Python decorator is very helpful to add functionality to a function that is implemented before without making any change to the original function. Decorator is very efficient when want to give an updated code to an existing code.
Python装饰器是一个函数,可以帮助向已定义的函数添加一些其他功能。 Python装饰器在不对原始功能进行任何更改的情况下将功能添加到之前实现的功能中非常有用。 想要将更新的代码提供给现有代码时,Decorator非常有效。
您对Python生成器了解什么? (What do you understand by Python Generator?)
Python generator is one of the most useful and special python function ever. We can turn a function to behave as an iterator using python generator function. So, as similar to the iterator, we can call the next value return by generator function by simply using next() function.
Python生成器是有史以来最有用,最特殊的python函数之一。 我们可以使用python生成器函数将一个函数用作迭代器。 因此,类似于迭代器,我们只需使用next()函数就可以调用生成器函数返回的下一个值。
您对Python迭代器和Iterable元素了解什么? (What do you understand by Python iterator and Iterable elements?)
Most of the objects of Python are iterable. In python, all the sequences like Python String, Python List, Python Dictionary etc are iterable. On the other hand, an iterator is an object which is used to iterate through an iterable element.
Python的大多数对象都是可迭代的。 在python中,所有序列(如Python String , Python List , Python Dictionary等)都是可迭代的。 另一方面,迭代器是用于迭代可迭代元素的对象。
您对迭代器协议了解多少? (What do you know about iterator protocol?)
Python Iterator Protocol includes two functions. One is iter() and the other is next(). iter() function is used to create an iterator of an iterable element. And the next()function is used to iterate to the next element.
Python迭代器协议包含两个函数。 一个是iter(),另一个是next()。 iter()函数用于创建可迭代元素的迭代器。 next()函数用于迭代到下一个元素。
以下代码将输出什么? 说明 (What will be output of the following code? Explain)
class A:
def __init__(self):
self.name = 'John'
self.age = 23
def getName(self):
return self.name
class B:
def __init__(self):
self.name = 'Richard'
self.id = '32'
def getName(self):
return self.name
class C(A, B):
def __init__(self):
A.__init__(self)
B.__init__(self)
def getName(self):
return self.name
C1 = C()
print(C1.getName())The output to the given code will be Richard. The name when printed is ‘Richard’ instead of ‘John’. Because in the constructor of C, the first constructor called is the one of A. So, the value of name in C becomes same as the value of name in A. But after that, when the constructor of B is called, the value of name in C is overwritten by the value of name in B. So, the name attribute of C retains the value ‘Richard’ when printed.
给定代码的输出将是Richard 。 打印时的名称是“ Richard”而不是“ John”。 因为在C的构造函数中,第一个被调用的构造函数是A的一个。因此,C中的name的值与A中的name的值相同。但是此后,当调用B的构造函数时,C的值C中的name被B中的name值覆盖。因此,C的name属性在打印时保留值'Richard'。
为什么我们需要运算符重载? (Why do we need operator overloading?)
We need Python Operator Overloading to compare between two objects. For example all kind of objects do not have specific operation what should be done if plus(+) operator is used in between two objects. This problem can be resolved by Python Operator Overloading. We can overload compare operator to compare between two objects of same class using python operator overloading.
我们需要Python操作符重载才能在两个对象之间进行比较。 例如,所有类型的对象都没有特定的操作,如果在两个对象之间使用plus(+)运算符,该怎么办。 此问题可以通过Python操作符重载来解决。 我们可以使用python运算符重载来重载compare运算符以在同一类的两个对象之间进行比较。
Python中的元组和列表有什么区别? (What is the difference between tuples and lists in Python?)
The main differences between lists and tuples are, Python List is mutable while Python Tuples is immutable. Again, Lists are enclosed in brackets and their elements and size can be changed, while tuples are enclosed in parentheses and cannot be updated.
列表和元组之间的主要区别在于, Python列表是可变的,而Python元组是不可变的。 同样,列表用括号括起来,其元素和大小可以更改,而元组用括号括起来并且不能更新。
如何比较两个清单? (How to compare two list?)
Two compare we can use cmp(a,b) function. This function take two lists as arguments as a and b. It returns -1 if a
两次比较,我们可以使用cmp(a,b)函数。 该函数将两个列表作为a和b作为参数。 如果a
您如何排序列表? (How can you sort a list?)
We can sort a list by using sort() function. By default a list is sorted in ascending order. The example is given
我们可以使用sort()函数对列表进行sort() 。 默认情况下,列表按升序排序。 给出的例子
listA.sort()如何以相反的顺序对列表进行排序? (How can you sort a list in reverse order?)
We can sort a Python list in reverse order by using sort() function while passing the value for key ’sorted’ as false. The following line will illustrate the idea.
我们可以通过使用sort()函数以相反的顺序对Python列表进行sort()同时将键'sorted'的值传递为false。 下一行将说明这一想法。
listA.sort(reverse=True)如何删除字符串中的所有前导和尾随空格? (How will you remove all leading and trailing whitespace in string?)
Removing all leading whitespace can be done my by using rstrip() function. On the other hand, all trailing whitespace can be removed by using lstrip() function. But there is another function by which the both operation can be done. That is, strip() function.
可以通过使用rstrip()函数来删除所有前导空格。 另一方面,可以使用lstrip()函数删除所有结尾的空格。 但是还有另一个功能可以通过这两个功能完成。 即, strip()函数。
如何从列表或元组中选择随机项目? (How can you pick a random item from a list or tuple?)
You can pick a random item from a list or tuple by using random.choice(listName) function. And to use the function you have import random module.
您可以使用random.choice(listName)函数从列表或元组中选择一个随机项目。 并使用您具有导入random模块的功能。
您如何切换字符串中所有字母的大小写? (How will you toggle case for all letters in string?)
To toggle case for all letters in string, we need to use swapcase() Then the cases of all letters will be swapped.
要切换字符串中所有字母的大小写,我们需要使用swapcase()然后将所有字母的大小写交换。
在Python中,切片是什么? (In Python what is slicing?)
Python slicing is the mechanism to select a range of items from a sequence like strings, list etc.
The basic syntax of of slicing is listObj[start:end+1], here the items from start to end will be selected.
Python切片是一种从序列(例如字符串,列表等)中选择一系列项目的机制。
切片的基本语法为listObj [start:end + 1],此处将选择从start到end的项目。
您如何从原始号码中获得10位零填充数字? (How will you get a 10 digit zero-padded number from an original number?)
We can get a 10 digit zero-padded number from an original number by using rjust() function. The following code will illustrate the idea.
通过使用rjust()函数,我们可以从原始数字中获取10位零填充数字。 以下代码将说明这一想法。
num = input('Enter a number : ')
print('The zero-padded number is : ', str(num).rjust(10, '0'))Python中的负索引是什么? (What is negative index in Python?)
There are two type of index in python. Non-negative and negative. Index 0 addresses the first item, index 1 address the second item and so on. And for the negative indexing, -1 index addresses the last item, -2 index addresses the second last item and so on.
python中有两种类型的索引。 非负和负。 索引0寻址第一项,索引1寻址第二项,依此类推。 对于负索引,-1索引指向最后一个项目,-2索引指向倒数第二个项目,依此类推。
So, That’s all for python interview questions and answers. We wish you success on python interview. Best of Luck!
所以,这就是python面试问题和答案。 祝您在python面试中取得成功。 祝你好运!
翻译自: https://www.journaldev.com/15490/python-interview-questions
python面试问题