Overcoming Language Priors in VQA via Decomposed Linguistic Representations——(AAAI2020)论文阅读笔记
目录
1.abstract
2.Introduction
3.模型简介
4.方法精读
4.1语言注意模块
4.2问题识别模块
4.3对象引用模块
4.4视觉验证模块
5.实验
最近看了两篇文章,都关于解决VQA先验性的问题。其次是一篇AAAI2020上面的文章:《Overcoming Language Priors in VQA via Decomposed Linguistic Representations》,即《用分解语言表示克服VQA中的语言先验》。该篇文章是对CVPR2018的文章《Don’t Just Assume; Look and Answer:Overcoming Priors for Visual Question Answering》相关工作的进一步延伸。下面是对这篇文章的相关解读。
1.abstract
语言先验性就是对于训练的Question与Image数据,模型并没有学会依照Image来回答问题,而只是简单的依赖answer的比例。比如对于what color这类question,答案为white占比为80%,那么当输入这类问题,模型就直接回答为white,而完全不需要依照Image,且这样的正确率很高。
2.Introduction
近期研究(Kafle和Kanan,2017;Agrawal等人。2018年;Selvaraju等人。2019)证明大多数现有的视觉问答(VQA)模型过度依赖问题和答案之间的表面相关性,即语言优先级,而忽略图像信息。例如,他们可能经常回答关于颜色的问题“白色”,关于运动的问题“网球”,以及以“有没有a”开头的问题“是”,无论问题的图像是什么。这些模型易受语言先验知识影响的主要原因是,在答案推理过程中,问题的各种信息相互纠缠。如何解决language prior problem一直是VQA任务的一大难点,这篇文章从question的角度出发,基于 Don’t Just Assumee; Look and Answer: Overcoming Priors for VQA那篇工作进一步延伸,建立一个能够灵活地学习和利用问题中不同信息的分解表示的VQA模型,对question进行了分解表示,消除了疑问词所带来的language prior,再依据Image信息进行预测answer。值得一提的是,它并不同于以前的 Neural Module Networks。且可以清晰的呈现model预测answer的过程。
该文的主要贡献如下:
(1)学习问题的分解语言表示,并将基于语言的概念发现和基于视觉的概念验证分离,以克服语言先验。
(2) 使用一个结合硬注意机制和软注意机制的语言注意模块,在将概念表示和类型表示分离的同时,灵活地识别问题中的不同信息。
与《Don’t Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering》的不同:
论文的方法类似于Agrawal等人的工作,利用问题中的不同信息来分离概念发现和概念验证。但是,论文的方法和他们的有两个方面的不同。首先,论文中使用语言注意机制来灵活地学习问题的分解表示,而不是使用基于部分的提取器(Extractor)来从问题中提取短语。其次,将候选答案视为视觉概念,并以端到端的方式学习它们与问题和图像的相关性,同时它们预先定义了各种视觉概念,并使用预先训练的分类器识别图像中的概念。总之,论文中的方法通过学习分解的语言表示,保证了问题中的不同信息可以在一个统一的框架中灵活地识别和适当地利用。
3.模型简介
下面拆分成Question 分解和Answer prediction两部分介绍一下整个模型运行的过程。
Question 分解:
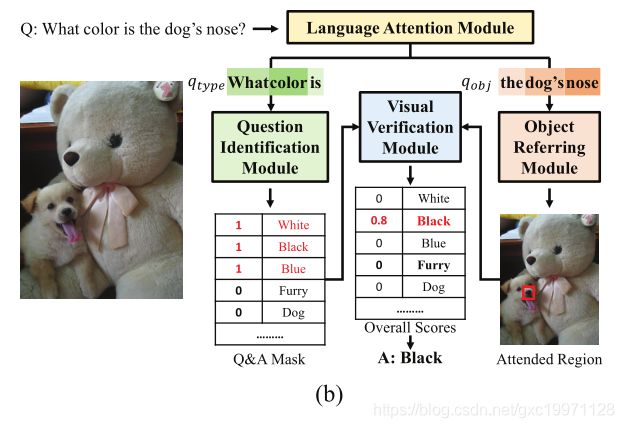
该方法包括语言注意模块、问题识别模块、对象引用模块和视觉验证模块,其中:
(1)语言注意模块将问题解析为三个短语表示:类型表示(qtype)、对象表示(qobj)和概念表示(qcon)。
(2)问题识别模块使用类型表示来识别问题类型和可能的答案集(是/否或特定概念,如颜色或数字)。通过测量词性(疑问词等)呈现与候选答案之间的相关性,生成表示候选答案是否可能是正确答案的问答掩码(Q&A mask)。
(3)对象引用模块采用自上而下的注意机制以物体表象为指导,关注图像的相关区域。
(4)视觉验证模块测量关注区域和概念表示之间的相关性以推断答案,以通过是/否问题的阈值比较推断答案。对于非是/否问题,问题识别模块发现的可能答案将作为待验证的概念。测量参与区域和候选答案之间的视觉得分,然后与问答mask融合,得到最终答案。
通过识别和利用问题中的不同信息,该方法将基于语言的概念发现和基于视觉的概念验证与答案推理过程分离。因此,问题和答案之间的表面相关性并不支配答案推理过程,模型必须利用图像内容从可能的答案集中推断出最终答案。
输入包括由K个局部特征![]() 表示的图像I∈I、问题Q∈Q和候选答案集a。对于问题和答案,使用预先训练的GloVe词向量初始化每个单词的嵌入。
表示的图像I∈I、问题Q∈Q和候选答案集a。对于问题和答案,使用预先训练的GloVe词向量初始化每个单词的嵌入。
作者将question分为两种情况进行处理:yes/no和not yes/no。
具体的模型如下面的示例图所示:

图1:提议方法的框架。它通过语言注意模块将问题分解为三个短语表示,并进一步利用短语表示通过三个特定模块:问题识别模块、对象引用模块和视觉验证模块来推断答案。(a) 是对是/否问题建议方法的回答过程,和(b)是对非是/否问题的回答过程
Answer prediction:
注意这里的类型表示question type只用来确定answer集合,也就是这类question下的所有answer集合。它并没有直接参与到最终的answer预测,所以才会有language prior的减轻
a.如果question属于yes/no这类,那么它的answer集为{yes, no},其它的一律去掉。然后通过对象表示![]() 和图像信息采用top-down自上而下注意力机制定位region(问题中的对象引导着去attention),最后再和概念表示
和图像信息采用top-down自上而下注意力机制定位region(问题中的对象引导着去attention),最后再和概念表示![]() 混合,进行二分类:
混合,进行二分类:

b.如果question不属于yes/no这类,那么首先需要用类型表示![]() 来预测answer集合,然后用对象表示
来预测answer集合,然后用对象表示![]() 与图像进行soft attention得到最终的图像attention区域(与上面相同)。最后,计算answer集合中每个answer的得分即可。
与图像进行soft attention得到最终的图像attention区域(与上面相同)。最后,计算answer集合中每个answer的得分即可。
4.方法精读
论文提出了一个语言注意模块来获得分解的语言表示。语言注意模块结合了硬注意机制和软注意机制,将是/否问题的概念表征与类型表征分离开来。
4.1语言注意模块

如图2所示,语言注意模块使用三种注意,即类型注意(Type attention)、对象注意(Object attention)和概念注意(Concept attention),分别学习这三种分解的表示。具体来说,在学习对象表征和概念表征时采用问题类别识别损失来保证类型注意对疑问词的关注,并采用阈值来过滤疑问词。在这里,我们也排除了疑问词作为是/否问题的宾语表征,因为疑问词在宾语指称中是无用的。
对于问题Q,作者利用软注意力机制来计算其类型表达: 其中Wa,t是一个可训练向量表示,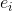 为问题中的词嵌入向量,共T个词。下图的公式是用soft attention(软注意力)计算question-type的向量表示。注:为了能够准确定位到question type包含哪些词(如下
为问题中的词嵌入向量,共T个词。下图的公式是用soft attention(软注意力)计算question-type的向量表示。注:为了能够准确定位到question type包含哪些词(如下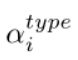 越大,说明这个词是疑问词的概率越大,作者采用VQA dataset数据中已有的question type label对模型进行训练):
越大,说明这个词是疑问词的概率越大,作者采用VQA dataset数据中已有的question type label对模型进行训练):

为了确保类型注意力关注到疑问词,作者使用VQA数据集中提供的基于疑问词的问题类别作为监督信息来指导类型学习,并引入一个问题类别识别损失:
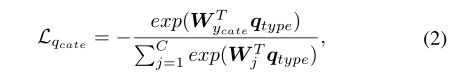
其中,C是问题类别个数,W是可训练的权重矩阵,![]() cate∈{1,2,3,……C}表示问题Q的基本真值问题类别。
cate∈{1,2,3,……C}表示问题Q的基本真值问题类别。
作者进一步引入一个标量β作为阈值(Threshold),以过滤与问题类型相关的单词。将每个单词的类型注意力权重与β进行比较,可以获得所有的权重小于β的单词,则可以得到一组单词{Wp}p=1,其中每个单词的类型注意权重小于β。这些词是排除了疑问词之后所剩余的词,与指代对象和预期概念相关。![]() 和
和![]() 是可训练向量,进而两种注意力机制被用于计算对象表示和概念表示:
是可训练向量,进而两种注意力机制被用于计算对象表示和概念表示:

对于答案,GRU被用于来获取其表达。
4.2问题识别模块
给定类型表达,首先通过问题识别损失来识别问题类型,(对qtype计算交叉熵判断question是否为yes/no类型):
![]()
其中CE代表交叉熵函数。
若为yes/no类型:answe集合={yes, no}
对于yes/no类型判断题,其可能答案为“是”和“否”,对于其他问题,通过度量问题与候选答案之间的相关性可以确定其可能答案。作者为每个其他问题生成一个Q&A掩码(Masks),用来遮住不需要的answers,其中每个元素表示对应的候选答案为正确答案的可能性。作者计算问题Q与所有候选答案之间的相关性并利用sigmoid函数得到Q&A掩码![]() 。计算过程如下:
。计算过程如下:

其中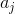 为answer的embedding表示,qtype为前面计算出来的类型表示。
为answer的embedding表示,qtype为前面计算出来的类型表示。
为了有效地指导掩码的生成,作者在数据集中搜索每个问题类别的所有可能答案,以获得Q&A掩码的真值M。对于每个问题类别,可能的答案标记为1,否则标记为0。作者用KL散度度量真值与掩码的距离并提出掩码生成损失:

4.3对象引用模块
对象引用模块使用对象表达利用自上而下的注意力机制来关注与图像中的问题相关的区域。给定图像的局部特征和对象表达,作者计算这些局部特征与问题的对象表达的相关性,并加权求和得到最终的视觉表示V:

其中Wv和 Wq是可训练的权重矩阵。
4.4视觉验证模块
视觉验证模块根据关注区域判断预期视觉概念的存在性以推断出最终答案。
对于判断题,给定概念表示qcon和参与区域的视觉表示V(attention后的图像),直接计算被关注区域的视觉表达与概念表示的视觉分数
计算: ![]()
![]()
而后:

采用交叉熵损失作为目标。
对于其他问题,作者计算被关注的区域和所有候选答案之间的视觉得分Sva,得到视觉得分向量Sv:
![]()
然后,我们将表示图像和候选答案之间相关性的视觉得分向量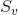 和表示问题和候选答案之间相关性的问答掩码
和表示问题和候选答案之间相关性的问答掩码![]() 进行点积融合,以获得总体得分:
进行点积融合,以获得总体得分:
![]()
![]()
特别的,给定图像I和问题Q,候选答案正确的概率为:
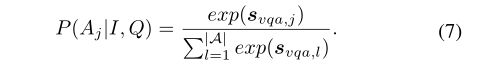
最终的总体验证损失为:

其中σ(·)是sigmoid函数,b是‘是/否’问题的基本真值标签。
5.实验
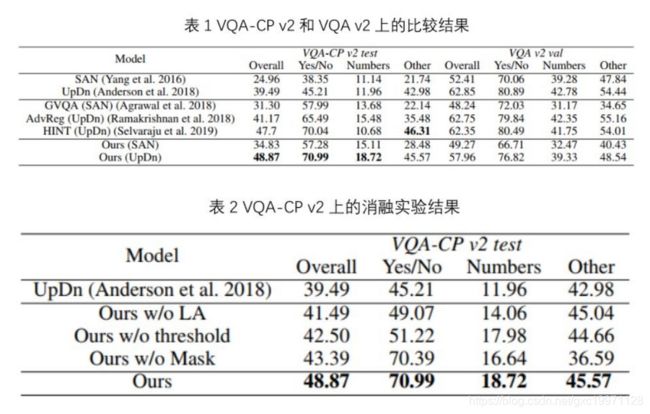
作者在VQA-CP v2数据集上使用标准VQA评估指标来评估其方法的有效性。VQA-CP v2是一个专门用于评估模型受语言先验影响的数据库,通过重新组织VQA v2的训练集和验证集可以得到VQA-CP v2 数据集的训练集和测试集。
在VQA-CP v2数据集中,每个问题类别的答案分布(例如“what number”和“is there”)在测试集与训练集中是不同的。因此,过度依赖于语言先验的VQA模型在此数据集中表现不佳。为了实验的完整性,作者也报告了在VQA v2数据集的验证集的结果。
表1列出了所提出的方法和最新的VQA模型在VQA-CP v2数据集和VQA v2数据集上的结果。结果表明,本文提出的方法好于其他对比方法。通过学习和利用分解后的语言表达,该方法可以从答案推理过程中解耦基于语言的概念发现和基于视觉的概念验证。对于判断题,语言注意力模块将概念表达与疑问词明确分开。因此,模型需要基于图像内容来验证问题中的视觉概念是否存在,以推断出答案,而不是依赖于疑问词。对于其他问题,问题识别模块识别出的可能答案将通过参与区域进行验证。得分最高的答案作为预测结果。因此,模型需要利用图像内容来选择最相关的答案。总而言之,该方法保证了该模型必须利用图像的视觉信息来从可能的答案集中推断出正确的答案,从而显著减轻了语言先验的影响。

提出的方法与UpDn的定性比较。对于每个示例,左上角都显示了VQA-CP v2数据集的测试分割中的一个输入问题,以及图像和地面真实(GT)答案。右上角显示语言注意模块的语言注意地图。下一行分别显示对象引用的视觉注意图和UpDn和我们的方法的预测答案。权重最大的区域用绿色矩形标记。