python 生成器yield全解,小白都能懂
文章目录
- yield释义
- yield from
- 使用 yield from
- 使用 yield
yield释义
写一个爬虫,获取HTML(IO很耗时),然后再对HTML对行解析取得我们感兴趣的数据。
利用 for 循环翻页时我们希望将每个页面的HTML先送去解析内存下载或者保存。
| 关键字 | 示例 |
|---|---|
| yield | 返回一个生成器对象,创建一个容器,例如 |
| return | 函数返回值,程序结束时才返回 |
yield from
利用 for 来翻页,然后使用生成器返回的一个个列表,然后又要取列表里面的值
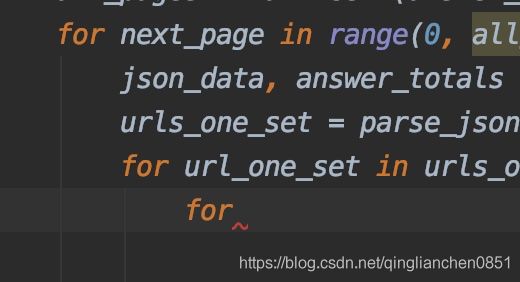
直接导致了三重循环,时间复杂度吓死人。
所以,可以 yield from一个个列举出来,省去一重 for 循环。
下面举例对比下:
使用 yield from
https://pic4.zhimg.com/50/v2-9a135110d2f795947211863fc57b3086_hd.jpg
https://pic2.zhimg.com/50/v2-9c4d4d5ff78cda7771084305eb34148a_hd.jpg
https://pic4.zhimg.com/50/v2-be4aeef2ddc04af49aa22a29395916ff_hd.jpg
https://pic1.zhimg.com/50/v2-cf7b2b6b93f86a35e53ad12bb2a953aa_hd.jpg
https://pic2.zhimg.com/50/v2-d73c52291df74cb10636f903fc726b6d_hd.jpg
使用 yield

由上面两种方式对比,可以看出,yield from后面加上可迭代对象,他可以把可迭代对象里的每个元素一个一个的yield出来,对比yield来说代码更加简洁,结构更加清晰
备注:yield from 是在Python3.3才出现的语法