知识图谱构建技术综述 阅读笔记
知识图谱构建技术综述
刘 峤 李 杨 段 宏 刘 瑶 秦志光 (电子科技大学信息与软件工程学院 成都 610054) ( q liu@uestc.edu.cn)
Knowledg e Graph Construction Techni ques
Liu Qiao,Li Yang,Duan Hong,Liu Yao,and Qin Zhi guang ( School of Information and Software Engineering , University of Electronic Science and Technology of China , Chengdu 610054)
1 知识图谱的定义与架构

知识图谱.是结构化的语义知识库,用 于以符号形式描述物理世界中的概念及其相互关 系.其基本组成单位是“实体-关系-实体”三元组,以 及实体及其相关属性-值对,实体间通过关系相互联 结,构成网状的知识结构.
- 知识图谱本身是一个具有属性的实体通过 关系链接而成的网状知识库.
- 知识图谱的研究价值在于,它是构建在当前 Web基础之上的一层覆盖网络(overlay network), 借助知识图谱,能够在 Web网页之上建立概念间的 链接关系,从而以最小的代价将互联网中积累的信 息组织起来,成为可以被利用的知识.
- 知识图谱的应用价值在于,它能够改变现有 的信息检索方式,一方面通过推理实现概念检索(相 对于现有的字符串模糊匹配方式而言);另一方面以 图形化方式向用户展示经过分类整理的结构化知 识,从而使人们从人工过滤网页寻找答案的模式中 解脱出来.
知识图谱的架构,包括知识图谱自身的逻辑结 构以及构建知识图谱所采用的技术(体系)架构
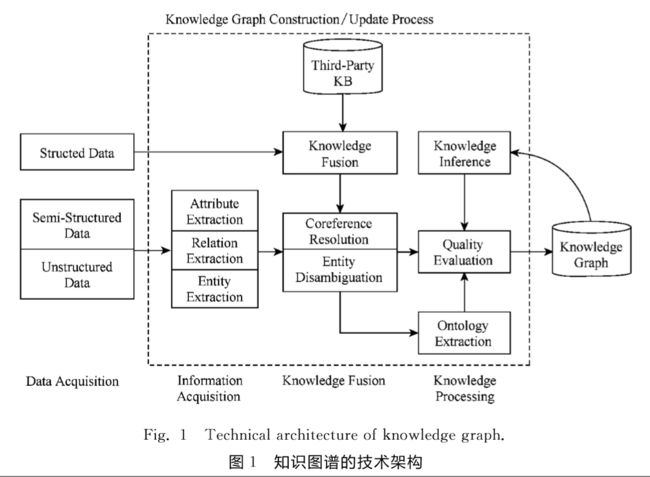
知识图谱有自顶向下和自底向上2种构建方 式.所谓自顶向下构建是指借助百科类网站等结构 化数据源,从高质量数据中提取本体和模式信息,加 入到知识库中;所谓自底向上构建,则是借助一定的 技术手段,从公开采集的数据中提取出资源模式,选 择其中置信度较高的新模式,经人工审核之后,加入 到知识库中.
自底向上的知识图谱构建 技术,按照知识获取的过程分为3个层次:信息抽 取、知识融合以及知识加工.
2 知识图谱的构建技术
2.1 信息抽取
信息抽取(information extraction)是知识图谱 构建的第1步,其中的关键问题是如何从异构数据 源中自动抽取信息得到候选知识单元.信息抽取是一种自动化地从半结构化和无结构数据中抽取实 体、关系以及实体属性等结构化信息的技术[ 4].涉及 的关键技术包括:实体抽取、关系抽取和属性抽取.
2.1.1 实体抽取
实体抽取,也称为命名实体识别(named entit y recognition,NER),是指从文本数据集中自动识别 出命名实体.实体抽取的质量(准确率和召回率)对 后续的知识获取效率和质量影响极大,因此是信息 抽取中最为基础和关键的部分.
2.1.2 关系抽取
研究关 系抽取技术的目的,就是解决如何从文本语料中抽 取实体间的关系这一基本问题.
2.1.3 属性抽取
属性抽取的目标是从不同信息源中采集特定实 体的属性信息.
2.2 知识融合
通过信息抽取,实现了从非结构化和半结构化 数据中获取实体、关系以及实体属性信息的目标,然 而,这些结果中可能包含大量的冗余和错误信息,数 据之间的关系也是扁平化的,缺乏层次性和逻辑性, 因此有必要对其进行清理和整合.知识融合包括2 部分内容:实体链接和知识合并.通过知识融合,可 以消除概念的歧义,剔除冗余和错误概念,从而确保 知识的质量.
2.2.1 实体链接
实体链接(entit y linking)是指对于从文本中抽 取得到的实体对象,将其链接到知识库中对应的正 确实体对象的操作[32]. 实体链接的基本思想是首先根据给定的实体指 称项,从知识库中选出一组候选实体对象,然后通过 相似度计算将指称项链接到正确的实体对象.
实体链接的一般流程是:
- 1)从文本中通过实体 抽取得到实体指称项;
- 2)进行实体消歧和共指消解, 判断知识库中的同名实体与之是否代表不同的含义 以及知识库中是否存在其他命名实体与之表示相同 的含义;
- 3)在确认知识库中对应的正确实体对象之 后,将该实体指称项链接到知识库中对应实体.
实体消歧(entit y disambi guation)是专门用于 解决同名实体产生歧义问题的技术.通过实体消歧,就 可以根据当前的语境,准确建立实体链接.实体消歧 主要采用聚类法.
聚类法是指以实体对象为聚类中心,将所有指 向同一目标实体对象的指称项聚集到以该对象为中 心的类别下.聚类法消歧的关键问题是如何定义实 体对象与指称项之间的相似度,常用方法有4种.
① 空间向量模型(词袋模型).典型的方法是取 当前语料中实体指称项周边的词构成特征向量,然 后利用向量的余弦相似度进行比较,将该指称项聚 类到与之最相近的实体指称项集合中.该方法的缺点在于没有考虑上 下文语义信息,这种信息损失会导致在某些情况下 算法性能恶化,如短文本分析.
② 语义模型.该模型与空间向量模型类似,区别在于特征向量的构造方法不同,语义模型的特征 向量不仅包含词袋向量,而且包含一部分语义特征.
③ 社会网络模型.该模型的基本假设是物以类 聚、人以群分,在社会化语境中,实体指称项的意义 在很大程度上是由与其相关联的实体所决定的.建 模时,首先利用实体间的关系将与之相关的指称项 链接起来构成网络,然后利用社会网络分析技术计 算该网络中节点之间的拓扑距离(网络中的节点即 实体的指称项),以此来判定指称项之间的相似度.
④ 百科知识模型.百科类网站通常会为每个实 体(指称项)分配一个单独页面,其中包括指向其他 实体页面的超链接,百科知识模型正是利用这种链 接关系来计算实体指称项之间的相似度.
共指消解(entit y resolution)技术主要用于解 决多个指称项对应于同一实体对象的问题.学术界对该问题有多种 不同 的 表 述,典 型 的 包 括:对 象 对 齐 (ob j ect ali gnment)、实体匹配(entit y matching)以及实体同 义(entit y synonyms).
除了将共指消解问题视为分类问题之外,还可 以将其作为聚类问题来求解.聚类法的基本思想是 以实体指称项为中心,通过实体聚类实现指称项与 实体对象的匹配.其关键问题是如何定义实体间的 相似性测度.
2.2.2 知识合并
1)合并外部知识库 将外部知识库融合到本地知识库需要处理2个 层面的问题.①数据层的融合,包括实体的指称、属 性、关系以及所属类别等,主要的问题是如何避免实 例以及关系的冲突问题,造成不必要的冗余;②通过 模式层的融合,将新得到的本体融入已有的本体库 中[52].
2)合并关系数据库 在知识图谱构建过程中,一个重要的高质量知 识来源是企业或者机构自己的关系数据库.为了将 这些结构化的历史数据融入到知识图谱中,可以采 用资源描述框架(RDF)作为数据模型.业界和学术 界将这一数据转换过程形象地称为RDB2RDF,其 实质就是将关系数据库的数据换成RDF的三元组 数据.
2.3 知识加工
知识加工主要包括3方面内容:本体 构建、知识推理和质量评估.
2.3.1 本体构建
本体(ontology)是对概念进行建模的规范,是 描述客观世界的抽象模型,以形式化方式对概念及 其之间的联系给出明确定义.本体的最大特点在于 它是共享的,本体中反映的知识是一种明确定义的 共识.
数据驱动的自动化本体构建过程包含3个阶 段:实体并列关系相似度计算、实体上下位关系抽取 以及本体的生成[59].
1)实体并列关系相似度是用于 考察任意给定的2个实体在多大程度上属于同一概 念分类的指标测度,相似度越高,表明这2个实体越 有可能属于同一语义类别.
2) 实体上下位关系抽取是用于确定概念之间的隶属 ( IsA)关系,这种关系也称为上下位关系
3)本体生成阶段的主要任务 是对各层次得到的概念进行聚类,并对其进行语义 类的标定(为该类中的实体指定1个或多个公共上 位词)
2.3.2 知识推理
知识推理是指从知识库中已有的实体关系数据 出发,经过计算机推理,建立实体间的新关联,从而 拓展和丰富知识网络
知识的推理方法可以分为2大类:基于逻辑的 推理和基于图的推理. 基于逻辑的推理主要包括一阶谓词逻辑、描述 逻辑以及基于规则的推理.
描述逻辑(descri p tion logic)是一种基于对象 的知识表示的形式化工具,是一阶谓词逻辑的子集, 它是本体语言推理的重要设计基础.
基于图的推理方法主要基于神经网络模型或 Path Ranking算法.
2.3.3 质量评估
.引入质量评估的意义在于:可以对知 识的可信度进行量化,通过舍弃置信度较低的知识, 可以保障知识库的质量.
2.4 知识更新
知识图谱的内容更新有2种方式:数据驱动下 的全面更新和增量更新.所谓全面更新是指以更新 后的全部数据为输入,从零开始构建知识图谱.这种 方式比较简单,但资源消耗大,而且需要耗费大量人 力资源进行系统维护;而增量更新,则是以当前新增 数据为输入,向现有知识图谱中添加新增知识.这种 方式资源消耗小,但目前仍需要大量人工干预(定义 规则等),因此实施起来十分困难[52].
3 跨语言知识图谱的构建
研究构建跨语言知识图谱的意义在于:
1)由于 各语种知识分布不均匀,对其进行融合可以有效地 弥补单语种知识库的不足;
2)可以充分利用多语种 在知识表达方式上的互补性,增加知识的覆盖率和共享度;
3)构建跨语言知识图谱可以比较不同语言 对同一知识的表述,进而达到过滤错误信息,更新过 时信息的目的
构建跨语言的知识图谱需要处理 好3个关键问题: 1)跨语言本体的构建; 2)跨语言知 识抽取; 3)跨语言知识链接.
3.1 跨语言知识抽取
跨语言知识抽取的主要思路是借助于丰富的源 语种知识自动化抽取缺失的目标语种知识.
3.2 跨语言知识链接
知识链接是构建跨语言知识图谱需要解决的关 键问题之一,其主要思想是将不同语言表示的相同 知识链接起来,包括模式层的链接和数据层的链接.
跨语言本体映射研究的目标是实现不同语言的 本体库之间的本体映射,当前主流的做法是使用翻 译工具将其中一种语言的本体库翻译成另外一种语 言,从而将跨语种本体映射问题转化为单语种本体 映射问题.
4 知识图谱的应用
通过知识图谱,不仅可以将互联网的信息表达 成更接近人类认知世界的形式,而且提供了一种更 好的组织、管理和利用海量信息的方式.目前知识图 谱技术主要用于智能语义搜索、移动个人助理(如 Google Now, Apple Siri等)以及深度问答系统(如 IBM Watson,Wolfram Al pha等)
基于知识图谱的问答系统大致可以分为2类: 基于信息检索的问答系统和基于语义分析的问答系 统
1)基于信息检索的问答系统的基本思路是首先将问题转变为一个基于知识库的结构化查询,从 知识库中抽取与问题中实体相关的信息来生成多个 候选答案,然后再从候选答案中识别出正确答案.
2)基于语义分析的问答系统的基本思路是首 先通过语义分析正确理解问题的含义,然后将问题 转变为知识库的精确查询,直接找到正确答案.
5 问题与挑战
通过对知识图谱构建技术体系 进行深入观察和分析,可以看出它事实上是建立在 多个学科领域研究成果基础之上的一门实用技术, 堪称是信息检索(information retrieval)、自然语言 处 理 (natural language processing)、万 维 网 (WWW)和人工智能(artificial intelli gence)等领域 交汇处的理论研究热点和应用技术集大成者.
1)在信息抽取环节,面向开放域的信息抽取方 法研究还处于起步阶段,部分研究成果虽然在特定 (语种、领域、主题等)数据集上取得了较好的结果, 但普遍存在算法准确性和召回率低、限制条件多、扩 展性不好的问题.
2)在知识融合环节,如何实现准确的实体链接 是一个主要挑战.
3)知识加工是最具特色的知识图谱技术,同时 也是该领域最大的挑战之所在.主要的研究问题包 括:本体的自动构建、知识推理技术、知识质量评估 手段以及推理技术的应用.
4)在知识更新环节,增量更新技术是未来的发 展方向,然而现有的知识更新技术严重依赖人工干 预.
5)最具基础研究价值的挑战是如何解决知识 的表达、存储与查询问题,这个问题将伴随知识图谱 技术发展的始终,对该问题的解决将反过来影响前 面提出的挑战和关键问题.
6 结束语
知识图谱作为下一代智能搜索的核心关键技 术,具有重要的理论研究价值和现实的实际应用价 值.
知识图谱的重要性不仅在于它是一个全局知识 库,是支撑智能搜索和深度问答等智能应用的基础, 而且在于它是一把钥匙,能够打开人类的知识宝库, 为许多相关学科领域开启新的发展机会.
注:这篇论文值得多次读