ROAM: Recurrently Optimizing Tracking Model 阅读笔记
ROAM: Recurrently Optimizing Tracking Model
文章提出模型ROAM采用生成关于跟踪目标的heatmap响应和边框回归的方法跟踪目标:
- 使用可调大小的卷积滤波器来适应对象的形状变化,模型无需设计锚点。
- 采用离线训练递归神经优化器,元学习更新跟踪模型的方法,使模型能够迅速收敛。
Resizable Tracking Model
模型包含两个部分:基础的跟踪模型和优化器。跟踪器包含两个分支:响应生成分支用于预测关于目标位置的heatmap和边框回归分支通过在滑动窗口上的框锚回归坐标偏移量来估计目标的精确框;两个分支共享backbone的feature map。离线学习的优化器使用元学习框架进行训练,在线更新跟踪模型。
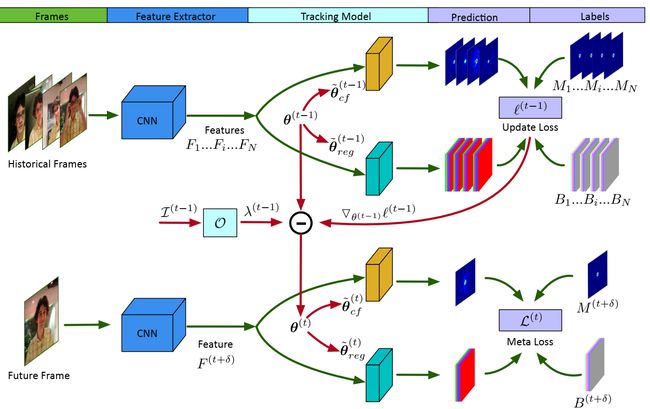
给定一个训练批次patch(根据预测的目标边框剪切产生),通过backbone提取特征。根据当前目标尺寸将模型 θ ( t − 1 ) \theta^{\left(t-1\right)} θ(t−1) warpe成 θ ~ ( t + 1 ) {\widetilde{\theta}}^{\left(t+1\right)} θ (t+1),使用 θ ~ ( t + 1 ) {\widetilde{\theta}}^{\left(t+1\right)} θ (t+1)产生每个sample的响应图和边框。使用GT计算更新的损失 l ( t − 1 ) l\left(t-1\right) l(t−1)及其梯度 ∇ θ ( t − 1 ) l ( t − 1 ) \nabla_{\theta^{\left(t-1\right)}}l^{\left(t-1\right)} ∇θ(t−1)l(t−1)。
包含以前学习率、当前参数、当前更新损失及其梯度的堆 I ( t − 1 ) \mathcal{I}^{\left(\mathcal{t}-1\right)} I(t−1)输入到LSTM O \mathcal{O} O得到自适应自学习率 λ ( t − 1 ) \lambda^{\left(t-1\right)} λ(t−1),模型进行单次梯度更新得到更新的模型 θ ( t ) \theta^{\left(t\right)} θ(t),将更新后的模型 θ ( t ) \theta^{\left(t\right)} θ(t)应用于随机选择的未来帧,以获得最小化的元损失。
针对目标形变可以考虑动态自适应的滤波器,但动态的滤波器意味着对于不同的图像目标需要有不同的参数量;为了解决这个问题,文章定义了fixed-shape convolutional filters,使用双线性插值根据目标尺寸改变滤波器尺寸。跟踪模型 θ \theta θ包含两个部分:correlation filter θ c f \theta_{cf} θcf和bounding box regression filter θ r e g \theta_{reg} θreg;两个都需要适应目标形状变化:
θ = [ θ c f , θ r e g ] \theta=\left[\theta_{cf},\theta_{reg}\right] θ=[θcf,θreg]
θ ~ c f = W ( θ c f , ϕ ) {\widetilde{\theta}}_{cf}=\mathcal{W}\left(\theta_{cf},\phi\right) θ cf=W(θcf,ϕ)
θ ~ r e g = W ( θ r e g , ϕ ) {\widetilde{\theta}}_{reg}=\mathcal{W}\left(\theta_{reg},\phi\right) θ reg=W(θreg,ϕ)
W \mathcal{W} W利用双线性插值将滤波器resize成 ϕ = ( f r , f c ) \phi=\left(f_r,f_c\right) ϕ=(fr,fc),滤波器尺寸根据以前的目标尺寸 ( w , h ) \left(w,h\right) (w,h)计算:
f r = [ ρ h c ] − ⌈ ρ h c ⌉ m o d 2 + 1 f_r=\left[\frac{\rho h}{c}\right]-\left\lceil\frac{\rho h}{c}\right\rceil mod{2}+1 fr=[cρh]−⌈cρh⌉mod2+1
f c = [ ρ w c ] − ⌈ ρ w c ⌉ m o d 2 + 1 f_c=\left[\frac{\rho w}{c}\right]-\left\lceil\frac{\rho w}{c}\right\rceil mod{2}+1 fc=[cρw]−⌈cρw⌉mod2+1
ρ \rho ρ是尺度因子,使滤波器尺寸能够包含一定量的上下文信息,c是feature map的步长。由于可变尺寸的滤波器的存在,边框回归就不用考虑不同的宽高比和锚点框的尺寸问题了。只需要在每个空间位置设置一个固定尺寸的锚点框,与回归滤波器的尺寸对应:
( a w , a h ) = ( f c , f r ) / ρ \left(a_w,a_h\right)=\left(f_c,f_r\right)/\rho (aw,ah)=(fc,fr)/ρ
每τ帧更新滤波器尺寸及锚点框,使用 θ ( 0 ) \theta^{\left(0\right)} θ(0)初始化跟踪器并在后续帧中进行连续优化。
Recurrent Model Optimization
响应生成器: G ( F ; θ c f , ϕ ) \mathcal{G}\left(F;\theta_{cf},\phi\right) G(F;θcf,ϕ),边框回归器: R ( F ; θ r e g , ϕ ) \mathcal{R}\left(F;\theta_{reg},\phi\right) R(F;θreg,ϕ),θ是参数,F是输入的feature map,跟踪损失为
L ( F , M , B ; θ , ϕ ) = ∣ G ( F ; θ c f , ϕ ) − M ∣ 2 + ∣ R ( F ; θ r e g , ϕ ) − B ∣ s L\left(F,M,B;\theta,\phi\right)=\left.|\mathcal{G}\left(F;\theta_{cf},\phi\right)-M\right.|^2+\left.|\mathcal{R}\left(F;\theta_{reg},\phi\right)-B\right.|_s L(F,M,B;θ,ϕ)=∣G(F;θcf,ϕ)−M∣2+∣R(F;θreg,ϕ)−B∣s
第一项为L2,第二项为 Smooth L1,B为GT BBox,M是二维高斯响应,目标位置 ( x 0 , y 0 ) ( w , h ) \left(x_0,y_0\right)\left(w,h\right) (x0,y0)(w,h):
M ( x , y ) = e − α ( ( x − x 0 ) 2 σ x 2 + ( y − y 0 ) 2 σ y 2 ) M\left(x,y\right)=e^{-\alpha\left(\frac{\left(x-x_0\right)^2}{\sigma_x^2}+\frac{\left(y-y_0\right)^2}{\sigma_y^2}\right)} M(x,y)=e−α(σx2(x−x0)2+σy2(y−y0)2)
其中 ( σ x , σ y ) = ( w / c , h / c ) \left(\sigma_x,\sigma_y\right)=\left(w/c,h/c\right) (σx,σy)=(w/c,h/c), α \alpha α用于控制响应图形状。在测试期间执行模型更新时,使用过去的预测作为伪标签,只在离线训练中使用GT。
跟踪网络的更新:
θ ( t ) = θ ( t − 1 ) − λ ( t − 1 ) ⊙ ∇ θ ( t − 1 ) l ( t − 1 ) \theta^{\left(t\right)}=\theta^{\left(t-1\right)}-\lambda^{\left(t-1\right)}\odot\nabla_{\theta^{\left(t-1\right)}}l^{\left(t-1\right)} θ(t)=θ(t−1)−λ(t−1)⊙∇θ(t−1)l(t−1)
学习率 λ ( t − 1 ) \lambda^{\left(t-1\right)} λ(t−1)由LSTM根据以前的学习率 λ ( t − 2 ) \lambda^{\left(t-2\right)} λ(t−2)、当前参数 θ ( t − 1 ) \theta^{\left(t-1\right)} θ(t−1)、更新损失 ℓ ( t − 1 ) \ell^{\left(t-1\right)} ℓ(t−1)
及其梯度 ∇ θ ( t − 1 ) l ( t − 1 ) \nabla_{\theta^{\left(t-1\right)}}l^{\left(t-1\right)} ∇θ(t−1)l(t−1)得到:
I ( t − 1 ) = [ λ ( t − 2 ) , ∇ θ ( t − 1 ) l ( t − 1 ) , θ ( t − 1 ) , l ( t − 1 ) ] \mathcal{I}^{\left(\mathcal{t}-1\right)}=\left[\lambda^{\left(t-2\right)},\nabla_{\theta^{\left(t-1\right)}}l^{\left(t-1\right)},\theta^{\left(t-1\right)},l^{\left(t-1\right)}\right] I(t−1)=[λ(t−2),∇θ(t−1)l(t−1),θ(t−1),l(t−1)]
λ ( t − 1 ) = σ ( O ( I ( t − 1 ) ; ω ) ) \lambda^{\left(t-1\right)}=\sigma\left(\mathcal{O}\left(\mathcal{I}^{\left(\mathcal{t}-1\right)};\omega\right)\right) λ(t−1)=σ(O(I(t−1);ω))
O ( ⋅ ; ω ) \mathcal{O}\left(\cdot;\omega\right) O(⋅;ω)是带参 ω \omega ω的LSTM,σ是sigmoid。根据n个更新样本的小批量计算得到当前更新损失:
l ( t − 1 ) = 1 n ∑ j = 1 n L ( F j , M j , B j ; θ ( t − 1 ) , ϕ ( t − 1 ) ) l^{\left(t-1\right)}=\frac{1}{n}\sum_{j=1}^{n}L\left(F_j,M_j,B_j;\theta^{\left(t-1\right)},\phi^{\left(t-1\right)}\right) l(t−1)=n1j=1∑nL(Fj,Mj,Bj;θ(t−1),ϕ(t−1))
样本 ( F j , M j , B j ) \left(F_j,M_j,B_j\right) (Fj,Mj,Bj)在过去的τ帧中选取。在随机选择的未来帧上测试新近更新的模型 θ ( t ) \theta^{\left(t\right)} θ(t)获得元损失:
L ( t ) = L ( F ( t + δ ) , M ( t + δ ) , B ( t + δ ) ; θ ( t ) , ϕ ( t − 1 ) ) \mathcal{L}^{\left(\mathcal{t}\right)}=L\left(F^{\left(t+\delta\right)},M^{\left(t+\delta\right)},B^{\left(t+\delta\right)};\theta^{\left(t\right)},\phi^{\left(t-1\right)}\right) L(t)=L(F(t+δ),M(t+δ),B(t+δ);θ(t),ϕ(t−1))
δ 在[0,τ − 1]中随机产生。
在离线训练阶段对一小段视频执行上述过程,并获得平均元损失,以优化该优化器:
L ‾ = 1 N T ∑ i = 1 N ∑ t = 1 T L V i ( t ) \overline{\mathcal{L}}=\frac{1}{NT}\sum_{i=1}^{N}\sum_{t=1}^{T}\mathcal{L}_{\mathcal{V}_\mathcal{i}}^{\left(\mathcal{t}\right)} L=NT1i=1∑Nt=1∑TLVi(t)
其中N是batch size,T是模型更新次数。 V i ∼ p ( V ) \mathcal{V}_\mathcal{i} \sim p\left(\mathcal{V}\right) Vi∼p(V)是从训练集采样的视频片段。初始模型参数 θ ( 0 ) \theta^{\left(0\right)} θ(0)和初始学习率 λ ( 0 ) \lambda^{\left(0\right)} λ(0)也是可训练参数,和优化器一同训练;通过最小化元损失就能够训练得到一个优化器。

Random Filter Scaling
优化器由于过拟合的风险难以充分适应新任务,作者发现经过初步训练的优化器会预测相似的学习率。如果网络输入的变化幅度不够大,那么优化器容易过拟合。
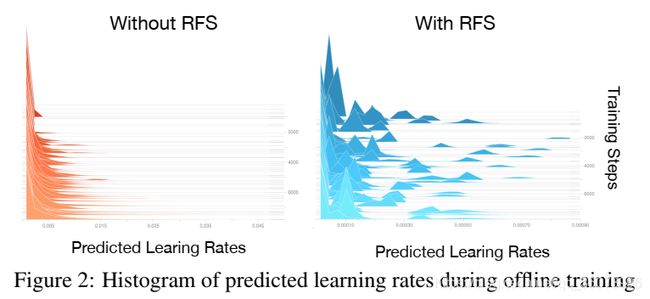
为了解决这个问题,将跟踪模型θ乘以随机采样的向量 ϵ \epsilon ϵ,该向量在离线训练的每次迭代中与θ的维数相同。
ϵ ∼ exp ( U ( − κ , κ ) ) , θ ϵ = ϵ ⊙ θ \epsilon\sim\exp{\left(\mathcal{U}\left(-\kappa,\kappa\right)\right)},\theta_\epsilon=\epsilon\odot\theta ϵ∼exp(U(−κ,κ)),θϵ=ϵ⊙θ
U ( − κ , κ ) \mathcal{U}\left(-\kappa,\kappa\right) U(−κ,κ)表示均匀分布,用 κ \kappa κ控制尺度。目标函数修改为 g ϵ ( θ ) = g ( θ ϵ ) g_\epsilon\left(\theta\right)=g\left(\frac{\theta}{\epsilon}\right) gϵ(θ)=g(ϵθ),这在不修改训练样本(x; y)的情况下间接地缩放了网络输入x。
Online Tracking via Proposed Framework
跟踪的过程和离线训练相似,除了不用计算元损失及其梯度:
· Model Initialization
· Bounding Box Estimation
· Model Updating
Implementation Details
Patch Cropping: S = S w = S h = γ w h S=S_w=S_h=\gamma\sqrt{wh} S=Sw=Sh=γwh,γ是ROI的尺度因子,w、h是目标尺寸,裁剪出S×S的patch。
Network Structure:VGG-16的前12层卷积并去掉最后的池化层。响应生成网络和边界框回归网络均由两个卷积层组成,其中第一层是512×64×1×1的降维层,第二层分别是64×1×21×21的correlation层或64×4×21×21的回归层;优化器O使用两个具有20个隐藏单元的堆叠LSTM层。
ROI比例因子为γ= 5,搜索区域S =281,滤波器大小的比例因子为ρ= 1:5;响应生成器α= 20,特征提取的feature map的步长c = 4。
Training Details:ADAM…
Experiments
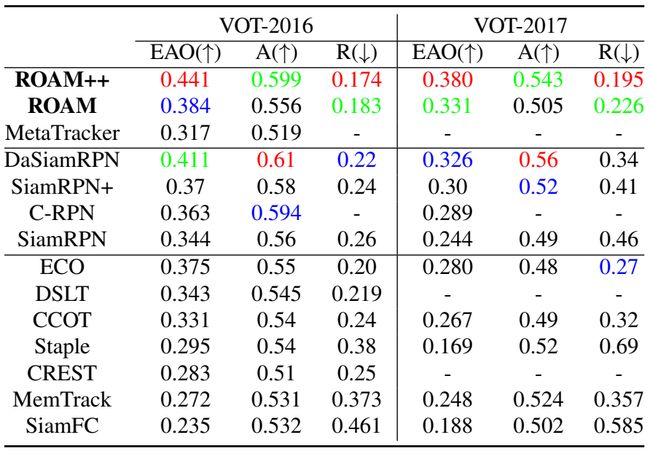
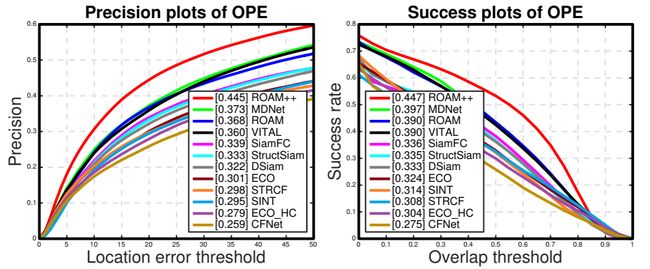
VOT&LaSOT:
GOT-10k:
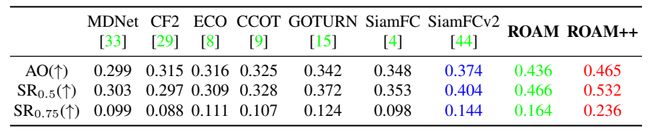
…