深度学习语音识别方法概述与分析
1 语音识别方法研究现状
随着人机交互技术越来越受到人们的重视,而人通过语音与计算机进行交互是除了手动键盘输入之外最自然最基本的交互方式,所以也越来越引起研究人员的关注。语音识别方法即自动语音识别( automatic speech recognition,ASR) 技术,主要是完成语音到文字的转变,属于非特定人语音识别。语音识别发展到现在,已经改变了人们生活的很多方面,从语音打字机、数据库检索到特定的环境所需的语音命令,给人们的生活带来了很多方便。
2006年,由于深度学习理论在机器学习中初步的成功应用,开始引起人们的关注。在接下来的几年里,机器学习领域的研究热点开始逐步地转向深度学习。深度学习使用多层的非线性结构将低层特征变换成更加抽象的高层特征,以有监督或者无监督的方法对输入特征进行变换,从而提升分类或者预测的准确性。深度学习模型一般是指更深层的结构模型,它比传统的浅层模型拥有更多层的非线性变换,在表达和建模能力上更加强大,在复杂信号的处理上会更具优势相比于传统的高斯混合模型-隐马尔科夫模型语音识别系统获得了超过20%的相对性能提升。此后,基于深度神经网络的声学模型逐渐替代了GMM 成为语音识别声学建模的主流模型,并极大地促进了语音识别技术的发展,突破了某些实际应用场景下对语音识别性能要求的瓶颈,使语音识别技术走向真正实用化。
目前许多国内外知名研究机构,如微软、讯飞、Google、IBM 都积极开展对深度学习的研究。在人们生活的应用层面上,由于移动设备对语音识别的需求与日俱增,以语音为主的移动终端应用不断融入人们的日常生活中,如国际市场上有苹果公司的Siri、微软的 Cortana 等虚拟语音助手; 国内有百度语音、科大讯飞等。还有语音搜索( VS) 、短信听写( SMD) 等语音应用都采用了最新的语音识别技术。现在,绝大多数的SMD系统的识别准确率都超过了90%,甚至有些超过了95%,这意味着新一轮的语音研究热潮正在不断兴起。
2 深度学习语音识别方法
这一章将详细介绍深度学习在语音识别领域的应用。包括深度学习进行语音识别的训练准则即目标函数;基于深度学习的语音识别模型、结构或类型;如何提高深度学习训练语音识别模型的效率;说话人自适应模型。
2.1 深度学习的语音识别模型训练准则
相比于传统的基于GMM-HMM的语音识别框架,其最大的改变是采用DNN替换GMM模型来对语音的观察概率进行建模。DNN相比于GMM的优势在于:(1)使用DNN估计 HMM状态的后验概率分布不需要对语音数据分布进行假设;(2)DNN的输入特征可以是多种特征的融合,包括离散或者连续的;(3)DNN可以利用相邻语音帧所包含的结构信息。
最初主流的深层神经网络是最简单的全连接神经网络(FNN)。对于1个包含 L个隐层的FNN,其整个模型可以表示为如下公式: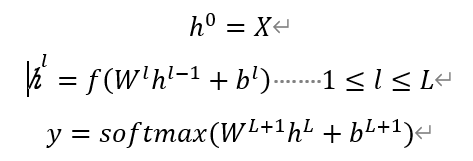
其中X表示输入层的语音特征;W,和b表示神经网络的参数;f表示隐层的激活函数。输出层采用softmax函数输出每个分类的后验概率。通过网络的输出和对应的标注可以设计相应的优化目标函数进行模型的优化。交叉熵 (Cross—entropy,CE)函数经常被用作优化目标函数。CE用来衡量目标输出概率分布和实际输出概率分布之间的相似程度,其值熵越小相似程度越高,从而模型的性能也就越好。FCEW=-r=1Nt=1Tlogyrt(srt) yrt(s) 表示在t时刻第r句话在状态s下对应的Softmax函数的输出值,srt 表示Xrt的类标。不过交叉熵是定义在帧级别上的优化准则,由于语音信号是一个时序信号,所以更为合适的优化准则应该是定义在整个序列上的优化准则。最大互信息量、最小音素错误率、状态级最小贝叶斯风险和增强型最大互信息量是定义在整个语音序列上的优化准则,用来训练DNN-HMM声学模型。结果表明,不同句子级区分性准则可以获得相近的性能,同时相比于CE准则可以获得大概10%的相对性能提升。
2.2 深度学习的语音识别模型结构和类型
2009年DNN首次被应用到语音识别领域,DNN-HMM模型示意如图2-1。当时研究人员做的实验是在3h的TIMIT数据库上进行的音素识别实验。网络的输入是拼接帧的语音声学特征,利用DNN进行特征提取和变换,预测目标则是61个音素对应的183个HMM状态。实验验证了通过预训练技术可以训练包含多个隐层的神经网络,而且随着隐层数目的增加,效果也在提升。

图2-1 DNN-HMM架构
早期的DNN普遍采用sigmoid函数作为激活函数,但是sigmoid函数很容易受到梯度消失问题的困扰。后来人们采用ReLU代替sigmoid,不仅可以获得更好的性能,而且不需要进行预训练,直接随机初始化即可。通过合理的参数设置,采用ReLU的网络可以使用大批量的随机梯度下降(SGD)算法进行优化 。
相比于DNN,在图像领域获得了广泛应用的CNN通过采用局部滤波和最大池化技术可以获得更加鲁棒性的特征。而语音信号的频谱特征也可以看做一幅图像,每个人的发音存在很大的差异性,例如共振峰的频带在语谱图上就存在不同。所以通过CNN,有效地去除这种差异性将有利于语音的声学建模。最近的几年的一些工作也表明,基于CNN的语音声学模型 相比于DNN可以获得更好的性能。Sainath等人中通过采用2层CNN,再添加4层DNN的结构,相比于6层DNN,在大词汇量连续语音识别任务上可以获得相对3%-5%的性能提升。虽然CNN被应用到语音识别中已有很长一段时间, 但是都只是把CNN当作一种鲁棒性特征提取的工具,所以一般只是在底层使用1~2层的CNN层,然后高层再采用其他神经网络结构进行建模。在2015年,CNN在语音识别得到了新的应用,相比于之前的工作,最大的不同是使用了非常深层的CNN结构,包含10层甚至更多的卷积层。研究结果也表明深层的CNN往往可以获得更好的性能。
语音信号是一种非平稳时序信号,如何有效地对长时时序动态相关性进行建模至关重要。由于DNN和CNN对输入信号的感受视野相对固定,所以对于长时时序动态相关性的建模存在一定的缺陷。RNN通过在隐层添加一些反馈连接,使得模型具有一定的动态记忆能力,对长时时序动态相关性具有较好的建模能力。2013年Graves最早尝试将RNN用于语音识别的声学建模,在TIMIT语料库上取得了当时最好的识别性能。由于简单的RNN会存在梯度消失问题,一个改进的模型是基于长短时记忆单元(Long-short term memory,LSTM)的递归结构。Sak等人使用LSTM-HMM在大数据库上获得了成功。此后大量的研究人员转移到基于LSTM的语音声学建模的研究中。
虽然LSTM相比于DNN在模型性能上有极大的优势,但是训练LSTM需要使用沿时间展开的反向传播算法算法,会导致训练不稳定,而且训练相比于DNN会更加耗时。因此如何让前馈型的神经网络也能像LSTM一样具有长时时序动态相关性的建模能力是一个研究点。Saon等人提出将RNN沿着时间展开,可以在训练速度和DNN可比的情况下获得更好的性能。但是进一步的把LSTM 结构沿时间展开就比较困难。
2.3 提高语音识别模型训练效率
大数据时代的到来,使得可以获得语音数据越来越多。而基于深度学习的语音识别模型又是极其复杂的,所以提高模型的训练效率是非常迫切的需要。如果训练效率低下,不论是在科研院校还是工业界,都是无法进行实际应用的,所以模型的训练效率是这个模型能否从理论到实际的关键。我们很自然的想到从两个方向来提高训练效率。一是设计更简洁的网络架构,二是利用硬件设备加速训练。这两个方法也是深度学习领域最为常见的方法。
针对于语音识别模型,常见模型包含6个隐层,共2048个节点。Yu等人研究表明,这些模型有很大的冗余性,DNN中训练后许多参数小于0.1,所以可以设置参数阈值为0.1,小于0.1的参数强制设置为0,相关实验结果也表明,这样的设置几乎不影响模型的性能。这样的做法可以有效降低神经网络的参数并且大大提高神经网络训练效率。另外的一些研究人员,也提出了一些诸如稀疏矩阵分解、剪枝的方法来减少神经网络的训练参数,从而提高训练效率。
然后就是利用多GPU进行并行计算的方法,这个属于普遍方法并不针对于语音识别模型关系不大,就在这里不讨论了
2.4 语音识别模型的说话人自适应
一般来说,说话人无关模型在语音识别性能上要劣于说话人相关模型,但说话人相关模型需要每一特定说话人的大量语音用于训练,实际应用不具可行性。语音识别声学模型的说话人自适应一般可使识别性能优于说话人无关模型,并且所需的特定说话人的数据量远低于说话人相关模型的数据量要求。
基于深度学习的语音识别声学模型的自适应研究主要集中在模型域自适应,主要可以归纳为如下几种:
(1)基于说话人特征的自适应方法。其主要思路是通过一种包含说话人信息并且能够区分不同说话人的特征矢量,实现对基于深度学习的语音识别声学模型的自适应。鉴别性矢量(i-vector)是一种包含说话人信息和信道信息的矢量,基于i-vector的说话人自适应方法利用每个说话人的语料提取对应的i-vector,然后将i-vector同声学特征相融合,从而实现模型域上的说话人自适应。
(2)基于模型正则化的说话人自适应方法。该方法直接用特定说话人的少量数据调整一个说话人无关模型,并通过模型正则化避免易产生的模型过拟合问题。Yu等人提出了一种基于KL散度的说话人自适应方法,该方法通过KL散度约束自适应后模型的后验概率分布 不至于偏离说话人无关模型的分布太远来实现模型的规整。
(3)基于线性变换的说话人自适应方法。该方法在原始的说话人无关的基于深度学习的语音识别 声学模型中插入一个或若干线性变换层,该变换层通过自适应训练后起到将说话人无关模型转换为特 定说话人模型的作用。
(4)基于多基融合的说话人自适应方法。该方法在声学模型空间建立一组基,这组基可以是基于深度学习的语音识别声学模型,也可以是对应的深层声学模型网络的联结权重。再利用每个说话人的语音数据通过训练来获得对应的插值矢量,通过该插值矢量来对基进行插值,从而获得特定说话人的声学模型。
(5)基于激活函数的说话人自适应方法。该方法认为每个说话人在深层声学模型网络节点上的激活程度不一样,因而可以对每个说话人构造一组特定的激活函数实现说话人自适应,该激活函数可以利用赫尔米特正交函数,或者是参数化的Sigmoid和参数化的ReLU函数来构建。
说话人无关模型只需要训练和测试两个阶段,而说话人自适应模型一般需要训练、自适应和测试3个阶段。因此,在实际应用中,自适应阶段会影响语音识别模型的实时性。基于i-vector的说话人特征自适应虽然不需要自适应阶段、在实时性上能够满足实际要求,但是,从较短、带噪的句子提取的i-vector往往不能够非常好地表达说话人信息,因而会出现自适应后性能提升不明显甚至性能变差的情况。另外,实验表明,现有的说话人自适应方法大多会出现少部分人经过自适应后性能变差的情况,也是值得注意需要解决的问题。
3 端到端的语音识别模型
以上所讨论的基于深度学习的语音识别声学模型建模技术,在模型训练上仍依赖于传统的基于GMM-HMM语音识别技术。但是传统方法尤其天然局限性,HMM的假设帧的生成概率只跟当前状态有关,跟历史状态和历史帧无关;DNN的声学模型用来求输出状态对应的后验概率。需要用到GMM的对齐结果,来获得每一帧的label。首先需要GMM的对齐结果比较准确,其次是本身语音的边界不好界定,这样每一帧给一个指定label本身值得商榷。。针对此问题,基于深度学习的语音识别技术近期的一个研究热点是如何进行端到端的语音识别。
3.1 基于CTC算法的RNN网络
连续时序分类(Connectionist temporal classification,CTC)是目前最常用的结合神经网络训练的算法之一。语音识别声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。 CTC的引入可以放宽了这种一一对应的限制要求,只需要一个输入序列和一个输出序列即可以训练。有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。

图3-1 对齐示意图
如上图,传统的Framewise训练需要进行语音和音素发音的对齐,比如“s”对应的一整段语音的标注都是s;而CTC引入了blank(该帧没有预测值),“s”对应的一整段语音中只有一个spike(尖峰)被认为是s,其他的认为是blank。对于一段语音,CTC最后的输出是spike的序列,不关心每一个音素对应的时间长度。
这种CTC算法结合神经网络的结构除了可以应用到语音识别的声学模型训练上以外,也可以用到任何一个输入序列到一个输出序列的训练上。
比如,光学字符(OCR)识别也可以采用CTC结合RNN模型来解决,将图片转化为序列传入模型,输出是对应的汉字,因为要好多列才组成一个汉字,所以输入的序列的长度远大于输出序列的长度。而且这种实现方式的OCR识别,也不需要事先准确的检测到文字的位置,只要这个序列中包含这些文字就好了。
CTC的训练流程和传统的神经网络类似,构建loss function,然后根据BP算法进行训练,不同之处在于传统的神经网络的训练准则是针对每帧数据,即每帧数据的训练误差最小,而CTC的训练准则是基于序列(比如语音识别的一整句话)的,比如最大化P(z|x)。P(z|x),序列化的概率求解比较复杂,因为一个输出序列可以对应很多的路径,所有引入前后向算法来简化计算。

图3-2 CTC模型架构
3.2 Seq2seq(sequence to sequence)模型
Seq2seq模型是一类架构的总称,在机器翻译、语音识别、自动回答等场景广泛应用。Seq2seq通过编码器—解码器(Encoder—Decoder)框架来实现。而Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN、RNN、LSTM、GRU、BLSTM等等。所以基于Encoder-Decoder,我们可以设计出各种各样的应用算法。Seq2seq与CTC算法不同之处是,CTC主要利用时间序列局部信息,查找与序列相对的另外一个具有一对一对应关系(强相关,具有唯一性)的序列,比较适用于语音识别、OCR等场景。
Seq2Seq更善于利用更长范围的序列全局的信息,并且综合序列上下文判断,推断出与序列相对应的另一种表述序列(非强相关,不具有唯一性),相对来说更适用于机器翻译、文章主旨提取等场景。
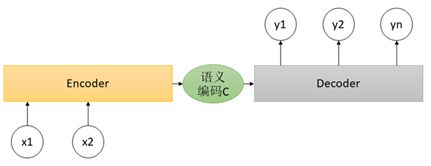
图3-3 Seq2seq模型
图3-3是一个经典的Seq2seq模型,它主要包括两个部分,编码器(Encoder)和解码器(Decoder)。语义编码C是编码器输出的中间状态,它将作为解码器的输入。X是输入序列,x1、x2分别代表每个时间步的输入,Y是输出序列。它的基本思想是用语义编码C表示编码器输入的语义概要,解码器依据此语义概要输出。并且编码器的输入长度和解码器的输出长度可以不同,这就可以灵活解决时间序列问题。
Seq2seq模型能够解决任意的序列对应关系,但同时从编码到解码的准确率很大程度上依赖于一个固定长度的语义向量c,输入序列到语义向量c的压缩过程中存在信息的丢失,并且在稍微长一点的序列上,在前面的信息很容易受到后面信息覆盖,解码准确率自然会受到影响。其次在解码的时候,每个时刻的输出在解码过程中用到的上下文向量是相同的,没有做区分,也就是说预测结果中每一个词的的时候所使用的预测向量都是相同的,这也会给解码带来问题。
为了解决上述问题,研究人员提出了注意力机制(attention mechanism)。在预测每个时刻的输出时用到的上下文是跟当前输出有关系的上下文,而不是统一只用相同的一个。这样在预测结果中的每个词汇的时候,每个语义向量c中的元素具有不同的权重,可以更有针对性的预测结果。
如图3-4是增加注意力机制的Seq2seq模型。attention模型最大的不同在于编码器将输入序列编成一个向量的序列;而在解码时,每一步都会选择性的从序列中挑选一个子集进行输出预测。如此,在产生每一个输出的时候,都能找到当前输入对应的应该重点关注的序列信息,也就是说,每一个输出单词在计算的时候,参考的语义编码向量c都是不一样的,所以说它们的注意力焦点是不一样的。

图3-4 有注意力机制的Seq2seq
4 总结
本文主要概述了深度学习方法在语音识别模型上的应用。介绍了DNN—HMM模型想对于传统GMM-HMM模型的优势,以及分析了深度学习训练中存在的问题。并主要介绍了基于CTC算法和Seq2seq框架的端到端深度学习模型,并在后面给出了一个我利用Seq2seq模型在时间序列预测方面的应用。
目前市场上的语音识别产品已经可以达到相当高的正确率,然而如何在噪声环境以及远场情况中,提高语音识别准确率依然是一个很大的挑战。