Lambda、函数式接口、Stream - 从入门到入坑
声明:本文学习自《精通Lambda表达式:Java多核编程》,以及其他网路资源,如有,会将参考原文链接附在最后,未经允许,不可转载,如有错误,也请指点。
问题1:为什么要用 lambda?
(1)Lambda 允许把函数作为一个方法的参数
(2)Lambda 表达式可以使代码变的更加简洁紧凑
问题2:Lambda 有什么特征?
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
Lambda 可以看成是一种你匿名方法,拥有更为简洁的语法,可以省略修饰符,返回类型,throws语句,在某些情况下可以省略参数类型。
问题3:Lambda 语法?
语法:包括一个参数列表和 Lambda 体,中间用 -> 分割
// 单参数、当操作
parameter -> expression 或
// 多参数、多操作
(parameter1, parameter2) ->{
statements;
}
实例:
// 表达式、无参数
() -> System.out.println("hello xpwi");
// 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 接受2个参数(数字),并返回他们的差值
(x, y) -> x – y
// 接收2个int型整数,返回他们的和
(int x, int y) -> x + y
// 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> {
System.out.print(s);
System.out.print(s + "=S");
}
这就是 Lambda 表达式,但肯定会有疑问,What???
问题4:怎么使用这个表达式?作为参数吗?返回值是什么?
它的返回值是一个接口,我们可以这样写:
// 执行
@Test
public void test() {
runnable.run();
}
// 定义
Runnable runnable = () -> {
System.out.println("hello");
System.out.println("xpwi");
};
这可能会想到多线程中有 Runnable 接口创建方式,这里没有多线程的意思,只是使用一个接口,使用它的名称含义,里面有一个 run() 方法,表示启动,running。。。
问题5:那么接口是任意的接口吗?可以自己定义吗?
接口可以是自定义的接口,但是该接口要符合函数式接口规范
问题6:什么是函数式接口?
(1)只包含一个抽象方法,可以有其他非抽象方法。
(2)可以通过 Lambda 表达式来创建该接口的对象。
(3)可以接口上使用 @FunctionalInterface 注解,编译时检查它是否是一个函数式接口
问题7:具体怎么定义接口?
自定义接口:
// 一般都不这么用,不需要自定义,这里用于说明
@FunctionalInterface
public interface MyNoticeInterface {
public abstract Boolean doNotice(String user);
default String dotice(String user) {
return "null";
}
}
接口的使用:
@Test
public void test() {
Boolean xpwi = noticeInterface.doNotice("xiaopengwei");
System.out.println(xpwi);
}
private MyNoticeInterface noticeInterface = (user) -> {
System.out.println("hello");
System.out.println(user);
return true;
};
问题8:不想自己定义接口,怎么办???
JDK 1.8 之前已有的函数式接口:
- java.lang.Runnable
- java.util.concurrent.Callable
- java.security.PrivilegedAction
- java.util.Comparator
- java.io.FileFilter
- java.nio.file.PathMatcher
- java.lang.reflect.InvocationHandler
- java.beans.PropertyChangeListener
- java.awt.event.ActionListener
- javax.swing.event.ChangeListener
JDK 1.8 新增加的函数接口:在 java.util.function 包下:
也可以在菜鸟教程看: 菜鸟教程-JAVA8函数式接口
问题9:常用函数式接口
| 序号 | 函数式接口 | 抽象方法 | 描述 |
|---|---|---|---|
| 1 | BiConsumer |
void accept(T t, U u); | 代表了一个接受两个输入参数的操作,并且不返回任何结果;其他:andThen() |
| 2 | BiFunction |
R apply(T t, U u); | 代表了一个接受两个输入参数的方法,并且返回一个结果 |
| 3 | BinaryOperator | R apply(T t, U u); | 代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果;继承自:BiFunction |
| 4 | BiPredicate |
boolean test(T t, U u); | 代表了一个两个参数的boolean值方法 |
| 5 | BooleanSupplier | boolean getAsBoolean(); | 代表了boolean值结果的提供方 |
| 6 | Consumer | void accept(T t); | 代表了接受一个输入参数并且无返回的操作 |
| 7 | DoubleBinaryOperator | double applyAsDouble(double left, double right); | 代表了作用于两个double值操作符的操作,并且返回了一个double值的结果。 |
| 8 | DoubleConsumer | void accept(double value); | 代表一个接受double值参数的操作,并且不返回结果。 |
| 9 | DoubleFunction | R apply(double value); | 代表接受一个double值参数的方法,并且返回结果 |
| 10 | DoublePredicate | boolean test(double value); | 代表一个拥有double值参数的boolean值方法 |
| 11 | DoubleSupplier | double getAsDouble(); | 代表一个double值结构的提供方 |
| 12 | DoubleToIntFunction | int applyAsInt(double value); | 接受一个double类型输入,返回一个int类型结果。 |
| 13 | DoubleToLongFunction | long applyAsLong(double value); | 接受一个double类型输入,返回一个long类型结果 |
| 14 | DoubleUnaryOperator | double applyAsDouble(double operand); | 接受一个参数同为类型double,返回值类型也为double 。 |
| 15 | Function |
R apply(T t); | 接受一个输入参数,返回一个结果。 |
| 16 | IntBinaryOperator | int applyAsInt(int left, int right); | 接受两个参数同为类型int,返回值类型也为int 。 |
| 17 | IntConsumer | void accept(int value); | 接受一个int类型的输入参数,无返回值 。 |
| 18 | IntFunction | R apply(int value); | 接受一个int类型输入参数,返回一个结果 。 |
| 19 | IntPredicate | boolean test(int value); | 接受一个int输入参数,返回一个布尔值的结果。 |
| 20 | IntSupplier | int getAsInt(); | 无参数,返回一个int类型结果。 |
| 21 | IntToDoubleFunction | double applyAsDouble(int value); | 接受一个int类型输入,返回一个double类型结果 。 |
| 22 | IntToLongFunction | long applyAsLong(int value); | 接受一个int类型输入,返回一个long类型结果。 |
| 23 | IntUnaryOperator | int applyAsInt(int operand); | 接受一个参数同为类型int,返回值类型也为int 。 |
| 24 | LongBinaryOperator | long applyAsLong(long left, long right); | 接受两个参数同为类型long,返回值类型也为long。 |
| 25 | LongConsumer | void accept(long value); | 接受一个long类型的输入参数,无返回值。 |
| 26 | LongFunction | R apply(long value); | 接受一个long类型输入参数,返回一个结果。 |
| 27 | LongPredicate | boolean test(long value); | R接受一个long输入参数,返回一个布尔值类型结果。 |
| 28 | LongSupplier | long getAsLong(); | 无参数,返回一个结果long类型的值。 |
| 29 | LongToDoubleFunction | double applyAsDouble(long value); | 接受一个long类型输入,返回一个double类型结果。 |
| 30 | LongToIntFunction | int applyAsInt(long value); | 接受一个long类型输入,返回一个int类型结果。 |
| 31 | LongUnaryOperator | long applyAsLong(long operand); | 接受一个参数同为类型long,返回值类型也为long。 |
| 32 | ObjDoubleConsumer | void accept(T t, double value); | 接受一个object类型和一个double类型的输入参数,无返回值。 |
| 33 | ObjIntConsumer | void accept(T t, int value); | 接受一个object类型和一个int类型的输入参数,无返回值。 |
| 34 | ObjLongConsumer | void accept(T t, long value); | 接受一个object类型和一个long类型的输入参数,无返回值。 |
| 35 | Predicate | boolean test(T t); | 接受一个输入参数,返回一个布尔值结果。 |
| 36 | Supplier | T get(); | 无参数,返回一个结果。 |
| 37 | ToDoubleBiFunction |
double applyAsDouble(T t, U u); | 接受两个输入参数,返回一个double类型结果 |
| 38 | ToDoubleFunction | double applyAsDouble(T value); | 接受一个输入参数,返回一个double类型结果 |
| 39 | ToIntBiFunction |
int applyAsInt(T t, U u); | 接受两个输入参数,返回一个int类型结果。 |
| 40 | ToIntFunction | int applyAsInt(T value); | 接受一个输入参数,返回一个int类型结果。 |
| 41 | ToLongBiFunction |
long applyAsLong(T t, U u); | 接受两个输入参数,返回一个long类型结果。 |
| 42 | ToLongFunction | long applyAsLong(T value); | 接受一个输入参数,返回一个long类型结果。 |
| 43 | UnaryOperator | R apply(T t); | 接受一个参数为类型T,返回值类型也为T;继承自:Function。 |
问题10:写个函数式接口实例?
@Slf4j
public class LambdaTest {
@Test
public void test() {
String user = "xiaopengwei";
Integer age = 18;
noticeHandler.accept(user);
noticeWithAgeHandler.accept(user, age);
}
private Consumer<String> noticeHandler = (String user) -> {
log.info("通知: " + user);
};
private BiConsumer<String, Integer> noticeWithAgeHandler = (user, age) -> {
log.info("通知: user=" + user + ", age=" + age);
};
}
像 BiConsumer 后的泛型,编译时,不写也可以通过上下文推断,但个人认为都必须要写上。
问题11:andThen() 怎么使用?
对于相同的参数,进行多个操作,可以直接使用 andThen(),简化写法:
// andThen
@Slf4j
public class LambdaTest {
@Test
public void test() {
String user = "xiaopengwei";
noticeHandler.andThen(thenNoticeHandler).accept(user);
}
private Consumer<String> noticeHandler = (String user) -> {
log.info("通知: " + user);
};
private Consumer<String> thenNoticeHandler= (user) -> {
log.info("after andThen 通知: user=" + user);
};
}
当然,也可以一直往后挂,,
@Slf4j
public class LambdaTest {
@Test
public void test() {
String user = "xiaopengwei";
noticeHandler.andThen(thenNoticeHandler).andThen(thenThenNoticeHandler).accept(user);
}
private Consumer<String> noticeHandler = (String user) -> {
log.info("通知: " + user);
};
private Consumer<String> thenNoticeHandler = (user) -> {
log.info("after andThen 通知: user=" + user);
};
private Consumer<String> thenThenNoticeHandler = (user) -> {
log.info("after andThen Then 通知: user=" + user);
};
}
问题12:好了,Stream 呢??
Stream 的介绍,查看: 菜鸟教程-Java 8 Stream
让程序员写出高效率、干净、简洁的代码。
惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
Java 8 stream的详细用法
这篇文章有比较的介绍,这里主要说一下分类:
文章中有这样的分类:
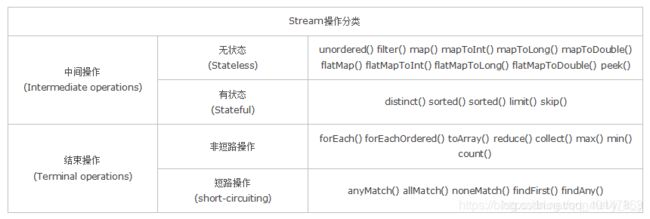
- 无状态:指元素的处理不受之前元素的影响;
- 有状态:指该操作只有拿到所有元素之后才能继续下去。
- 非短路操作:指必须处理所有元素才能得到最终结果;
- 短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
(1)创建流的场景
list.stream(); // 串流
list.parallelStream(); // 并行流
// 数组流
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
// 使用Stream中的静态方法:of()、iterate()、generate() 创建
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::println); // 0 2 4 6 8 10
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::println);
// 使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
// 使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
(2)流的中间操作
1、筛选与切片
| 操作 | 描述 |
|---|---|
| filter | 过滤流中的某些元素 |
| limit(n) | 获取n个元素 |
| skip(n) | 跳过n元素,配合limit(n)可实现分页 |
| distinct | 通过流中元素的 hashCode() 和 equals() 去除重复元素 |
2、映射
| 操作 | 描述 |
|---|---|
| map | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| flatMap | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。 |
3、排序
| 操作 | 描述 |
|---|---|
| sorted() | 自然排序,流中元素需实现Comparable接口 |
| sorted(Comparator com) | 定制排序,自定义Comparator排序器 |
4、消费
| 操作 | 描述 |
|---|---|
| peek | 如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。 |
流的终止操作
1、匹配、聚合操作
| 操作 | 描述 |
|---|---|
| allMatch | 接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false |
| noneMatch | 接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false |
| anyMatch | 接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false |
| findFirst | 返回流中第一个元素 |
| findAny | 返回流中的任意元素 |
| count | 返回流中元素的总个数 |
| max | 返回流中元素最大值 |
| min | 返回流中元素最小值 |
2、规约操作
Optional reduce(BinaryOperator accumulator):第一次执行时,accumulator 函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
T reduce(T identity, BinaryOperator accumulator):流程跟上面一样,只是第一次执行时,accumulator 函数的第一个参数为 identity,而第二个参数为流中的第一个元素。
U reduce(U identity,BiFunction
3、收集操作
| 操作 | 描述 |
|---|---|
| collect | 接收一个Collector实例,将流中元素收集成另外一个数据结构。 |
问题13:Stream 常见实例代码?
比较常见的处理,重复却又无趣,却又必须
代码示例:
// 比较常见的场景
@Slf4j
public class StreamTest {
@Test
public void test() {
List<UserDTO> userDTOS = userBOSupplier.get();
AtomicInteger begin = new AtomicInteger(1);
List<UserBO> userBOs = userDTOS.stream().filter(bo -> bo.getEyesColor().equals("red"))
.sorted((Comparator.comparingInt(UserDTO::getUserAge)))
.map(dto -> {
UserBO userBO = new UserBO(dto.getUserName(), dto.getUserAge(), begin.getAndIncrement());
return userBO;
}).collect(Collectors.toList());
log.info("根据年龄排序的, 红色眼睛的, 用户" + JSONObject.toJSONString(userBOs));
}
private Supplier<List<UserDTO>> userBOSupplier = () -> {
UserDTO user1 = new UserDTO("John", 31, "blue");
UserDTO user2 = new UserDTO("Bob", 34, "red");
UserDTO user3 = new UserDTO("Lucy", 32, "red");
UserDTO user4 = new UserDTO("Tom", 33, "black");
return new ArrayList<>(Arrays.asList(user1, user2, user3, user4));
};
}
用户 BO 对象:
@Data
@AllArgsConstructor
public class UserBO {
private String userName;
private Integer userAge;
private Integer sort;
}
用户 DTO 实体:
@Data
@AllArgsConstructor
public class UserDTO {
private String userName;
private Integer userAge;
private String eyesColor;
}
问题14:GET
偷偷说一下,我的公众号 ID:javajobs
参考链接
(1)菜鸟教程 https://www.runoob.com/java/java8-lambda-expressions.html
(2)知乎 https://www.zhihu.com/question/20125256
(3)https://blog.csdn.net/y_k_y/article/details/84632889