MaskRCNN源码解析1:整体结构概述
MaskRCNN源码解析1:整体结构概述
MaskRCNN源码解析2:特征图与anchors生成
MaskRCNN源码解析3:RPN、ProposalLayer、DetectionTargetLayer
MaskRCNN源码解析4-0:ROI Pooling 与 ROI Align理论
MaskRCNN源码解析4:头网络(Networks Heads)解析
MaskRCNN源码解析5:损失部分解析
目录
一, MaskRCNN概述:
二,代码整体解析:
1,从下到上层
2,从上到下层与横向连接
3,RPN
4,ProposalLayer
5,DetectionTargetLayer
6,头网络 Network Heads
7,计算各部分的损失
三,进一步解析:
A),特征图与anchors生成
B),RPN、ProposalLayer、DetectionTargetLayer
C),头网络解析
D),损失部分解析
一, MaskRCNN概述:
Mask R-CNN是一个小巧、灵活的通用对象实例分割框架(object instance segmentation)。它不仅可对图像中的目标进行检测,还可以对每一个目标给出一个高质量的分割结果。它在Faster R-CNN[1]基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(object mask)的新分支。该网络还很容易扩展到其他任务中,比如估计人的姿势,也就是关键点识别(person keypoint detection)。该框架在COCO的一些列挑战任务重都取得了最好的结果,包括实例分割(instance segmentation)、候选框目标检测(bounding-box object detection)和人关键点检测(person keypoint detection)。
参考文章:
Mask RCNN 学习笔记
MaskRCNN源码解读
令人拍案称奇的Mask RCNN
论文笔记:Mask R-CNN
Mask R-CNN个人理解
解析源码地址:
https://github.com/matterport/Mask_RCNN
二,代码整体解析:
解析的该代码粗略估计有5000-6000行,相对于python来说代码量还是很庞大的。好在该代码封装的很好,没有冗余的结构,整体逻辑非常清晰,只要有耐心,还是能看懂的。
下面这张图是MaskRCNN算法结构图:
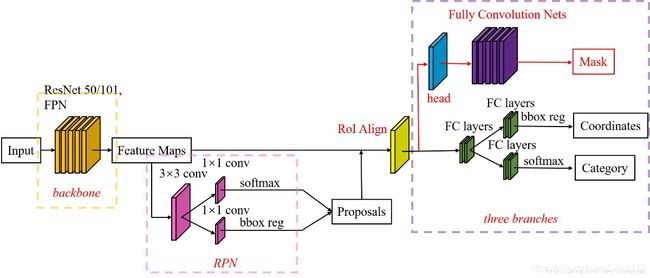
下面这张图是我根据代码画出来的(class MaskRCNN())代码逻辑结构图,有些地方确实不太好用简洁的方式表示,只把它当作大概的结构图看就行。

从上图可以看到,代码共分了7个部分,分别包括:
- 1,从下到上层
- 2,从上到下层与横向连接,
- 3,RPN
- 4,ProposalLayer
- 5,DetectionTargetLayer
- 6,头网络 Network Heads
- 7,计算各部分的损失
下面简要说一下各个部分分别完成了什么功能:
1,从下到上层
该层调用 BACKBONE = "resnet101"或者 BACKBONE = "resnet50"完成从原图到[C1, C2, C3, C4, C5] 5个特征图的操作。
该层的代码和逻辑关系如下图所示:

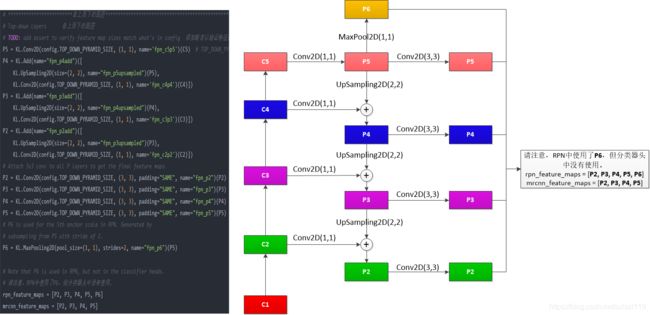
2,从上到下层与横向连接
基于从下到上得到的结果[C1, C2, C3, C4, C5],采用从上到下与横向连接的方式得到后面用到的特征图。其中:
P6由P5经过MaxPool而来,
P5由C5通过(1,1)的卷积核卷积而来,
P4由P5上采样结果与C4通过(1,1)的卷积核卷积结果相加得到,P4再由P4通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
P3由P4上采样结果与C3通过(1,1)的卷积核卷积结果相加得到,P3再由P3通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
P2由P3上采样结果与C2通过(1,1)的卷积核卷积结果相加得到,P2再由P2通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
最后由[P2,P3,P4,P5,P6]组成rpn_feature_maps用于RPN网络中,由[P2,P3,P4,P5]组成mrcnn_feature_maps用于后续的操作。
代码中在自下而上层后,RPN网络前会生成anchors:
anchors = input_anchors # 261888=256*256*3(P2)+128*128*3(P3)+64*64*3(P4)+32*32*3(P3)+16*16*33,RPN
该部分主要根据上面的到的特征图rpn_feature_maps=[P2,P3,P4,P5,P6]生成以下数据:
# rpn_class_logits:[batch_size,H * W * anchors_per_location,2] anchors分类器logits(在softmax之前)
# rpn_probs:[batch_size,H * W * anchors_per_location,2] anchors分类器概率。
# rpn_bbox:[batch_size,H * W * anchors_per_location,(dy,dx,log(dh),log(dw))] anchors的坐标偏移量
4,ProposalLayer
该部分 将第3步RPN网路的输出应用到第2步得到的anchors,
# ProposalLayer的作用主要
# 1. 根据rpn网络,获取score靠前的前6000个anchor
# 2. 利用rpn_bbox对anchors进行修正
# 3. 舍弃掉修正后边框超过图片大小的anchor,由于我们的anchor的坐标的大小是归一化的,只要坐标不超过0 1区间即可
# 4. 利用非极大抑制的方法获得最后的2000个anchor
5,DetectionTargetLayer
该部分将第5步得到的结果进行再次筛选,得到最终用于训练的200个正负样本。
# DetectionTargetLayer的输入包含了:target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。
# 其中target_rois是第5步ProposalLayer输出的结果。
# 首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,
# 如果最大的iou大于0.5,则被认为是正样本,负样本是iou小于0.5并且和crowd box相交不大的anchor,
# 选择出了正负样本,还要保证样本的均衡性,具体可以在配置文件中进行配置。
# 最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,
# 并且将mask的大小resize成28 * 28 的(我猜测利用的是双线性差值的方式,因为mask的值不是0就是1,0是背景,一是前景)
# 这些都是后面的分类和mask网络要用到的真实的值
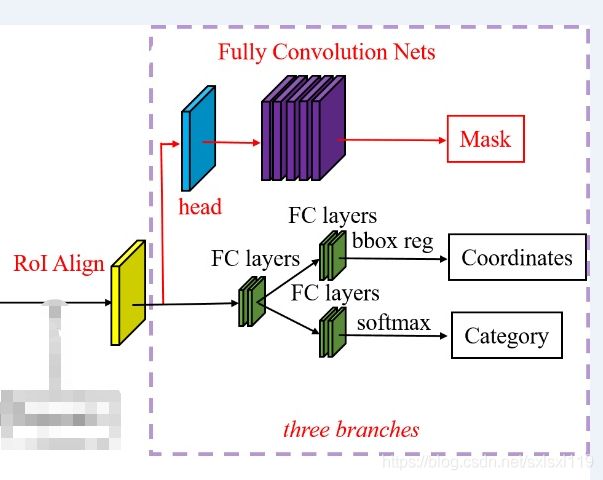
6,头网络 Network Heads
该部分包括3个分支,分别是 分类、回归操作、mask操作。对应算法结构图的以下部分。
7,计算各部分的损失
# maskrcnn中总共有五个损失函数,分别是rpn网络的两个损失,分类的两个损失,以及mask分支的损失函数。
# 前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有K*m^2维度的输出。
# k个(类别数)分辨率为m * m的二值mask。
# 因此作者利用了aper - pixelsigmoid,并且定义Lmask为平均二值交叉熵损失(the average binary cross - entropy loss).
# 对于一个属于第k个类别的RoI, Lmask仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。
# 这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
三,进一步解析:
下面会对各个部分的代码进行解析,不过拆成7个部分有点太碎了点,所以代码解析将按下面4块进行:
A),特征图与anchors生成
- 1,从下到上层
- 2,从上到下层与横向连接,anchors生成
B),RPN、ProposalLayer、DetectionTargetLayer
- 3,RPN
- 4,ProposalLayer
- 5,DetectionTargetLayer
C),头网络解析
- 6,头网络 Network Heads
D),损失部分解析
- 7,计算各部分的损失
