Scrapy爬虫爬取天气数据存储为txt和json等多种格式
一、创建Scrrapy项目
scrapy startproject weather二、 创建爬虫文件
scrapy genspider wuhanSpider wuhan.tianqi.com三、SCrapy项目各个文件
(1) items.py
import scrapy
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
cityDate = scrapy.Field()
week = scrapy.Field()
img = scrapy.Field()
temperature = scrapy.Field()
weather = scrapy.Field()
wind = scrapy.Field()
(2)wuhanSpider.py
# -*- coding: utf-8 -*-
import scrapy
from weather.items import WeatherItem
class WuhanspiderSpider(scrapy.Spider):
name = "wuHanSpider"
allowed_domains = ["tianqi.com"]
citys = ['wuhan','shanghai']
start_urls = []
for city in citys:
start_urls.append('http://' + city + '.tianqi.com/')
def parse(self, response):
subSelector = response.xpath('//div[@class="tqshow1"]')
items = []
for sub in subSelector:
item = WeatherItem()
cityDates = ''
for cityDate in sub.xpath('./h3//text()').extract():
cityDates += cityDate
item['cityDate'] = cityDates
item['week'] = sub.xpath('./p//text()').extract()[0]
item['img'] = sub.xpath('./ul/li[1]/img/@src').extract()[0]
temps = ''
for temp in sub.xpath('./ul/li[2]//text()').extract():
temps += temp
item['temperature'] = temps
item['weather'] = sub.xpath('./ul/li[3]//text()').extract()[0]
item['wind'] = sub.xpath('./ul/li[4]//text()').extract()[0]
items.append(item)
return items
import time
import os.path
import urllib2
#将获得的数据存储到txt文件
class WeatherPipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d', time.localtime())
fileName = today + '.txt'
with open(fileName,'a') as fp:
fp.write(item['cityDate'].encode('utf8') + '\t')
fp.write(item['week'].encode('utf8') + '\t')
imgName = os.path.basename(item['img'])
fp.write(imgName + '\t')
if os.path.exists(imgName):
pass
else:
with open(imgName, 'wb') as fp:
response = urllib2.urlopen(item['img'])
fp.write(response.read())
fp.write(item['temperature'].encode('utf8') + '\t')
fp.write(item['weather'].encode('utf8') + '\t')
fp.write(item['wind'].encode('utf8') + '\n\n')
time.sleep(1)
return item
import time
import json
import codecs
#将获得的数据存储到json文件
class WeatherPipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d', time.localtime())
fileName = today + '.json'
with codecs.open(fileName, 'a', encoding='utf8') as fp:
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
fp.write(line)
return itemimport MySQLdb
import os.path
#将获得的数据存储到mysql数据库
class WeatherPipeline(object):
def process_item(self, item, spider):
cityDate = item['cityDate'].encode('utf8')
week = item['week'].encode('utf8')
img = os.path.basename(item['img'])
temperature = item['temperature'].encode('utf8')
weather = item['weather'].encode('utf8')
wind = item['wind'].encode('utf8')
conn = MySQLdb.connect(
host='localhost',
port=3306,
user='crawlUSER',
passwd='crawl123',
db='scrapyDB',
charset = 'utf8')
cur = conn.cursor()
cur.execute("INSERT INTO weather(cityDate,week,img,temperature,weather,wind) values(%s,%s,%s,%s,%s,%s)", (cityDate,week,img,temperature,weather,wind))
cur.close()
conn.commit()
conn.close()
return item
(4)settings.py,决定 由哪个文件来处理获取的数据
BOT_NAME = 'weather'
SPIDER_MODULES = ['weather.spiders']
NEWSPIDER_MODULE = 'weather.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'weather (+http://www.yourdomain.com)'
#### user add
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline':1,
'weather.pipelines2json.WeatherPipeline':2,
'weather.pipelines2mysql.WeatherPipeline':3
}
scrapy crawl wuHanSpider(6)结果显示
1.txt数据
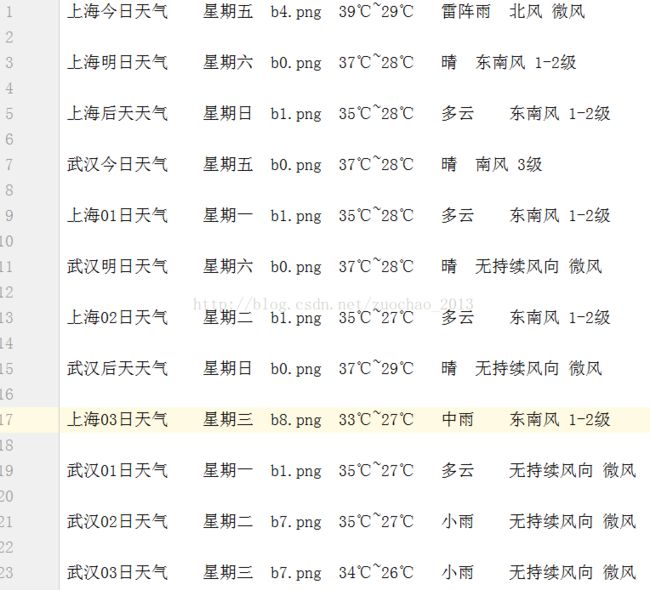
2.json数据
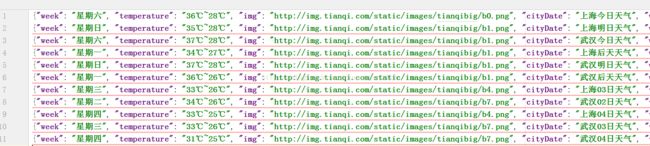
3. 存储到mysql数据库