Hadoop权威指南:知识梳理(二)
第12章 关于Avro
Apache Avro 独立于编程语言的数据序列化系统,支持压缩、可切分
意在解决Hadoop中Writable类型的不足:缺乏语言的可移植性
Avro模式
通常用json编写
Avro有丰富的模式解析能力,读数据所用的模式不必与写数据所用的模式相同
Avro定义了少量的基本数据类型,通过编写模式的方式,可以被用于构建应用特定的数据结构
- 基本类型:null / boolean / int / long / float / double / bytes / string
- 复杂类型:array / map / record / enum / fixed / union
Avro序列化:
(1) 创建Avro模式
StringPair.avsc
{
"type":"record",
"name":"StringPair",
"doc":"A pair of strings",
"fields":[
{"name":"left","type":"string"},
{"name":"right","type":"string"}
]
}
(2) 加载模式
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("StringPair.avsc"))
(3) 创建实例
GenericRecord datum = new GenericData.Record(schema); //可以用StringPair代替
datum.put("left","L");
datum.put("right","R");
(4) 输出到流
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatuWriter writer = new GenericDatumWriter(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out,null);
writer.write(datum,encoder);
encoder.flush();
out.close();
(5) 反向读回对象
DatumReader reader = new GenericDatumReader(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(),null);
GenericRecord result = reader.read(null,decoder);
assertThat(result.get("left").toString(),is("L"));
assertThat(result.get("right").toString(),is("R"));
Avro容器:
Avro容器主要存储Avro对象序列,包括:Avro模式 + sync marker + 序列化对象数据块
Avro格式打印:
java -jar $AVRO_HOME/avro-tools-*.jar tojson pairs.avro
第13章 关于Parquet
列式存储格式,parquet能够以真正的列式存储格式来保存具有深度嵌套结构的数据
parquet原子类型:boolean int32 int64 int96 float double binary fixed_len_byte_array
parquet逻辑类型:UTF8 ENUM DECIMAL DATE LIST MAP
举例:
LIST
message m {
required group a(LIST){
repeated group list{
required int32 element;}
}
}parquet利用group类型构造复杂的类型,没有注释的group就是一个简单的嵌套记录
parquet使用Dremel编码对任意一列数据的读取都不需要涉及到其他列
parquet由 文件头 + 多个文件块 + 文件尾(版本信息、模式信息、键值、元数据信息)组成
parquet读数据过程:
由于元数据保存在文件尾中,因此在读parquet文件时,首先要找到文件的结尾,然后读取文件尾中的元数据长度,并根据元数据长度逆向读取文件尾中的元数据
parquet不需要sync marker,因为文件块之间的边界信息被保存在文件尾的元数据中,因此parquet文件是可分割且可并行处理的。
Header Block Block Block Block Footer 行组 每个文件负责一个行组
|
Row group Column chunck Column chunck 行组 由 列块构成,且一个列存储一列数据
|
Page Page Page 页 默认1MB 数据以页为单位存储
页是parquet文件的最小存储单元,要读取任意一行数据,就必须对这一行数据的页进行解压缩和解编码处理。对于单行查找来说,页越小,在找到目标值之前需要读取的值就也少,效率越高
parquet自带的编码方式:
差分编码、游程长度编码、字典编码
Parquet会根据列的类型自动选择合适的编码方式,对于嵌套数据来说,每一页还需要存储该页所包含的列定义深度和列元素重复次数。
parquet的文件块大小不能超过其HDFS块的大小
Parquet文件的读写:
(1) Parquet文件
MessageType schema = MessageTypeParser.parseMessageType(
"message Pair{\n" + "required binary left (UTF8); \n"+
"required binary right (UTF8); \n"+
"}");
(2) 构造Message
GroupFactory groupFactory = new SimpleGroupFactory(schema);
Group group = groupFactory.newGroup().append("left","L").append("right","R");
(3) 写入 WriteSupport
Configuration conf = new Configuration();
Path path = new Path("data.parquet");
GroupWriteSupport writeSupport = new GroupWriteSupport();
GroupWriteSupport.setSchema(schema,conf);
ParquetWriter writer = new ParquetWriter(path,writeSupport,
ParquetWriter.DEFAULT_COMPRESSION_CODEC_NAME,
ParquetWriter.DEFAULT_BOLOCK_SIZE,
ParquetWriter.DEFAULT_PAGE_SIZE,
ParquetWriter.DEFAULT_PAGE_SIZE,
ParquetWriter.DEFAULT_IS_DECTIONARY_ENABLED,
ParquetWriter.DEFAULT_IS_VALIDATING_ENABLED,
ParquetWriter.WriterVersion.PARQEUT_1_0,conf
)
writer.write(group);
writer.close();
(4) 读取 ReadSupport
GroupReadSupport readSupport = new GroupReadSupport();
ParquetReader reader = new ParquetReader(path,readSupport);
Group result = reader.read();
assertThat(result.getString("left",0),is("L"));
AvroParquetWriter、ProtoParquetWriter、ThriftParquetWriter
第14章 关于Flume
source --- channel --- sink
flume-ng agent \
--conf-file spool-to-logger.properties \ 属性配置
--name agent1
--conf $FLUME_HOME/conf \ 通用配置
-Dflume.root.logger=INFO,console
一旦事务中的所有事件全部传递到channel且提交成功,那么source就将该文件标注为完成
如果channel到sink无法记录,事务会回滚,而所有的事件仍保留在channel中
写文件的结束条件:
- 超过给定的打开时间
- 达到给定的文件大小
- 写满了给定数量的事件
分区存储方式:agent1.sinks.sink1.hdfs.path=xxx/year=%Y/month=%m/day=%d
一个Flume事件被写入到哪个分区是由事件的header中的timestamp决定的,默认情况下没有时间戳,它通过Flume的拦截器添加
为source1增加一个时间戳拦截器,将source产生的每个时间添加一个timestamp header
agent1.sources.source1.interceptors = interceptor1
agent1.sources.source1.interceptors.interceptor1.type = timestamp
扇出:从一个source向多个channel,多个sink传递事件
agent1.sources = source1
agent1.sinks = sink1a sink1b
agent1.channels = channel1a channel1b
agent1.sources.source1.channels = channel1a channel1b
agent1.sinks.sink1a.channel = channel1a
agent1.sinks.sink1b.channel = channel1b
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1a.type = hdfs
agent1.sinks.sink1a.hdfs.path = /tmp/flume
agent1.sinks.sink1a.hdfs.filePrefix = events-%{host}
agent1.sinks.sink1a.hdfs.fileSuffix = .log
agent1.sinks.sink1a.hdfs.fileType = DataStream
agent1.sinks.sink1b.type = logger
agent1.channels.channel1a.type = file
agent1.channels.channel1b.type = memory
复用选择器:某些事件发送到特定channel
Flume事件汇聚、Flume代理:p388
事务、交付保证:(1)多个类似的agent代理,防止agent挂掉 (2)多个类似的sink组
Sink组:多个sink当作一个sink处理,以实现故障转移和负载均衡
如果某个sink不可用,就尝试下一个sink,如果都不可用,事件也不会从channel中删除
processor.backoff参数:防止重复连接sink组中的故障sink
Flume掌握:source、channel、sink、interceptor
p396:source、channel、sink、interceptor基本类别
第15章 关于Sqoop
Apache Sqoop是一个开源工具,允许用户将数据从结构化存储器抽取到Hadoop中,用于进一步处理
Sqoop1 与 Sqoop2:
Sqoop2对Sqoop进行了重写,以解决Sqoop1架构上的局限性
- Sqoop1是命令行工具,不提供Java api,编写新的连接器需要做大量的工作
- Sqoop2具有以运行作业的服务器组件和一整套客户端,包括命令行接口、用户界面、REST API、Java api,Sqoop2的CLI与Sqoop1的CLI并不兼容
%sqoop
%sqoop help
%sqoop help import
Sqoop连接器:一个Sqoop连接器就是这个框架下的一个模块化组件,用于支持Sqoop的导入和导出操作。包括:mysql、postgresql、oracle、Sql Server、DB2、Netezza
导入数据:
sqoop import --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1
默认情况下,该作业会并行使用4个map任务来加速导入过程
生成代码:
sqoop codegen --connect jdbc:mysql://localhost/hadoopguide --table widgets --class-name Wight
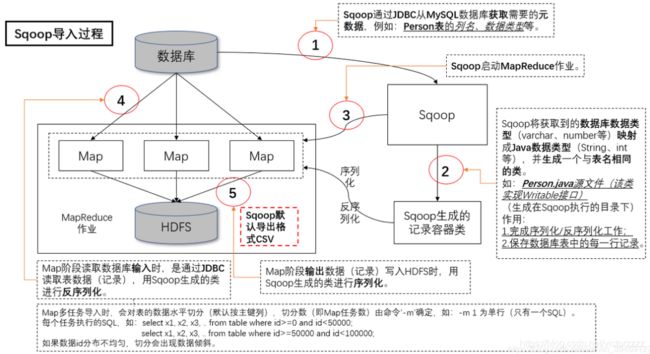
- Sqoop查询是根据划分列:--split
- Sqoop导入控制:--where --query
- 定时运行导入:只有当特定列(--check-column)的值大于指定值(--last-value)时,Sqoop才会导入数据
- 直接模式导入:--direct (比基于JDBC的导入更加高效)
Sqoop导入到Hive
Sqoop根据关系源数据中的表来生成一个Hive表
sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide \
--table wights --fields-terminated-by ',' -m 1 --hive-import
Sqoop保存大对象
大对象通常保存在CLOB或BLOB类型的列中,一般大对象和他们的行分开存储,在访问大对象时,需要通过行中包含的引用来打开它
Sqoop导出
sqoop export --connect jdbc:mysql://localhost/hadoopguide -m 1 \
--table sales_by_zip --export-dir /usr/hive/warehouse/zip_profits \
--input-fileds-terminated-by '\0001'
Sqoop导出过程:

Sqoop将数据导出到一个临时阶段表中,然后在导出任务完成前,在一个事务中将临时阶段表中的数据全部转移到目标表中
第17章 关于Hive
Hive执行引擎:mapreduce、tez、spark
在使用mapreduce时,中间作业的输出会被“物化”存储在hdfs上,tez和spark则不同,会根据Hive规划器的请求,把中间结果写到本地磁盘上,甚至在内村中缓存,以避免额外的复制开销
写时模式:传统数据库在写入时检查,写时模式有利于提高查询性能
读时模式:Hive在读数据时检查,不需要解析,数据的加载仅仅是文件复制或移动
Hdfs不提供就地文件更新,因此插入、更新和删除操作引起的一切变化都会保存在一个较小的增量文件中,由metastore在后台运行的mapreduce作业会定期将这些增量合并到“基表”文件中
事务:Hive在0.13.0引入事务
锁:Hive在0.7.0版本引入了表级和分区级的锁,锁由zookeeper透明管理
Hive索引:紧凑索引、位图索引。紧凑索引存储每个值的hdfs块号,位图索引使用压缩的位集合来高效存储具有某个特殊值的行
其他SQL-on-Hadoop:Impala、Presto、Spark SQL、Phoenix(SQL on HBase)
Hive的数据类型:boolean、tinyint、samllint、int、bigint、float、double、decimal、string、varchar、char、binary、timestamp、date、array、map、struct、union
- TINYINT:1字节有符号整数,-128 - 127,对应java byte
- SMALLINT:2字节有符号整数,-32768 - 32767,对应java short
- INT:4字节有符号整数,-2147483648 - 2147483647,对应java int
- BIGINT:8字节有符号整数,对应java long
- FLOAT:4字节单精度浮点数
- DOUBLE:8字节双精度浮点数
- DECIMAL:任意精度有符号小数
- STRING:无上限可变长度字符串
- VARCHAR:可变长度字符串
- CHAR:固定长度字符串
- ARRAY:例:array(1,2)
- Map:例:map('a',1,'b',2)
- STRUCT:struct(‘a’,1,1.0)
- UNION:create_union(1,'a',63)
Hive隐式类型转换:任何数值类型都可以隐式转换为一个范围更广的类型或者文本类型(STRING VARCHAR CHAR)
Hive强制类型转换: cast('xxx' as int) 转换失败会返回null
查看分区:show partitions xxx
存储格式:
- 默认的行内分隔符不是制表符,而是ASCII控制码集合中的Control-A
- 集合类元素的默认分隔符为字符Control-B
导入数据:CATS:create table ...... as select
多表插入:
from source
insert overwrite table xxx select col1,col2
insert overwirte table yyy select col3
sort by < order by < distribute by < cluster by
- sort by : 为每个reducer排序
- order by :全排序
- distribute by :分配同一个reducer之中
视图:视图是只读的,无法通过视图为基表加载或插入数据
- UDF:一个输入行,一个输出行
- UDAF:多个输入行,一个输出行
- UDTF:一个输入行,多个输出行
第19章 关于Spark
DAG引擎:Spark作业是由任意的多阶段有向无环图(DAG)构成
job -----> 多个stage ----->运行在RDD分区上
RDD:弹性分布式数据集,在集群中跨多个机器分区存储的一个只读的对象集合
加载或执行转换并不会立即触发任何数据处理的操作,只不过创建了一个计算的计划,只有当RDD执行某个动作时,才会触发真正的计算
RDD的创建:
- 来自内存中的对象集合: sc.parallelize(1 to 10,10)
- 使用外部存储器中的数据集(如HDFS): RDD[String] = sc.textFile(inputPath)
- 对现有RDD进行转换
RDD的转换:(1)转换 (2)动作
如果返回类型是一个RDD,则为转换,否则为动作
- reduceByKey() 不需要初始值
val pairs:RDD[(String,Int)] = sc.parallelize(Array(("a",3)))
val sums:RDD[(String,Int)] = pairs.reduceByKey(_+_)
- foldByKey()需要初始值
val sums:RDD[(String,Int)] = pairs.foldByKey(0)(_+_)
- aggregateByKey
val sets:RDD[(String,HashSet[Int])] = pairs.aggregateByKey(new HashSet[Int])(_+=_,_++=_)
第一个函数负责把Int合并到HashSet[Int]中
第二个函数负责合并两个HashSet[Int]中的值
例如:Array((“a”,3),(“a”,1),(“b”,7),("a",5))
结果为:((“a”,Set(1,3,5)),("b",7))
持久化:cache()并不会立即缓存RDD,它用一个标志来对RDD进行标记,以指示RDD应当在Spark作业运行时被缓存
持久化级别:MEMORY_ONLY MEMEORY_ONLY_SER
序列化:
Kryo序列化: conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
广播变量:
在经过序列化后发送给各个executor,然后缓存在那里,以便后期任务可以在需要时访问它
val lookup:Broadcast[Map[Int,String]] = sc.broadcast(Map(1 ->"a",2->"e",3->"i",4->"o"))
val result = sc.parallelize(Array(2,1,3)).map(lookup.value(_))
累加器:只做加法的累加器,类似于MapReduce中的计数器
val count:Accumulator[Int] = sc.accumulator(0)
val result = sc.parallelize(Array(1,2,3)).map(i => {count +=1; i}}) .reduce((x,y) => x+y)
Spark program
|
SparkContext
|
DAGScheduler
|
TaskScheduler
|
SchedulerBackend----------->ExecutorBackend
|
dirver Executor
|
ShuffleMapTask
executor
dirver:负责托管应用并作为作业调度任务
executor:专属应用
两种类型的任务:shuffle map任务 、 result任务
- shuffle map任务运行在除最终阶段之外的其他所有阶段中,返回一些可以让下一阶段检索其分区的信息
- result任务运行在最终阶段,每个result任务在它自己的RDD分区上计算,并把结果发送给driver,driver进行汇总
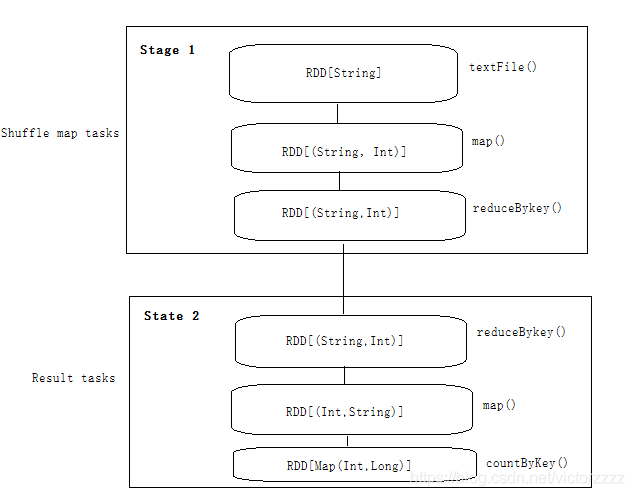
执行管理模式:
- 本地模式:有一个executor和dirver运行在同一个JVM中
local 、local[n]、local(*) (机器的每一个内核一个线程)
- 独立模式
- Mesos模式
- Yarn模式:yarn-client 、 yarn-cluster
yarn是唯一一个能够与Hadoop的Kerberos集成的管理器
yarn-client 客户端模式的driver在客户端运行
yarn-cluster 集群模式的driver在yarn的application master上运行
第20章 关于HBase
面向列的分布式数据库,可以实时随机访问超大规模数据集
基本概念:
- 行
- 行键
- 列族 每个列都具有相同的前缀 列族:修饰符
一个表的列族要提前给出,列可以在更新中提供。只要列族存在,列可以随时加进去
Master ---------------------------> ZooKeeper Cluster 【hbase:meta 目标主控机等信息】
|
Regionserver
|
HDFS
hbase:meta
特殊目录表,维护着当前集群上所有区域的列表、状态和位置
hbase:meta表中的项使用区域名作为键(有序),区域名由所属的表名、区域的起始行、区域的创建时间以及MD5哈希值组成
例如:TestTable,xyz,12379989859898.1sds123ffdf
区域变化:分裂、禁用、启用等操作,目录表会进行相应的更新
客户端通过hbase:meta查找到所有节点及其位置,然后直接连接regionserver进行交互
客户端会对hbase:meta的内容进行缓存,一旦发生错误,再去查看hbase:meta获取新位置
- “重做”日志内容
- 文件压缩
- 文件分割
hbase shell
create 'test','data'
list
scan 'test'
put 'test','row1','data:1','value1'
get 'test','row1'
disable 'test'
drop 'test'表的离线:disable
表的在线:enableHBase特性:
- 没有真正的索引
- 自动分区
- 线性扩展和新节点的自动管理
- 普通商用硬件支持
- 容错
- 批处理
HBase使用HDFS的方式 与 Mapreduce使用HDFS方式 区别:
- Mapreduce首先打开HDFS文件,然后map任务流失处理文件内容,最后关闭文件
- HBase中,数据文件在启动时就被打开,并在处理过程中始终保持打开的状态
第21章 关于ZooKeeper
ZooKeeper是Hadoop分布式协调服务,不能避免分布式出现部分失败
ZooKeeper具有以下特点:
- 简单、精简
- 可以实现多种协调数据结构和协议:分布式队列、分布式锁、领导者选举
- 避免系统出现单点故障,构建可靠应用程序
- 松耦合交互方式
- 提供了通用协调模式实现方法的开源共享库
znode:既可以保存数据的容器,也可以保存其他znode容器
创建znode的参数:路径、znode内容、控制列表、znode类型
//ZooKeeper创建组
public class CreateGroup imploements Wather{
private static final int SESSION_TIMEOUT = 5000;
private ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws Exception{
zk = new ZooKeeper(hosts,SESSION_TEIMOUT,this);
//主机地址、会话超时参数、Watcher实例
connectedSignal.await();
}
@Override
public void process(WatchedEvent event){
if(event.getState()== KeeperState.SyncConnected){
connectedSignal.countDown();
}
}
public void create(String groupName) throws Exception{
String path = "/" + groupName;
String createdPath = zk.create(path,null,Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
public void close() throws Exception{
zk.close();
}
}Znode类型:
- 短暂的:短暂znode会被zk服务删除,依赖客户端会话
- 持久的:不依赖会话
列出列表:zkCli.sh -server locahost ls /zoo
删除组:
节点路径、版本号
如果提供的版本号一致,ZooKeeper会删除这个znode
如果版本号设置成-1,可以绕过版本检测机制,不管znode版本号都会删除
zk的目的:
ZooKeeper用来协调服务,不是用来大容量数据存储,因此一个znode能存储的数据限制在1MB以内。且zk访问具有原子性,zk允许客户端读到的数据滞后于zookeeper服务的最新状态
zk顺序号:
如果创建znode时设置了顺序标志,在创建znode会附加一个值,这个值由一个单调递增的计数器添加
在一个分布式系统中,顺序号可以被哦用于为所有的事件进行全局排序,这样客户端就可以通过顺序号来推断事件的顺序
观察、触发事件
exsits、getData、getChildren
基本操作
create、delete、exists、getACL、setACL、getChildren、getData、setData、sync
quota:用来设置某个节点的子字节数和本身的数据长度:setquota /xx -n number -b byte
ACL列表:
ACL依赖于ZooKeeper的客户端身份验证机制
- digest 通过用户名和密码识别客户端
- sasl 通过Kerberos来识别客户端
- ip 通过客户端的ip地址来识别客户端
ZooKeeper运行方式:
- 独立模式:只有一个ZooKeeper服务器
- 复制模式:ZooKeeper通过复制模式来实现高可用性,只要集群中半数以上的机器处于可用状态,就能够提供服务。确保对znode树上的每一个修改都会被复制到集群中超过半数的机器上
ZooKeeper使用了Zab协议(非Paxos,依靠TCP保证消息顺序)
- 领导者选举:一旦半数的跟随者已经将其状态与领导者同步,则表明这个阶段已完成
- 原子广播:所有的写请求都会转发给领导者,再由领导者将更新广播给跟随者,当半数跟随者已经将修改持久化后,领导者才会提交这个更新,客户端才会收到更新成功的响应
如果领导者出现故障,其余的机器会选出另外一个领导者,并和新的领导者一起继续提供服务。如果之前的领导者恢复正常,则会成为更随者
领导者负责提供写请求、跟随者负责响应读请求
一致性:
- 顺序一致性:对znode的更新都赋予了全局ID。会按照发送顺序被提交
- 原子性
- 单一系统映象:一个客户端无论连接那一台服务器,都将看到同样的系统视图
- 持久性
- 及时性:任何客户端所看到的滞后系统视图都是有限的,在读数据之前调用sync
Zookeeper“滴答”:
tick time:会好超时参数的值不可以小于2个滴答其不可以大于20个滴答
一般zk的服务器越多,会话超时的设置应该越大;连接超时、读超时、ping设置越小
Zookeeper状态转移:
Connecting --- > Connected ---> Closed
Zookeeper两种异常:
- InterruptedException:interrupt 连接异常
- KeeperException:通信问题
分布式锁:可用于大型分布式系统中实现领导者选举
分布式锁能够在一组进程之间提供互斥机制,使得任何时刻只有一个进程可以持有锁
实现原理:
指定一个锁的znode
希望获得锁的客户端创建一些短暂顺序的znode作为znode的子节点,为竞争者进行强制排序
在任何时间点,顺序号最小的客户端将持有锁
例如:/leader节点下,/leader/lock-1 和 /leader/lock-2 lock-1会持有锁
释放锁:
删除节点即可
分布式锁造成的问题:
- 羊群效应:每次锁释放或一个新进程开始申请锁的时候,观察者会被触发通知每一个客户端, 而只有一个客户端获得锁,这个过程会产生峰值流量,对zk造成压力
解决方法:当前子节点消失时通知下一个客户端
2. 可恢复异常:连接丢失导致操作失败,重新连接会造成删不掉的孤儿znode,导致死锁
解决方法:znode名称嵌入一个ID,如果客户端出现连接丢失,重新连接后可以对锁节点的所有子节点进行检查,查看是否包含ID,如果有,则知道自己创建成功,不需要再创建
zookeeper观察节点:
没有投票权的跟随者,在不影响写性能的情况下提高读性能
myid:每个服务器的id
Zookeeper配置:
tickTime = 2000
dataDir=/disk1/zookeeper
dataLogDir=/disk2/zookeeper clientPort=2181 //客户端端口
initLimit=5//跟随者与领导者同步的时间范围,半数以上的跟随者需未完成,领导者将弃位,重新领导者选举
syncLimit=2 //允许跟随者与领导者同步的时间,未完成,跟随者会重启
server.1=zookeeper1:2888:3888 //2888:跟随者端口
server.2=zookeeper1:2888:3888 //3888:领导者选举阶段与其他服务器连接端口
server.3=zookeeper1:2888:3888