上一篇随笔中,采用三层神经网络,ReLu作为激活函数,经过反向传播训练,可以得到对训练数据集100%的正确率。
对于测试数据集上的正确率,由于实际特征并不仅限于像素点,所以没有足够高。
以下为涂鸦的两个数字,虽然都代表2,但是像素点上没有相同之处,在多层神经网络中很容易被识别成不一样的数字。

人眼中有特化的分辨边缘的细胞,对于边缘信息不断整合抽象,和实体对应起来,是单独的多层神经网络无法反映的。
假设将上述图像切分并对每一个区域作线性拟合,应该可以得到一部分关于图像的拓扑特征,但是运算量会很大。
考虑一个简单的模型,对于2*2的像素,根据值的大小给予不同的标签如下。
def get_w(x): [a,b]=x[0] [c,d]=x[1] if [a,b] == [0, 0] or [c,d] == [0, 0]: return 0.0 else: i=np.argmax(x[0]) j=np.argmax(x[1]) if i==j: return 1.0 elif i==0: return -0.5 else: return 0.5
这样对每个28*28的Mnist数据得到14*14个值仅有4种[-0.5,0.0,0.5,1.0]的数据集。
使用上一篇随笔中的训练程序,得到的结果为:
# Epoch 29: cost=0.0247597808294 4992 / 5000, 4274 / 5000
这并非一个很好的结果,丢失了大量的信息。
采用2*2的max pooling,得到14*14个浮点值[0,1],进行训练,结果为:
# Epoch 29: cost=0.0221379559115 4990 / 5000, 4612 / 5000
这个结果已经接近于28*28的原始数据集。
可见pooling可以很大程度上保留原有信息同时降低维度。
采用2*2的max pooling,重复采样,得到26*26个浮点值[0,1],进行训练,结果为:
""" Epoch 0: cost=0.027313900312 4650 / 5000, 4412 / 5000 Epoch 1: cost=0.0248415257007 4745 / 5000, 4474 / 5000 Epoch 2: cost=0.0210559585677 4788 / 5000, 4537 / 5000 Epoch 3: cost=0.0201228636377 4836 / 5000, 4563 / 5000 Epoch 4: cost=0.0188826206618 4892 / 5000, 4617 / 5000 Epoch 5: cost=0.0179911081808 4917 / 5000, 4650 / 5000 Epoch 6: cost=0.0176826236831 4943 / 5000, 4616 / 5000 Epoch 7: cost=0.0173516027109 4948 / 5000, 4670 / 5000 Epoch 8: cost=0.0170706176725 4965 / 5000, 4654 / 5000 Epoch 9: cost=0.0168723415579 4978 / 5000, 4684 / 5000 Epoch 10: cost=0.016740534601 4971 / 5000, 4667 / 5000 Epoch 11: cost=0.0166837855862 4977 / 5000, 4660 / 5000 Epoch 12: cost=0.0167253545793 4990 / 5000, 4664 / 5000 Epoch 13: cost=0.0166943462499 4979 / 5000, 4679 / 5000 Epoch 14: cost=0.0166982658442 4996 / 5000, 4659 / 5000 Epoch 15: cost=0.0167105714557 4992 / 5000, 4679 / 5000 Epoch 16: cost=0.0168017408941 4998 / 5000, 4654 / 5000 Epoch 17: cost=0.0168100947082 4995 / 5000, 4678 / 5000 Epoch 18: cost=0.0168606467537 4995 / 5000, 4670 / 5000 Epoch 19: cost=0.0169498747134 4998 / 5000, 4673 / 5000 Epoch 20: cost=0.0169915629043 4998 / 5000, 4681 / 5000 Epoch 21: cost=0.0170220832226 4999 / 5000, 4683 / 5000 Epoch 22: cost=0.0170598381918 5000 / 5000, 4689 / 5000 Epoch 23: cost=0.0171515118627 5000 / 5000, 4674 / 5000 Epoch 24: cost=0.0171548404686 4998 / 5000, 4667 / 5000 Epoch 25: cost=0.0172283215375 4998 / 5000, 4684 / 5000 Epoch 26: cost=0.017253480939 4998 / 5000, 4677 / 5000 Epoch 27: cost=0.0172660665625 4999 / 5000, 4673 / 5000 Epoch 28: cost=0.017284218248 4999 / 5000, 4692 / 5000 Epoch 29: cost=0.0173150132253 5000 / 5000, 4681 / 5000 """
测试数据集上比28*28原始Mnist数据更好。
采用一个5*5的卷积核,得到24*24的数据进行训练,结果为:
w=np.random.normal(loc=0, scale=np.sqrt(1.0/4), size=[5,5])
# Epoch 29: cost=0.0149520051459 5000 / 5000, 4591 / 5000
结果比单独pooling和原始数据略差,但是卷积核只用了一个而且没有训练到。
当前普遍使用的(多个卷积核)卷积+池化+多层神经网络,已被证明是最佳选择之一。
<img src="https://pic1.zhimg.com/2fb3939305e69c707a6cb9a644bdcb6c_b.jpg" data-rawwidth="173" data-rawheight="46" class="content_image" width="173">
卷积的重要的物理意义是:一个函数(如:单位响应)在另一个函数(如:输入信号)上的加权叠加。


首先我们定义感受野我们谈视觉信息是怎么激活神经元的,一个不可忽视的定义方式就是“感受野”(Receptive Field, RF),我们认为在很多视觉的神经元内,这个神经元只接受整个视野里某一个部分的信息进行处理。这是一个比较重要的基本概念。
再来简介大脑主要的视觉通路
那么首先就需要我来给答主介绍一下大脑的主要的视觉通路都是由什么构成的。
视觉的信息被眼球捕捉到,首先到光感受器上,然后经过视网膜内简单的神经环路的初步加工,到RGC(视网膜神经节细胞)产生动作电位向大脑传递信息。RGC的信息传递到丘脑的外膝体(LGN),换元后进入初级视觉皮层(V1),V1进一步加工视觉信息,然后传递到MT,V2,V3等区域,此后视觉信息兵分两路,主要分为视觉的背侧通路(Dorsal Pathway)与腹侧通路(Ventral Pathway),腹侧主要编码这个物体是什么,而背侧主要编码这个物体在哪里?怎么运动?以及我们如何理解这个物体并且如何去操纵它(Fang & He 2005, Fischer et al 2016)。腹侧主要还有V4,IT等区域,背侧还包含LIP,AIP等区域,具体可以看下面这个猴子主要视觉同路的图片
<img src="https://pic3.zhimg.com/8a68fa67a712da98f951399a3fe24336_b.png" data-rawwidth="415" data-rawheight="244" class="content_image" width="415">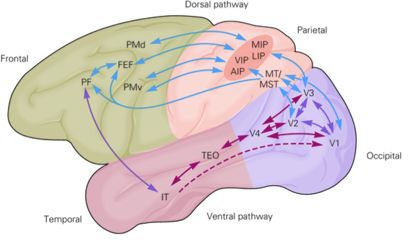
下面我就几个主要的脑区神经元的激活性质进行一些介绍。
首先是视网膜神经节细胞(RGC是视网膜唯一能够产生动作电位的细胞),它具有一个非常简单的环形感受野,像下面这幅图这样。
<img src="https://pic4.zhimg.com/2b85e533e0b3555264698cee1d53d22f_b.png" data-rawwidth="600" data-rawheight="510" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/2b85e533e0b3555264698cee1d53d22f_r.png">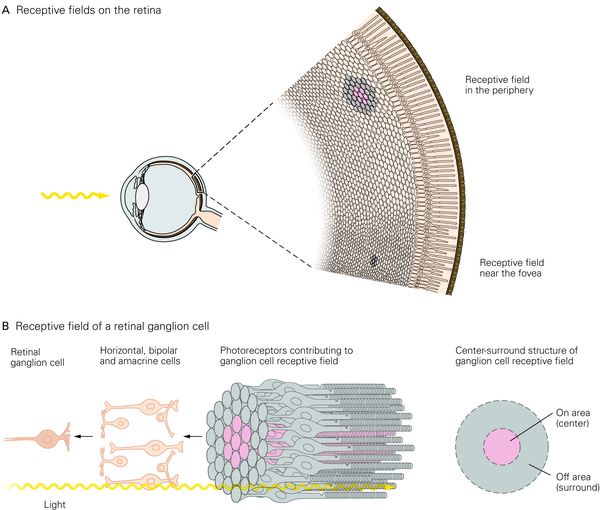
如果在视野的某个特定位置(这个细胞的感受野上),出现了一束像这样中间亮而边缘暗的光(也有的细胞是相反的,倾向于周边亮中间暗的刺激),这个细胞就会强烈的发放动作电位。
再介绍初级视觉皮层(V1)区域,这里的细胞主要对视野内某个区域某一个朝向的边缘信息敏感(Orientation Selectivity) (Hubel & Wiesel 1968)。此外V1的一部分细胞也会编码这个边缘的运动方向信息。下面这个图可以很好的说明这个特点。
<img src="https://pic4.zhimg.com/c11be6b94aa88a44ce70cb9953b7970f_b.png" data-rawwidth="829" data-rawheight="800" class="origin_image zh-lightbox-thumb" width="829" data-original="https://pic4.zhimg.com/c11be6b94aa88a44ce70cb9953b7970f_r.png">
对V1皮层方向选择性的研究结果使得Hubel与Wiesel获得了1981年的诺贝尔奖。这个结果也极大的启发计算机视觉的研究。
对于视觉的腹侧通路,传统的观念认为信息自下而上流动的过程(Bottom Up)是一个不断整合信息,吧微小的边缘拼凑拼凑,拼成角,逐渐抽象编码直至一个完整物体的过程。如下面这个图(Herzog et al 2015)。
<img src="https://pic3.zhimg.com/8fc614fdf9fa6796d853bbcc04dccbb6_b.png" data-rawwidth="415" data-rawheight="306" class="content_image" width="415">
对于V2
但是实际上我们对他的性质理解的还不太够。比如我们最近的研究认为,第二视觉皮层(V2)实际上在加工V1皮层处理过的这些边缘信息的高层次的一些相关关系(Higher Order Correlation),更类似于处理一个物体的材质信息(Freeman et al 2013)。
<img src="https://pic3.zhimg.com/0f5c4a59b28faa6f2452ba02a2758686_b.png" data-rawwidth="394" data-rawheight="171" class="content_image" width="394">
虽然对于比较简单的刺激(简单边缘这种),V2的激活性质和V1相似,但是对于复杂的材质类型的编码机制我们还没有弄清楚。需要更进一步的深入研究。
对于V4这个区域来说
我们现在认为V4的编码整合视野内物体的边缘,从而通过V4群体编码可以反映这个物体的完整的边缘信息、形状(Pasupathy & Connor 2002)
<img src="https://pic4.zhimg.com/8d8af6d699af1b285bca0203c954138b_b.png" data-rawwidth="415" data-rawheight="442" class="content_image" width="415">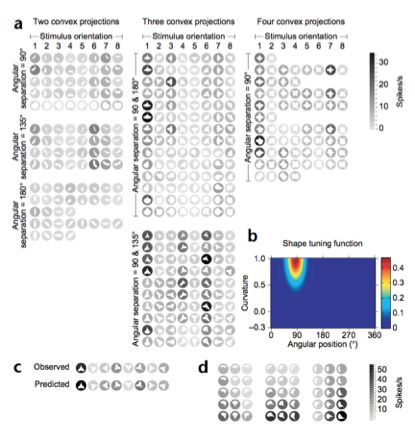
例如上面这个图,这个图上画的就是给猴子呈现的这个类似“雨滴”的各种形状,颜色越黑代表神经元的发放程度越剧烈,从而研究者们就发现,这个V4的神经元在编码这个物体上方(以极坐标表示,90度的方位上)这个地方的曲率信息。
<img src="https://pic3.zhimg.com/b0efe3c0b047ffdbdc2a7281d6862cae_b.png" data-rawwidth="629" data-rawheight="1000" class="origin_image zh-lightbox-thumb" width="629" data-original="https://pic3.zhimg.com/b0efe3c0b047ffdbdc2a7281d6862cae_r.png">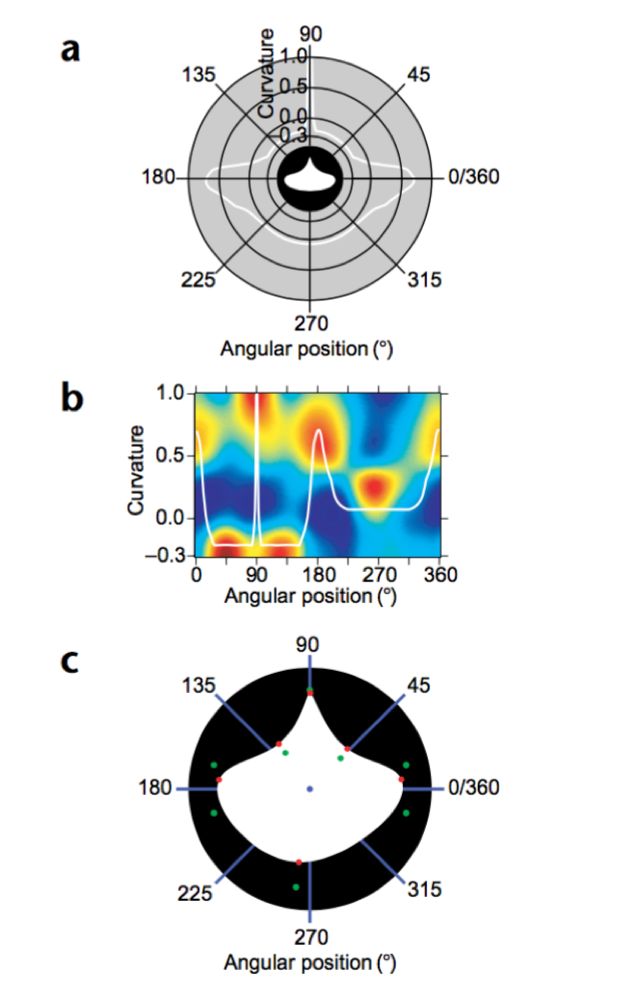
通过一群V4神经元的群体编码,我们可以吧这个刺激的形状再“重建”出来,也就是说V4通过这种方式对物体的形状信息进行了群体编码。但是对于V4对于复杂刺激的真正的编码方式我们还没有了解清楚,需要科学家们进一步的研究。(Pasupathy & Connor 2002)
好了信息进一步流动到IT皮层。
在IT皮层,视觉信息是对我们看到的一个特定的“物体”激活。但是更具体来讲,对于这个物体也并不是非常选择性的激活(比如祖母细胞这种,是不存在的),而是以一个细胞集群的方式进行编码的。甚至我们还发现了专门编码人脸的FFA与编码场景信息的PPA(Kanwisher et al 1997)。
<img src="https://pic1.zhimg.com/7915856c1ac753cd80856afcfbbbd690_b.png" data-rawwidth="850" data-rawheight="362" class="origin_image zh-lightbox-thumb" width="850" data-original="https://pic1.zhimg.com/7915856c1ac753cd80856afcfbbbd690_r.png"><img src="https://pic3.zhimg.com/2ebc595a3594eea91c9a0f52ff44f4de_b.png" data-rawwidth="600" data-rawheight="1300" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic3.zhimg.com/2ebc595a3594eea91c9a0f52ff44f4de_r.png">

下面再来介绍视觉的背侧通路对什么刺激激活。
首先来谈谈MT区
这个区域选择性的对运动的方向激活。属于加工运动信息的脑区。对于简单的刺激而言,它可以对视野内某个位置的某一个运动方向激活。
<img src="https://pic3.zhimg.com/287585a43c44907350f4e95245a7117a_b.png" data-rawwidth="829" data-rawheight="531" class="origin_image zh-lightbox-thumb" width="829" data-original="https://pic3.zhimg.com/287585a43c44907350f4e95245a7117a_r.png">而对于一个复杂的物体而言,整体的运动方向和局部的运动方向是不一样的,MT也会编码整体的运动方向,而且MT可以通过编码远近不同的视觉运动信息,从而加工出立体的、更复杂的运动信息。对于具体MT如何编码运动我们还没有完全搞清楚(Born & Bradley 2005, Cui et al 2013, Smith et al 2005)。
接着在VIP区,神经元对物理触摸与视觉的刺激都会响应(Duhamel, Colby, and Goldberg 1998)他们不光接受来自视觉背侧通路相关皮层(MT)的信号,还接受某些躯体感受皮层的信号(SI)。但是这种表征仍然是对头部的相对位置。沿通路向上,当神经发放从VIP区域传递到F4区域后,对刺激的感受野被转换成相对于身体的特定部位
在AIP区,神经元将特定的物理属性与特定的运动行为关联。AIP的某些神经元也可以对猴子看到的某些特定形状的物体激活,被认为可能与动物的抓握本能有关(Murata et al. 2000).除此之外,人们让猴子在明亮或者昏暗的环境下抓握物体,实验显示,这些神经元可以被分为三组:视觉主导/运动主导、视觉-运动(visuo-motor)神经元。(Murata et al. 2000.)这三种神经元用视觉输入,编码特定物体的视觉可见性,并把他们与特定的运动行为联系起来。
来到运动皮层,我们还发现前运动皮层的F5区,还有某些神经元,不光在猴子自己运动的时候会激活,在猴子看到人或者其他猴子做相似运动的时候也会选择性的激活。
<img src="https://pic3.zhimg.com/0e35cf3c328fc2f0ff2dded5671cc37e_b.png" data-rawwidth="863" data-rawheight="633" class="origin_image zh-lightbox-thumb" width="863" data-original="https://pic3.zhimg.com/0e35cf3c328fc2f0ff2dded5671cc37e_r.png">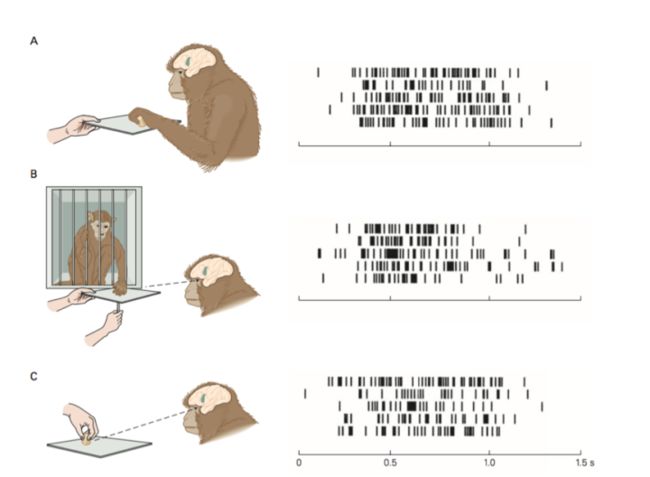
我们把这些神经元称作是镜像神经元。(Rizzolatti et al. 1996.)
总而言之
视觉刺激与某些神经元的活跃是有非常强的对应关系的。随着不同皮层区域、不同神经元处理的信息不同,编码的方式不同,它们的“对应关系”也差别比较大,从简单的视野内边缘朝向,到材质、边缘轮廓,直至一个复杂的运动、特定的物体,甚至是面孔。大脑中这些神经元如何编码信息,如何加工这些信息我们知道的这些只是冰山一角,还有更多需要我们去发现,去探索。


