最近浏览了一下阿里巴巴的Java开发手册,感觉内容确实非常的赞,发现了不少自己在编程中的误区,因此决定通过成文牢固掌握,文中将选取个人认为比较重要的部分进行描述与分析。”愿站在巨人的肩膀上,码出高效,码出质量“。
概述
手册中内容很多,包括编码规约、工程结构、MySQL数据库、异常日志、安全规约、单元测试等6大部分。其中工程结构部分在整体上对项目进行了把控,编码规约和MySQL设计规约中有非常多的“最佳实践”,个人认为是最为有价值的部分。次重点安全规约很符合互联网场景的需要,异常日志和单元测试部分相对来说内容和价值相对小一点。
下图是个人对手册的简单汇总(将图片拖到浏览器新开页面,之后放大可以清晰很多),其中红星表示重点,黄色表示次重点。此外,其中的集合处理、并发处理、MySQL规约和工程结构有一定理解难度,会专门放到重难点增强一节进行详细分析。当然这只是个人的浅见,完整部分请见最下方的参考资料,目前阿里公司已推出这套规约的IDE插件,大家可以试试。
重难点增强
工程结构

Open Interface:提供RPC或Restful风格的接口,并通过框架进行网关安全控制、流量控制等。
终端显示层:前端模板渲染并执行显示的层。
Web Layer: 主要是对访问控制进行转发, 各类基本参数校验, 或者不复用的业务简单处理等。
Service Layer:业务逻辑服务层。
Manager Layer:这一层比较有意思,既包含了常见的外部接口的Agent功能,也包含了对DAO接口的简单封装用于复用,还可以在改成构建对于DAO的缓存。
DAO Layer:与底层 MySQL、Hbase等进行数据交互,通常基于各类DAL框架。
ExternalInterface: 包括其它部门 RPC 开放接口, 基础平台, 其它公司的 HTTP 接口。
Tip: 实际项目中完全可以遵循该模式构建包的层次。
集合处理
集合操作一直是一个关键点,常见的小技巧包括通过Set元素唯一的特性,可以快速对一个集合进行去重操作,JD8中通过steam流对集合操作做了不错的增强。合理利用好集合的有序性 (sort) 和稳定性 (order) ,避免集合的无序性 (unsort) 和
不稳定性 (unorder) 带来的负面影响,ArrayList是order&unsort;HashMap是unorder&unsort;TreeSet 是order&sort。
TIp: 不同类型Map集合K/V能不能存储null值的情况如下表所示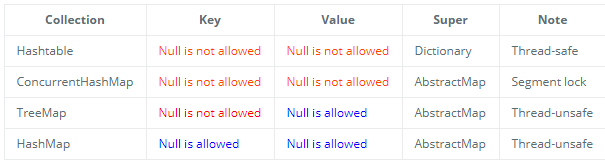
并发处理
合理的通过并发控制来高效利用系统资源是工程师永远的追求,该手册的不少要求很好的认识到自己在该方面的不足。
线程池的创建
过去一半都通过Executors 去创建线程池,实际上这是不合理的,比如FixedThreadPool的阻塞队列大小Integer.MAX_VALUE,很容易造成大量请求的堆积,造成OOM。而ScheduledThreadPool允许线程的数量为Integer.MAX_VALUE,更加容易出现OOM。因此必须使用ThreadPoolExecutor创建线程池,明确的制定线程池的参数,详情请见深入理解Java线程池一文。
使用锁的原则
1.高并发时,同步调用应该去考量锁的性能损耗。能用无锁数据结构,就不要用锁 ; 能锁区块,就不要锁整个方法体 ; 能用对象锁,就不要用类锁。
2.对多个资源、数据库表、对象同时加锁时,需要保持一致的加锁顺序,否则可能会造成死锁。
3.并发修改同一记录时,避免更新丢失,需要加锁。要么在应用层加锁,要么在缓存加锁,要么在数据库层使用乐观锁,使用 version 作为更新依据。如果每次访问冲突概率小于 20%,推荐使用乐观锁,否则使用悲观锁。乐观锁的重试次数不得小于 3 次。
CountDownLatch
使用 CountDownLatch 进行异步转同步操作,每个线程退出前必须调用 countDown方法,线程执行代码注意 catch 异常,确保 countDown 方法被执行到,避免主线程无法执行至 await 方法,直到超时才返回结果。需要注意子线程抛出异常堆栈,不能在主线程的try-catch块中捕获到。
ThreadLocalRandom
避免 Random 实例被多线程使用,虽然共享该实例是线程安全的,但会因竞争同一seed 导致的性能下降,推荐使用ThreadLocalRandom。
Volatile
volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。在完成饱汉的单例模式时,可以使用Volatile关键字实现延迟初始化。
LongAdder
对于count++操作,可以使用AtomicInteger count = new AtomicInteger();,JDK8中推荐使用LongAdder,通过减少乐观锁的重试次数提高性能。
HashMap
HashMap 在容量不够进行 resize 时由于高并发可能出现死链,导致 CPU 飙升,在开发过程中可以使用其它数据结构或加锁来规避此风险。
ThreadLocal
ThreadLocal 对象建议使用 static修饰。这个变量是针对一个线程内所有操作共享的。
MYSQL规约
数据库方面的优化一直困扰着我,书上的一下几个原则给予个人在数据库优化方面不少启示。
索引长度
过去一直没有注意过索引还有长度这个概念,现在才知道在varchar等类型字段上建立索引时,可以指定索引长度,达到一定区分度即可,一般对于字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用count(distinct left( 列名, 索引长度 )) / count( * )的区分度来确定。
此外页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
order by
在有order by的场景,请注意利用索引的有序性。例如where a =? and b =? order by c的索引为a _ b _ c
覆盖索引
利用覆盖索引可以减少原表查询,通过索引页(目录)即可查到所需信息。通常来说,能够建立索引的种类包括主键索引、唯一索引、普通索引,而覆盖索引是查询的一种效果,可以通过explain查看到extra 列会出现using index 。
分页查询
MySQL并不是跳过offset行,而是取 offset + N 行,之后放弃offset行,返回所需N行,当数据量大时,推荐如下方式进行优化。先快速定位需要获取的 id 段,然后再关联:SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
SQL 性能优化的目标
至少要达到 range 级别, 要求是 ref 级别, 如果可以是 consts最好。
consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
ref 指的是使用普通的索引 (normal index) 。
range 对索引进行范围检索。
tip: type = index,索引物理文件全扫描,速度非常慢,这个 index 级别比较 range 还低,与全表扫描是小巫见大巫。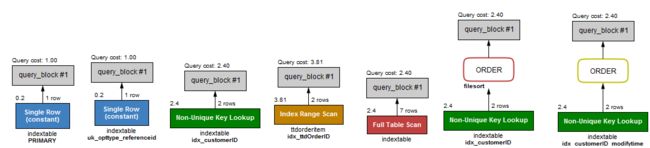
在Mysql Workbench中表述稍微有些区别:consts没变,Non-Unique Key Lookup表示ref, Index Range Scan表示range, full table Scan表示All, full index scan表示index,当然也可以选择Tabular视图替代Visual视图。
组合索引
区分度最高的在最左边,对于where a =? and b =?来说,a 列的值越唯一越好。此外,存在非等号和等号混合判断条件时, 在建索引时, 请把等号条件的列前置。
隐式转换
防止因字段类型不同造成的隐式转换,导致索引失效,当数据查询超时,也需要把此作为很重要的考虑部分。
参考资料
阿里巴巴Java开发手册
阿里规约github