预训练模型(5)---- SpanBERT&RoBERTa&ERNIE2
比较小众的预训练模型
- 1. SpanBERT
- 2. RoBERTa
- 3. ERNIE2
本文主要介绍一些比较小众的预训练模型,这些模型不像Bert、XLNet等那么有影响力,都是在这些模型的基础上做的相关改进工作,但是这些工作可以引导我们学会如何优化模型,对我们的学习以及科研都会有很大的帮助。
首先是Facebook的提出的两个预训练模型——SpanBERT和RoBERTa。
1. SpanBERT
论文链接:
SpanBERT: Improving Pre-training by Representing and Predicting Spans
代码链接:
https://github.com/facebookresearch/SpanBERT
这篇论文中提出了一种新的mask的方法,以及一个新损失函数对象。并且讨论了bert中的NSP任务是否有用。接下来SpanBERT是如何预训练的,具体如下图所示:

如上图所示,首先这里的mask策略是span mask。具体的做法是首先从一个几何分布中采样span的长度,且限制最大长度为10,然后再随机采样(如均匀分布) span的初始位置。整个训练任务就是预测mask的token,另外mask的比例问题和bert中类似。但是在这里引入了两个损失对象,LMLM 和LSBO,LMLM和bert中的一样,而这个LSBO是只通过span的边界处的两个token来预测span中mask的词,公式表示如下:
![]()
函数f(.)表示如下:

除了这些之外还有两个策略,一是动态mask,在bert中是在数据预处理阶段对一条序列随机不同的mask 10次,而在这里是每次epoch时对序列使用不同的mask。二是bert中会在数据预处理阶段生成10%的长度短于512的序列,而在这里不做这样的操作,只是对一个document一直截取512长度的序列,但最后一个序列长度可能会小于512。另外将adam中的ϵ设置为1e-8。作者根据这两个策略从新训练了一个bert模型,同时去除NSP任务只使用单条序列训练了一个bert模型。因此作者给出了四个模型的性能对比:
- Google BERT:谷歌开源的bert
- Our BERT:基于上面两个策略训练出来的bert
- Our BERT-1seq:基于上面两个策略,且去除NSP任务的bert
- SpanBERT:本篇论文提出的模型
作者给出的第一个性能测试的表格是在SQuAD数据集上

SpanBERT是有很大的提升的,另外去除NSP任务也有提升,作者认为NSP任务使得单条序列的长度不够,以至于模型无法很好的捕获长距离信息。另外在其他的抽取式QA任务上也有很大的提升。
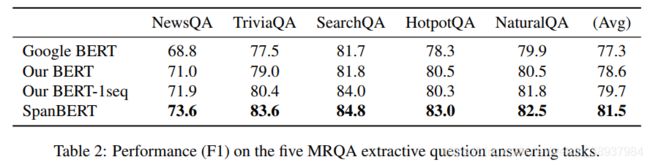
个人认为SpanBERT在抽取式QA任务上能取得如此大的提升,是因为SpanBERT中构造的任务,尤其是SBO任务实际上是有点贴合抽取式QA任务的。
在其他任务上SpanBERT也有一些提升,但是没有在抽取式QA任务上提升这么大,此外作者也做实验表示随机mask span的效果是要优于mask 实体或者短语的。
综合来说,SpanBERT在抽取式QA上的效果表现优异,在抽取式QA上是值得尝试的。
2. RoBERTa
论文链接:
RoBERTa: A Robustly Optimized BERT Pretraining Approach
代码链接:
https://github.com/brightmart/roberta_zh
本篇论文主要是在bert的基础上做精细化调参,可以看作是终极调参,最后性能不仅全面碾压bert,且在大部分任务上超越了XL-Net。
总结下,主要有以下六处改变的地方:
- Adam算法中的参数调整,ϵ由1e-6改成1e-8,β2由0.999改成0.98。
- 使用了更多的数据,从16GB增加到160GB。
- 动态mask取代静态mask。
- 去除NSP任务,并采用full-length 序列。
- 更大的batch size,更多的训练步数。
- 用byte-level BPE取代character-level BPE。
接下来我们来结合作者的实验看看。首先作者任务调整adam的参数是可以使得训练更加稳定且也能取得更好的性能,但并没有给出实验数据。增加数据提升性能是毋庸置疑的。
动态mask
在bert中是在数据预处理时做不同的mask 10次,这样在epochs为40的时候,平均每条mask的序列会出现4次,作者在这里使用动态mask,即每次epochs时做一次不同的mask。结果对比如下:

说实话,没觉得有多大提升,毕竟我们在训练模型的时候,一条数据也会被模型看到多次。
模型输入
对比了有无NSP任务的性能,以及不同的序列输入的性能,作者在这里给出了四种输入形式:
- SEGMENT-PAIR + NSP:两个segment组成句子对,并且引入NSP任务。
- SENTENCE-PAIR + NSP:两个sentence组成句子对,并且引入NSP任务,总长可能会比512小很多。
- FULL-SENTENCES:有多个完成的句子组成,对于跨文档的部分,用一个标识符分开,但是总长不超过512,无NSP任务。
- DOC-SENTENCES:有多个完整的句子组成,但是不跨文档,总长不超过512。
性能如下:

显然直接用句子对效果最差,作者认为主要时序列长度不够,导致模型无法捕捉长距离信息。并且去除NSP任务效果也有所提升。
更大的batch size,更多的训练次数
作者认为适当的加大batch size,既可以加速模型的训练,也可以提升模型的性能。

之后作者在8k的batch size下又增大训练次数

从实验中可以看出采用更大的训练次数,性能也是有不小的提升的。并且可以看到即使在训练数据差不多的情况下,RoBERTa也是要优于BERT的。
总之RoBERTa是一个调参成功的BERT,在诸多任务上全面超越bert,大部分超越XL-Net。
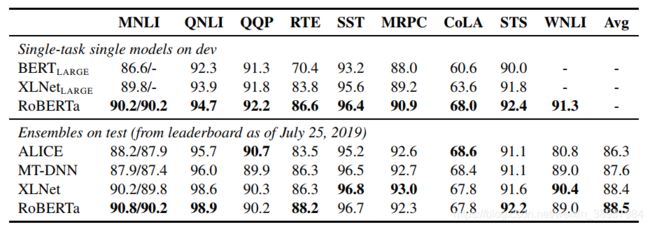
3. ERNIE2
论文链接:
ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
代码链接:
https://github.com/PaddlePaddle/ERNIE
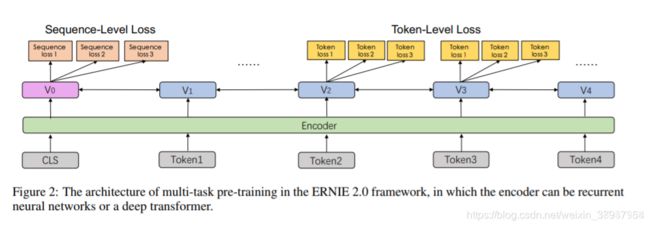
ERNIE2是百度在ERNIE1基础上的一个升级版,不过这次升级幅度比较大,提出了一个持续学习的机制(continual learning)。这个机制比较有意思,有点模仿人学习的形式。我们人是在不断学习,并且是多种任务不停交叉学习。有人觉得工作后就不用学习了,但其实工作才是真正学习的开始。上学期间你可能只是单纯地学习,但在工作中需要快速边做边学(learning by doing,不知道这种机制能否引入到AI中),这时候更能体现一个人的快速学习能力。稍微扯远了,回归下正题。持续学习包括持续构建预训练任务和增量多任务学习两个部分,具体下图:

连续预训练的架构如下图,它包含一系列共享的文本编码层来编码上下文信息,这些文本编码层可以通过循环神经网络或 Transformer 构建,且编码器的参数能通过所有预训练任务更新。
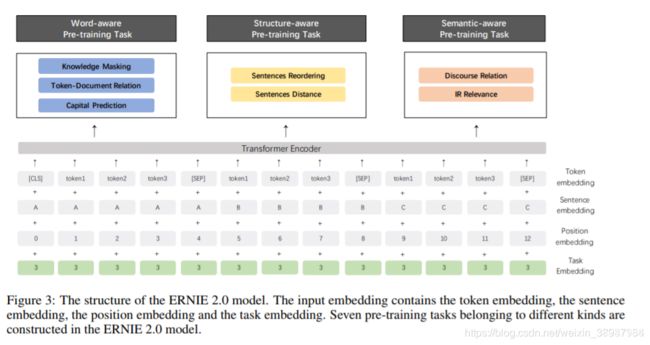
不同于ERNIE1仅有词级别的Pretraining Task,ERNIE2考虑了词级别、结构级别和语义级别3类Pretraining Task,词级别包括Knowledge Masking(短语Masking)、Capitalization Prediction(大写预测)和Token-Document Relation Prediction(词是否会出现在文档其他地方)三个任务,结构级别包括Sentence Reordering(句子排序分类)和Sentence Distance(句子距离分类)两个任务,语义级别包括Discourse Relation(句子语义关系)和IR Relevance(句子检索相关性)两个任务。三者关系如图:
就pre-train的多任务loss而言,个人觉得已经考虑很全了,并且个人之前也比较看好pre-train multi-task学习方向。BERT某种程度上也是一个multi-task学习,包含两个loss。虽然RoBERTa和其他一些文章说next prediction loss已是非必须,但multi-task始终是一个可以前进的方向,尤其是在数据和模型结构不变的情况下,使用multi-task理论上会有些提升。当然multi-task的不足在于如何有效训练多任务,ERNIE2采用了持续学习的机制,多个任务轮番学习,这有点类似于我们人上学,这节课学语文,下节课学数学,再下节课学英语。预训练数据相比BERT来说有所增加,英文约增加了2倍,中文约增加了1倍多。
ERNIE2要优于BERT和XLNet。但也有两点疑惑:
- 作者为什么不再探索下多任务带来的效果到底有多少,可以在定量分析下。要不然现在的结果到底多少是数据带来的,多少是多任务带来的,其实并不清楚,multi-task这条路到底能走多远没有给出答案;
- RoBERTa与ERNIE2相比,RoBERTa英文数据增加了10倍,ERNIE2数据应该是增加两倍,但做了很多模型loss上的增加,从GLUE效果上看,显然RoBERTa要比ERNIE2好一些,这是不是反映模型改进提升有限,当前还是多增加预训练数据效果来得更快些。