基于pytorch建立的模型踩坑记录
踩坑目录
1. forward函数内不要定义网络层
2. 每个batch中 时间序列长度不同的问题
3. GPU利用率低的问题
4. Pytorch: RuntimeError: expected Double tensor (got Float tensor)
5. Python: 使用pairwise_distance函数计算l1范数距离出现错误
开始使用pytorch建立神经网络模型,对一些遇到的坑进行记录。
1. forward函数内不要定义网络层。如卷积层、全连接层等
定义model类的时候,有init函数用于初始化一些网络层,forward里进行前向计算。
网络层,如Conv层、Linear层,要将其放在init里,不要放在forward里。
但需要注意的是,池化层定义在forward里应该是没有问题的。
测试案例:
1. 函数层放在init函数里:
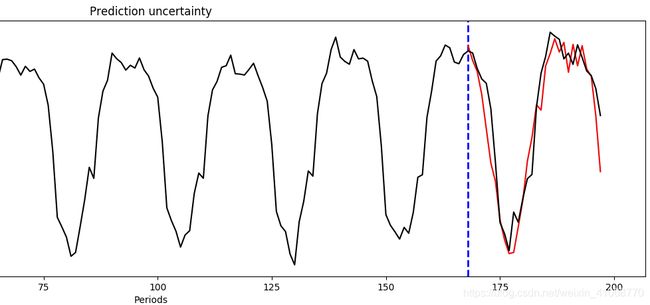
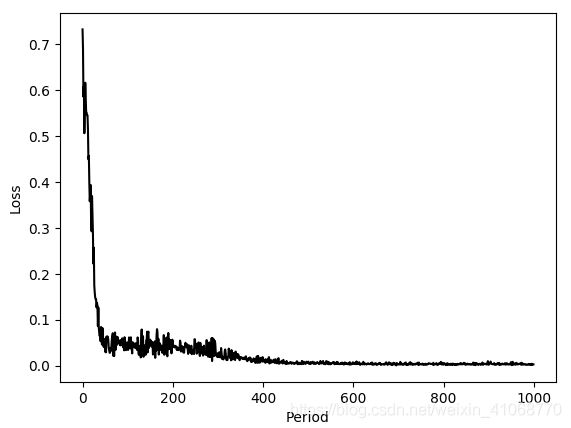
函数层放在forward函数里:

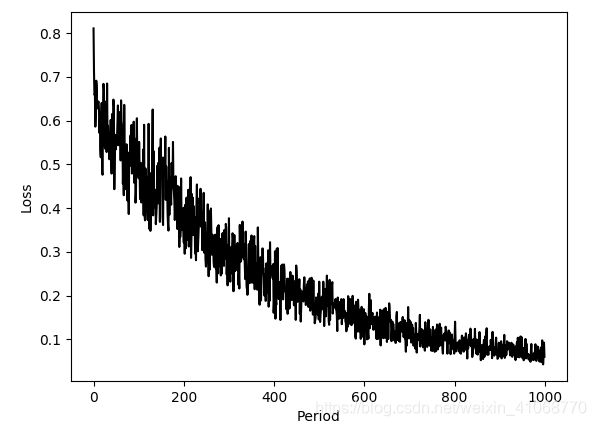
猜测可能是因为在forward里定义函数层的话,其在测试时候没有eval,测试结果中,预测的data效果巨差。此外,虽然loss也是下降的,但是与第一个结果也存在明显差异。
2. 每个batch中 时间序列长度不同的问题
在时间序列处理中,采用在每个batch中选择最长长度序列长度 + 补零。
因此,在每个batch中,时间序列长度是不一样的,例如,在第一个时间序列batch为 (128, 36, 8),128位批大小,36为时间步长, 8位每个时间戳的特征量大小。第二个时间序列batch为(128, 46, 8)。
这就带来了问题,在lstm模型中,时间序列长度不一,对于一些应用可能带来影响。
解决方式:
torch.cat和torch.zeros,整理来说就是进行补零,相关代码如下:
a = torch.zeros((500, 32, 8))
b = torch.zeros((500, 12, 8))
c = torch.cat((a,b),1)
这样,c就被步长到了50个时间戳长度。对于46时间戳的方式,也可以用这个方法。
这在解决的问题之一,是batch内time steps长度一样的同时,补零到长度多少是一个问题,其实可以根据时间戳最长度进行组合,也可以人为设置一个大的数字,例如500、600等。
3. 手写模型GPU占用率低问题
自己写了一个attention的框架方法,在GPU训练时,一个256尺寸的数据的训练时间高达13min,简直是灾难。
大佬听到了我的这个答案之后,无奈的指导让我查看一下cpu和gpu的占用。
查看CPU占用指令:
top看CPU的占用率。
查看GPU占用率:
nvidia-smi

smi的数据解读:

发现问题,GPU使用率竟然一直是1% 0%,说明很多关于数据的运算没有在GPU中进行。
解决方案: 将手写的Attention函数加入cuda,放入GPU中进行运算。
经过修改,现在经过一个batch_size的运行时间约为1min,较原来的14min明显改善,查看GPU的占用率也为33%多,GPU真香。
4. Pytorch: RuntimeError: expected Double tensor (got Float tensor)
错误提示为此时的量是一个double类型的tensor,而应该是一个float类型的。
解决方案:
tensor.from_numpy(img).float()5. Python: 使用pairwise_distance函数计算l1范数距离出现错误
错误提示:return torch.pairwise_distance(x1, x2, p, eps, keepdim)
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
解决方案: 直接写就行了
pwise_dist = torch.abs(distance_embeddings1[edge_ixs0[0]]- distance_embeddings1[edge_ixs0[1]])