AI&BigData four:使用scrapy爬取网站,按照指定的格式存入txt文本的详细过程复盘
用了将近两个星期,终于对scrapy有了初步了解,并且使用scrapy来爬取到了动态加载的网页。再此给自己这两周的学习成果做一个详细的过程复盘,顺带重温下忘掉的知识。
首先看看项目要求。
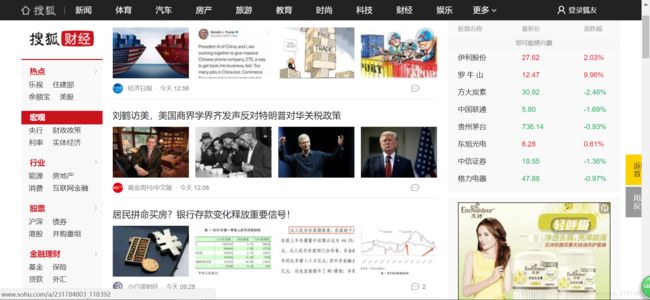
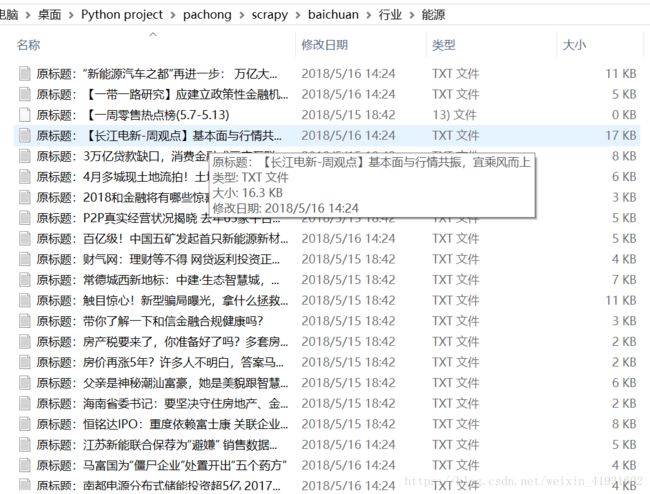
要爬取的是左边的四个大板块里的四个小版块的文章,然后按照以下的格式保存在文档中。
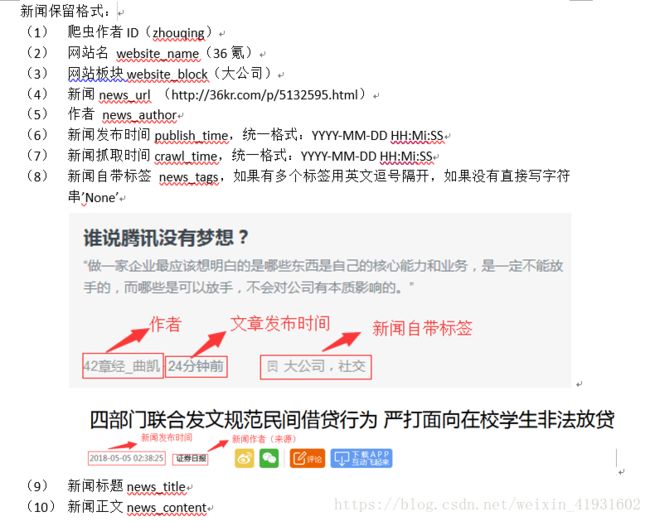
最终爬取的结果是这样的:

接下来让我们看看具体过程是怎样的?
1.打开命令行,跳转到指定文件存放的目录下,新建一个scrapy项目。如下所示
cd C:\Users\ME\Desktop\Python project\pachong\scrapy
scrapy startproject test(项目名称)
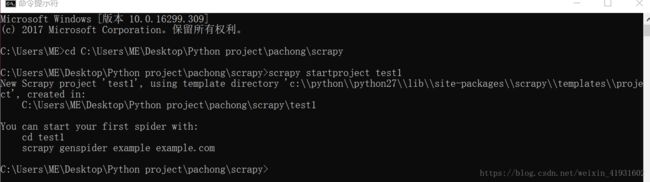
我们可以看到有两个提示:
You can start your first spider with:
cd test1
scrapy genspider example example.com
第一个就是直接跳转到项目根目录下。
第二个就是新建爬虫文件,新建爬虫文件我们可以在spiders目录下创建,建议使用scrapy genspider example example.com
example指的是爬虫文件,example.com指的是要爬取的网址首页,也就是最开始的首页。
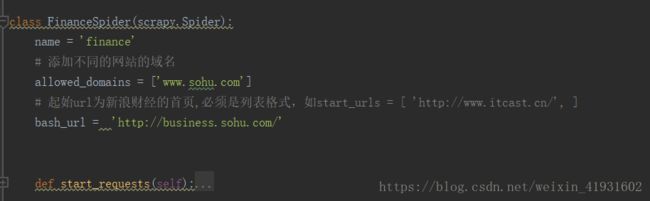
我们先跳转到根目录下 cd test1之后,输入: scrapy genspider finance business.sohu.com
在pycharm中就会自动生成文件,并且在爬虫文件finance.py中自动生成一些代码,不然的话还要自己手打,忒麻烦。
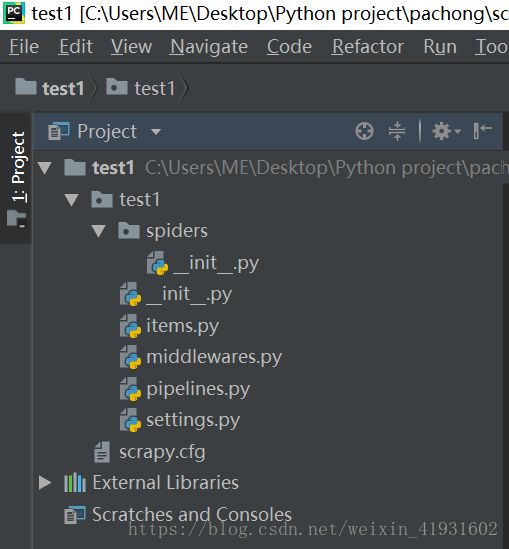
scrapy.cfg: 项目的配置文件
test1/: 该项目的python模块。之后您将在此加入代码。
test1/items.py: 项目中的item文件.
test1/pipelines.py: 项目中的pipelines文件.
test1/settings.py: 项目的设置文件
test1/spiders/: 放置spider代码的目录.
Scrapy默认是不能在IDE中调试的,所以呢我们要新建一个文件放到根目录下,这个名字你喜欢怎么取都行,这里举一个例子。
在根目录中新建一个py文件叫:main.py;在里面写入以下任意一个内容,但是要注意文件名是你的爬虫名字这个很关键。这里的爬虫名字就是finance
from scrapy import cmdline
name ='finance'
cmd = 'scrapy crawl {0}{1}'.format(name,'')
cmdline.execute(cmd.split())from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'finance'])# from scrapy.cmdline import execute
# import os
# import sys
# #因为每次要输入副目录很麻烦,通过调用这两个模块,能够快速找到main文件的副目录
# sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# #print os.path.dirname(os.path.abspath(__file__))
# #添加完命令之后,我们在项目下的Spyder的爬虫文件就可以设置断点进行调试了
# execute(['scrapy','crawl','finance'])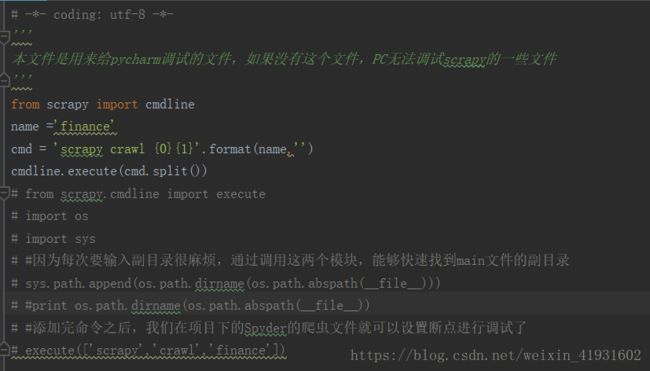
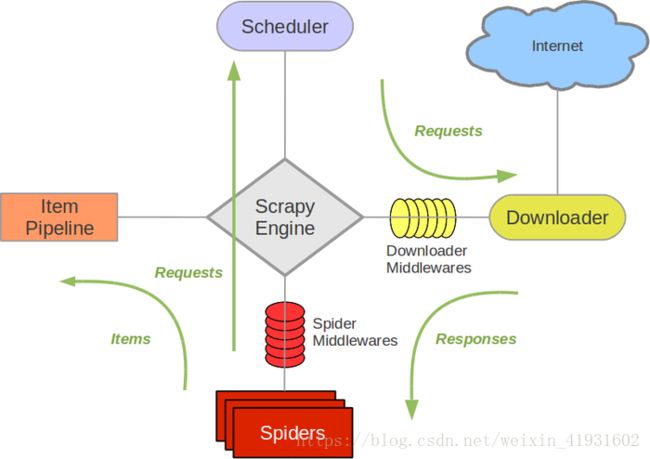
首先了解下scrapy爬虫是怎么工作的,我们在官方文档中看到这幅图:



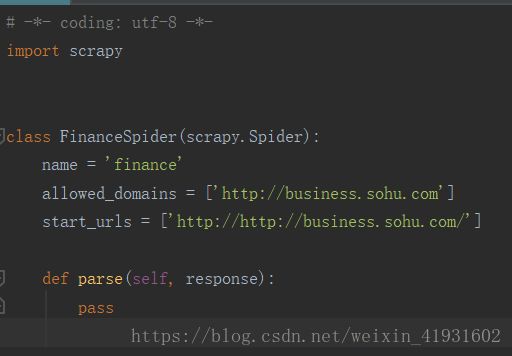
我们再回过头来看看创建的爬虫文件

在开始编辑爬虫文件之前,我们做一些基本的准备工作。
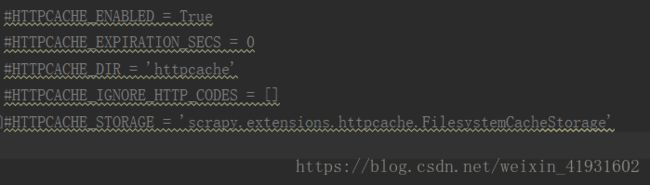
1.在settings.py中取消最下面几行的注释:作用在于Scrapy会缓存你有的Requests!当你再次请求时,如果存在缓存文档则返回缓存文档,而不是去网站请求,这样既加快了本地调试速度,也减轻了 网站的压力。一举多得
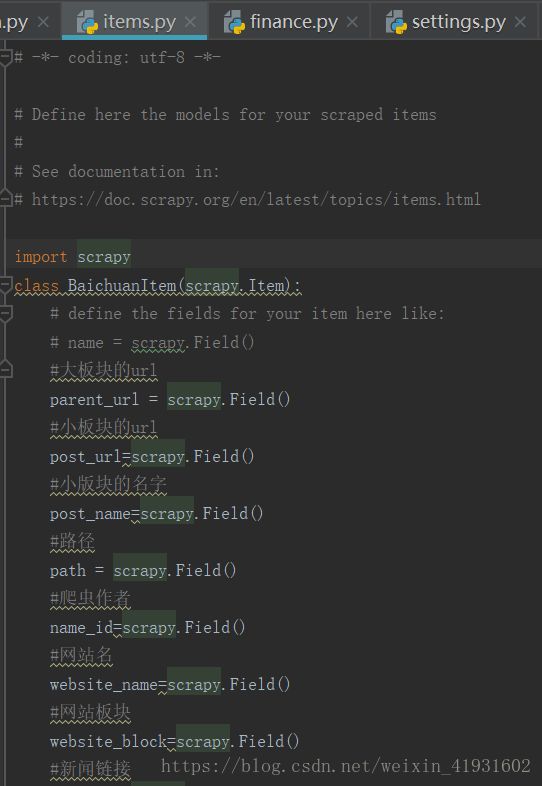
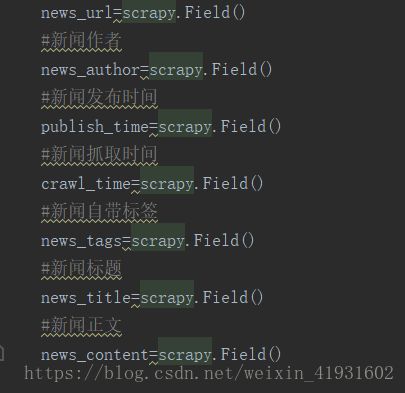
2.在items.py 文件中根据需求定义一些字段
比如说大板块的名字,url,小版块的名字,url,新闻作者,发布时间,抓取时间,标题,正文等等。
这样爬虫爬取的文件就会对应保存在相关的字段中了。
好了,是不是已经等不及了,我们现在就开始编写我们的爬虫文件
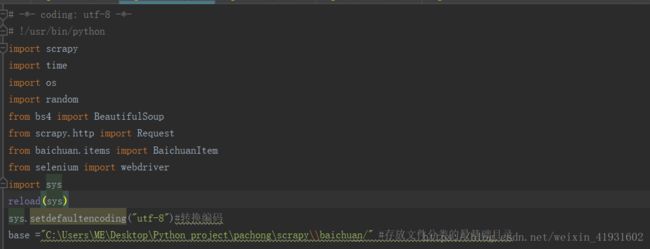
首先先把一些需要使用的包给导入进去,这样方便之后的编写。具体哪些包有什么用,自行百度就好。
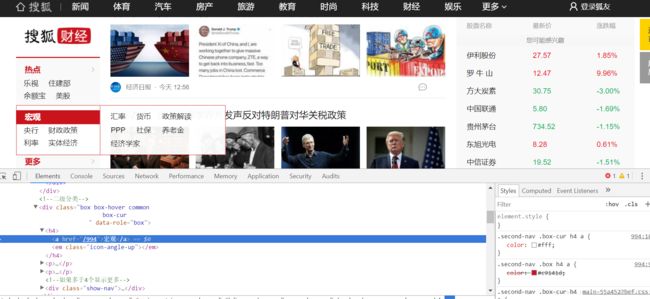
接下来看看类,以及开始的url设置。我们先点击到网页,右键检查网页源代码。使用谷歌浏览器也可以F12检查网页。
可以看到我们想要的四个版块的url分别是:
http://business.sohu.com/994
http://business.sohu.com/996
http://business.sohu.com/997
http://business.sohu.com/998


所以在这里我们用一个for循环和if语句得到想要的四个数字994,996,997,998
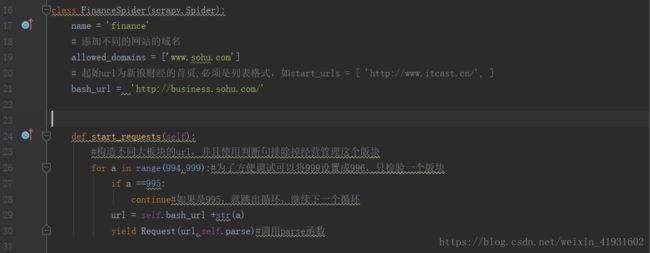
在这里我们的yield主要是将生成的url传递给下一个函数,在调用下一个函数的时候,记得别忘了添加self。
yield的作用大概如下:


举个例子:
#encoding:UTF-8
def yield_test(n): for i in range(n): yield call(i) print("i=",i) #做一些其它的事情 print("do something.") print("end.") def call(i): return i*2 #使用for循环 for i in yield_test(5): print(i,",")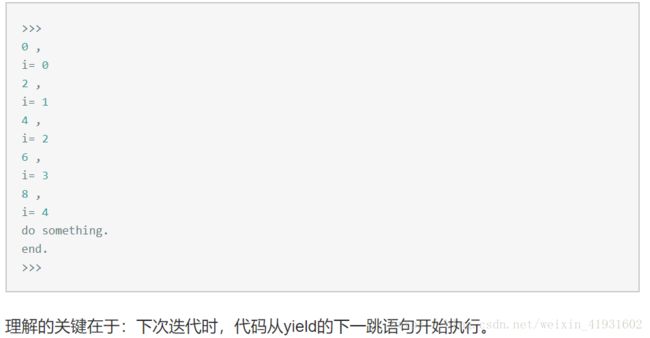
使用parse函数接受上面request获取到的response。(不要轻易改写parse函数;因为这样request的回调函数被你用了,就没谁接受request返回的response啦!如果你非要用作它用,则需要自己给request一个回调函数哦!)
接下来我们来编写parse函数,先把代码贴上来:
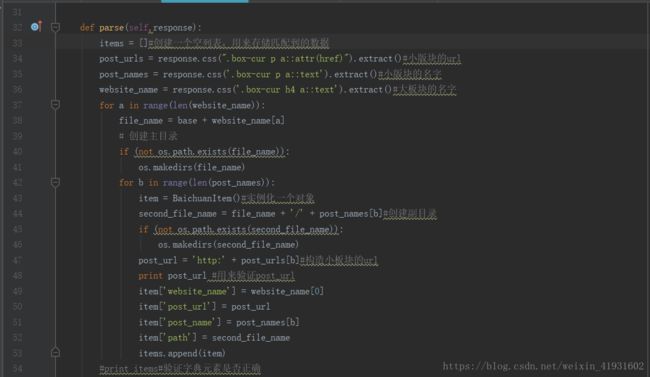

对这个函数做一些细节性的解释吧!
首先我们要匹配到大小版块的url和名字,我们可以采用xpath,css,bs4,以及正则表达式,在这里我们使用的是scrapy自带的xpath或者css来进行匹配。
因为网页的布置基本是一样的,所以在此我们以 宏观 为例子进行。
首先在命令行窗口输入scrapy shell http://business.sohu.com/994 进入shell窗口这样就很好调试了,当然在每句话后设置断点,加print语句后,再在main文件调试也是可以的,点击绿色的小虫子就可以。
如下所示
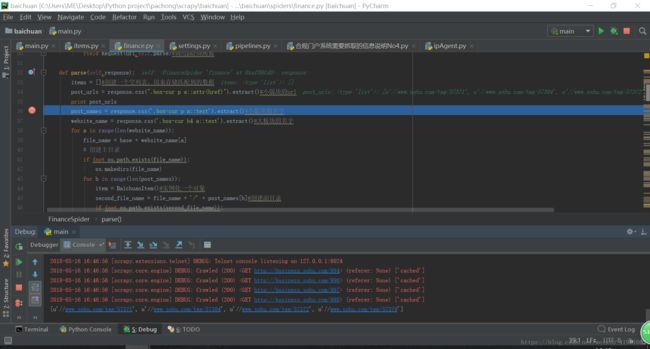
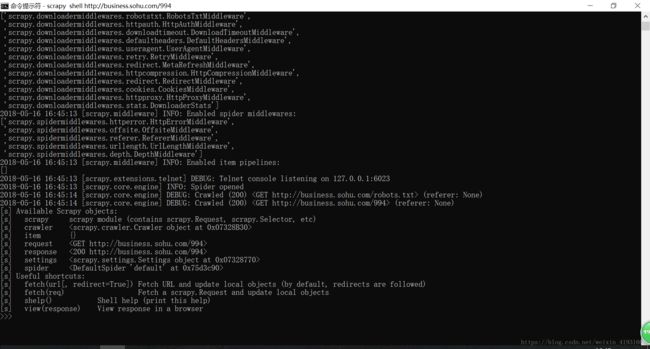
在scrapy shell中主要有两种方法:xpath和css,可以参考官方文档,也可以百度一些别人整理的。
主要看的是标签后的两个属性:id ,class
接下来我们试验一下。匹配四个小板块的url,分别是:

对应的标签是div,属性有很多,挑其中一个box-cur。接下来是h4,然后是a
所以我们输入response.css(".box-cur p a::attr(href)") 还有 response.css(".box-cur p a::attr(href)").extract() ,感受一下区别。可以自行了解下extract()的用法

接下来是xpath,xpath的语法可以自行百度,也可以直接在浏览器中右键检查,找到指定想要的标签,右键copy xpath,轻轻松松粘贴复制
接下来输入response.xpath('//*[@id="left-nav"]/div[2]/div[2]/p[1]/a/text()')和 response.xpath('//*[@id="left-nav"]/div[2]/div[2]/p[1]/a/text()').extract()
接下来看看结果

在这里提提自己遇到的一些错误 :
1.xpath粘贴的话容易出错,最好还是懂一点语法,按照语法写才能正确匹配到想要的,纯粹复制只能定位到一个
2.注意网址和你匹配的内容是否一致,不然容易出现【】
3.注意xpath里的单引号和双引号,别重叠在一起
4.(挖坑待填)
这里顺带提一些常用的语法



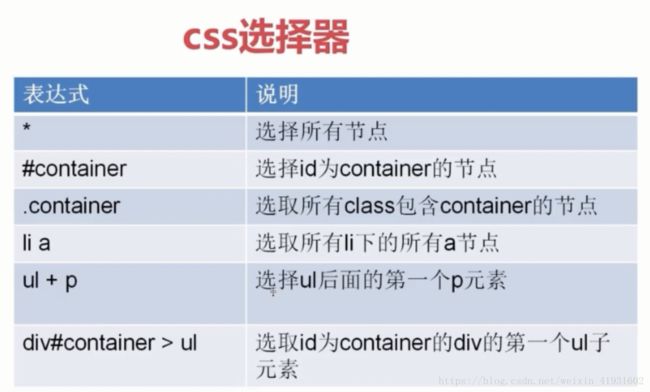
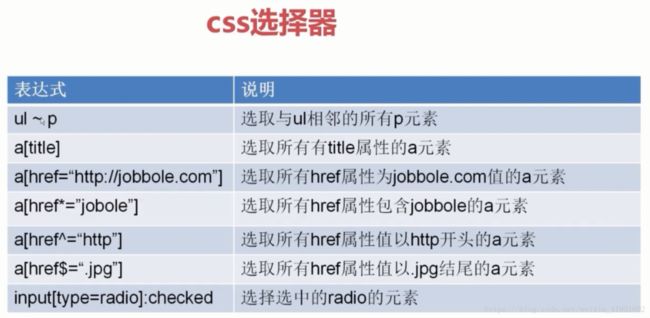
在命令行窗口匹配成功后,我们就复制到pycharm中。
37行-41行,使用for循环遍历大板块,顺便使用if语句和os版块来创建大板块新目录,记得代码一开始别忘了# !/usr/bin/python
这个是用来说明创建文件夹的
42行-53行,使用for循环遍历小版块,继续创建小板块新目录。然后得到url,但是这种是缺省url,所以我们需要在构建一下,添加http:,然后print语句,调试看看是否正确。
正确之后,我们把得到的正确变量赋值给字典里。
54行-58行,设置断点,验证items的结果是否是你想要的。如果是就继续,不是就找找错误的原因。58行就多了一个meta这么一个字典,这是Scrapy中传递额外数据的方法。我们还有一些其他内容需要在下一个页面中才能获取到
为什么要使用字典?因为这样可以将多个数据进行打包传递。想想看,如果你一个个数据传,而且这些数据还要一个个赋值给下一个函数的变量,效率多低,最重要是累啊!python的宗旨不是越简洁越好嘛!
每次得到一个需要的变量,都要测试一下是否符合自己想要的数据。前面保持正确了,后面才能正常输出。不然到时全部写完再进行调试,就非常麻烦了,而且后面的代码是错误的话,前面的就算设置了断点一样会出错。
在这里遇到过一个错误,卡了一天
错误:yield Request(url=post_url, callback=self.parse_news, meta={'item_1': item})
正确:yield Request(url=item['post_url'], callback=self.parse_news, meta={'item_1': item})
使用错误的话就只会爬到一个小版块,因为虽然循环遍历了列表,但是得到的post_url始终是相同的,之所以会错,是因为对字典的数据调用不熟悉,现在改为item['post_url'],得到的网址就是四个小版块的网址了。
继续继续,编程最重要的是学会解决问题,遇到问题不要怕,一个个检查问题出在哪里就好。
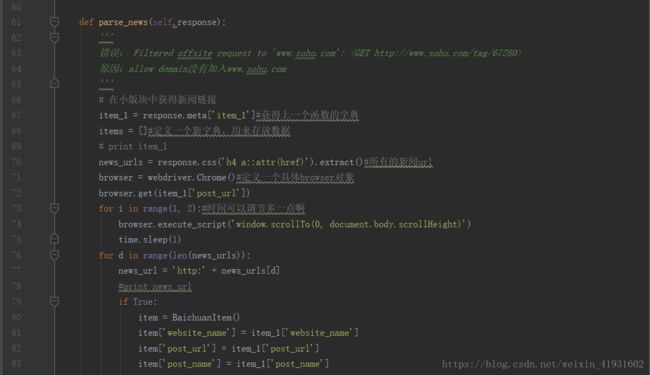

parse_news函数的作用是得到小版块中的所有文章的url,然后传递给下一个函数
67行-70行,将上一个函数得到的字典赋值给新字典item_1,顺便建立一个新的列表装东西,还有就是匹配到所有文章的链接。
71行-75行,定义一个具体browser对象,然后使用get函数得到文章的url。接下来使用for循环,目的是模仿人一样滑动进度条,实现抓取动态网页的效果。range()指的是范围多少秒。time.slepp(1)表示的是一秒动一下。
76行-86行,和上一个函数作用相似,遍历所有的文章url,然后构造url,再把得到的数据一个个封装进item这个字典中,然后将一个个字典当做元素装进列表items中。
87行-89行,验证下得到的列表items里的数据是否是你想要的。然后一个个传递给下一个函数
写了这么多,懒癌又要犯了。洗把脸冷静一下。
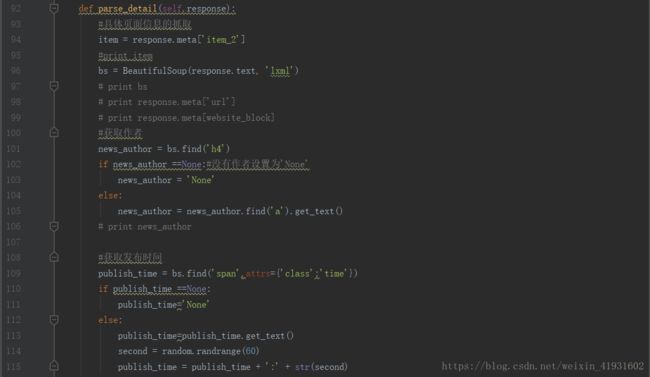
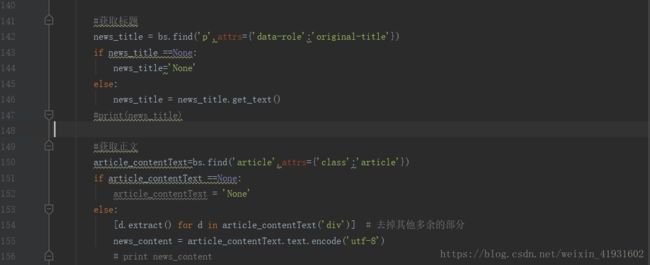
好我们继续来看,这个函数的主要作用呢就是要开始捕捉文章的具体字段了,开不开心?
xpath和css都讲完了,这里我们来提提bs4 的用法。
参考这篇文章吧
http://www.jb51.net/article/65287.htm92-99行,得到上一个函数的字典,然后新建一个对象。之中我们一样进行调试,看看有没有什么错误。好的,没有,那我们继续往下看。
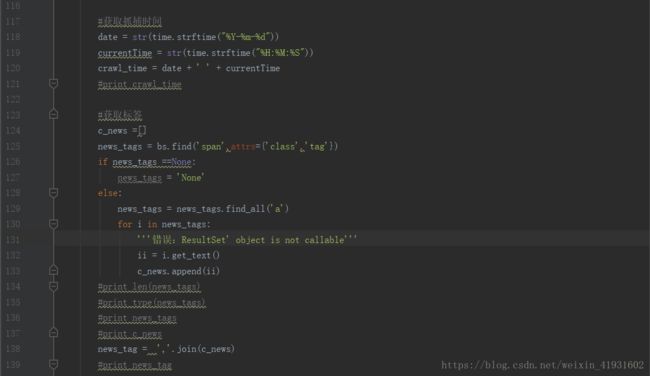
100-156行,获取作者并且进行判断,如果没有作者,就输出为none.后面同样的做法。这里提一下标签,因为标签我们是需要使用逗号隔离开的,因为得到的标签是列表,所以就使用join函数来将列表的元素串起来。
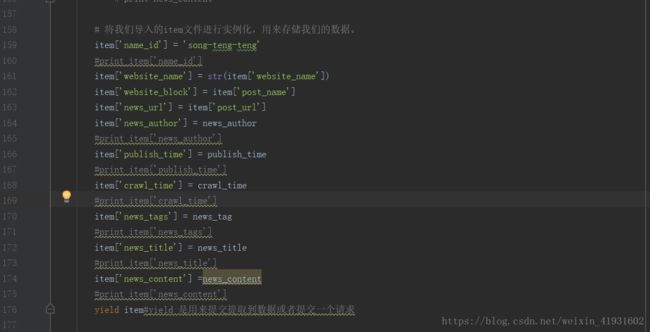
157-176行,将所有得到的按照我们需要的格式一个个赋值给字典。需要注意的是
item['website_name'] =str(item['website_name']),因为得到的item['website_name']类型是Unicode,这里把它转化成str类型。最后提交给item文件处理。
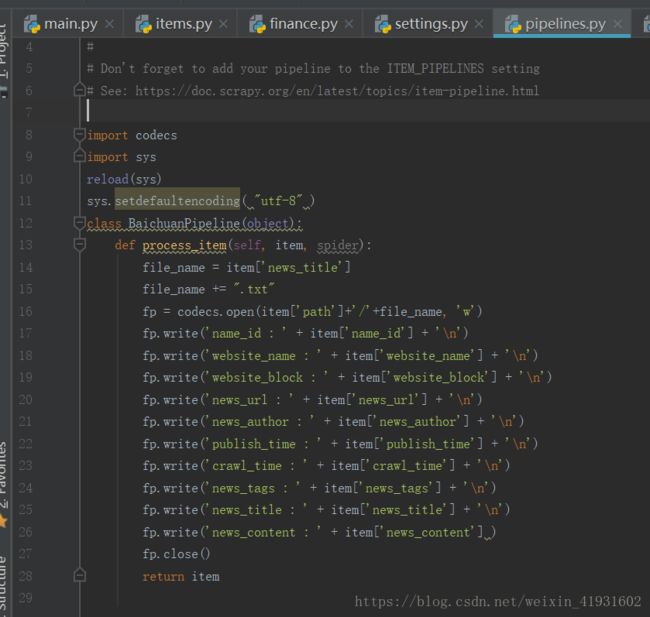
items得到数据之后,将数据传递给了pipeline文件,在这里我们来存取文件,选择最简单基础的方法,有兴趣可以去了解一些存储库,比如MySQL。
这里不需要多讲了,打开文件,写入文件,然后关闭文件。好的,下一个。。。。。。
一直循环往复,直到抓取完毕
还有一个要设置的就是settings文件



最后面点击运行main文件或者在命令行窗口输入scrapy crawl finance即可爬取文章了。不妨动手试试看吧!
(挖坑待填)