函数的最佳逼近问题:最小二乘法
函数的最佳逼近问题:最小二乘法
- 1. 最佳逼近问题
- 2. 最佳平方(最小二乘)逼近
- 离散情况——以线性回归为例
- 3. 最小二乘学习(离散情况的另一种描述)
- 最小二乘解的几何意义
- 4. 最小二乘法实现曲线拟合
- 4.1 线性回归(解方程组1)
- 4.2 周期函数的逼近(解方程组2)
1. 最佳逼近问题
\qquad 简单来说,最佳逼近问题就是用一些 (基)函数 φ i ( x ) , i ∈ { 0 , 1 , ⋯ , M } \varphi_{i}(\boldsymbol x),i\in \{0,1,\cdots,M\} φi(x),i∈{0,1,⋯,M} 的线性组合来逼近某个函数 f ( x ) f(\boldsymbol x) f(x),也就是定义
\qquad\qquad φ ( x ) = ∑ n = 0 M a n φ n ( x ) = a 0 φ 0 ( x ) + a 1 φ 1 ( x ) + ⋯ + a M φ M ( x ) \varphi(\boldsymbol x)=\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x)=a_{0}\varphi_{0}(\boldsymbol x)+a_{1}\varphi_{1}(\boldsymbol x)+\cdots+a_{M}\varphi_{M}(\boldsymbol x) φ(x)=n=0∑Manφn(x)=a0φ0(x)+a1φ1(x)+⋯+aMφM(x)
\qquad 使得 f ( x ) f(\boldsymbol x) f(x) 和 φ ( x ) \varphi(\boldsymbol x) φ(x) 在某种(度量)意义下最小,常见的度量包括 ℓ 1 \ell_{1} ℓ1 范数, ℓ 2 \ell_{2} ℓ2 范数(最佳平方逼近), ℓ ∞ \ell_{\infty} ℓ∞ 范数(最佳一致逼近)。
\qquad 例如,多项式曲线拟合的基函数可以定义为 φ n ( x ) = x n \varphi_{n}(x)=x^{n} φn(x)=xn,就有
\qquad\qquad φ ( x ) = ∑ n = 0 M a n φ n ( x ) = a 0 + a 1 x + a 2 x 2 + ⋯ + a M x M \varphi(x)=\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(x)=a_{0}+a_{1}x+a_{2}x^{2}+\cdots+a_{M}x^{M} φ(x)=n=0∑Manφn(x)=a0+a1x+a2x2+⋯+aMxM
\qquad 当 f ( x ) f(x) f(x) 具有周期性质,可以采用三角多项式来逼近,就有
\qquad\qquad φ ( x ) = a 0 + a 1 cos x + b 1 sin x + ⋯ + a M cos ( M x ) + b M sin ( M x ) \varphi(x)=a_{0}+a_{1}\cos x+b_{1}\sin x+\cdots+a_{M}\cos (Mx)+b_{M}\sin(Mx) φ(x)=a0+a1cosx+b1sinx+⋯+aMcos(Mx)+bMsin(Mx)
\qquad 若基函数具有正交性,则会大大简化最佳逼近问题。
\qquad
2. 最佳平方(最小二乘)逼近
\qquad 最佳平方逼近采用 ℓ 2 \ell_{2} ℓ2 范数来度量 f ( x ) f(\boldsymbol x) f(x) 和 φ ( x ) \varphi(\boldsymbol x) φ(x) 之间接近程度。
\qquad 函数 f ( x ) f(\boldsymbol x) f(x) 的最佳逼近 φ ∗ ( x ) \varphi^{*}(\boldsymbol x) φ∗(x) 满足:
\qquad\qquad ∥ f ( x ) − φ ∗ ( x ) ∥ 2 2 = min ∥ f ( x ) − φ ( x ) ∥ 2 2 \parallel f(\boldsymbol x)-\varphi^{*}(\boldsymbol x)\parallel_{2}^{2}=\min\parallel f(\boldsymbol x)-\varphi(\boldsymbol x)\parallel_{2}^{2} ∥f(x)−φ∗(x)∥22=min∥f(x)−φ(x)∥22
\qquad 因此,可定义误差函数 E ( a 0 , ⋯ , a M ) E(a_{0},\cdots,a_{M}) E(a0,⋯,aM) 为:
\qquad\qquad E ( a 0 , ⋯ , a M ) = ∥ f ( x ) − φ ( x ) ∥ 2 2 = ∥ f ( x ) − ∑ n = 0 M a n φ n ( x ) ∥ 2 2 = ∫ [ f ( x ) − ∑ n = 0 M a n φ n ( x ) ] 2 d x \begin{aligned} E(a_{0},\cdots,a_{M})&=\parallel f(\boldsymbol x)-\varphi(\boldsymbol x)\parallel_{2}^{2}\\ &=\parallel f(\boldsymbol x)-\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x)\parallel_{2}^{2}\\ &=\int [ f(\boldsymbol x)-\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x) ]^2dx \end{aligned} E(a0,⋯,aM)=∥f(x)−φ(x)∥22=∥f(x)−n=0∑Manφn(x)∥22=∫[f(x)−n=0∑Manφn(x)]2dx
\qquad 此时,误差函数 E ( a 0 , ⋯ , a M ) E(a_{0},\cdots,a_{M}) E(a0,⋯,aM) 为系数 ( a 0 , ⋯ , a M ) (a_{0},\cdots,a_{M}) (a0,⋯,aM) 的二次函数,其取极值的必要条件为:
\qquad\qquad ∂ E ( a 0 , ⋯ , a M ) ∂ a k = 0 ( k = 0 , 1 , ⋯ , M ) \begin{aligned} \dfrac{\partial E(a_{0},\cdots,a_{M})}{\partial a_{k}}&=0\qquad(k=0,1,\cdots,M)\\ \end{aligned} ∂ak∂E(a0,⋯,aM)=0(k=0,1,⋯,M)
\qquad 因此
\qquad\qquad ∂ E ( a 0 , ⋯ , a M ) ∂ a k = − 2 ∫ [ f ( x ) − ∑ n = 0 M a n φ n ( x ) ] φ k ( x ) d x = 0 ( k = 0 , 1 , ⋯ , M ) \begin{aligned} \dfrac{\partial E(a_{0},\cdots,a_{M})}{\partial a_{k}}&=-2\int [ f(\boldsymbol x)-\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x) ]\varphi_{k}(\boldsymbol x)dx \\ &=0\qquad(k=0,1,\cdots,M)\\ \end{aligned} ∂ak∂E(a0,⋯,aM)=−2∫[f(x)−n=0∑Manφn(x)]φk(x)dx=0(k=0,1,⋯,M)
\qquad 于是
\qquad\qquad ∫ f ( x ) φ k ( x ) d x = ∫ ∑ n = 0 M a n φ n ( x ) φ k ( x ) d x = ∑ n = 0 M a n ∫ φ n ( x ) φ k ( x ) d x \begin{aligned} \int f(\boldsymbol x)\varphi_{k}(\boldsymbol x)dx&=\int\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x) \varphi_{k}(\boldsymbol x)dx \\ &=\sum\limits_{n=0}^{M}a_{n}\int\varphi_{n}(\boldsymbol x) \varphi_{k}(\boldsymbol x)dx \\ \end{aligned} ∫f(x)φk(x)dx=∫n=0∑Manφn(x)φk(x)dx=n=0∑Man∫φn(x)φk(x)dx
\qquad 写成函数内积的形式:
\qquad\qquad ( f , φ k ) = ∑ n = 0 M a n ( φ n , φ k ) (f,\varphi_{k})=\displaystyle\sum_{n=0}^{M}a_{n}(\varphi_{n},\varphi_{k}) (f,φk)=n=0∑Man(φn,φk)
\qquad 实际上是一个关于 a 0 , ⋯ , a M a_{0},\cdots,a_{M} a0,⋯,aM 的线性方程组,称为法方程 ( n o r m a l e q u a t i o n ) (normal\ equation) (normal equation):
\qquad
\qquad\qquad [ ( φ 0 , φ 0 ) ( φ 1 , φ 0 ) ⋯ ( φ M , φ 0 ) ( φ 0 , φ 1 ) ( φ 1 , φ 1 ) ⋯ ( φ M , φ 1 ) ⋮ ⋮ ⋮ ⋮ ( φ 0 , φ M ) ( φ 1 , φ M ) ⋯ ( φ M , φ M ) ] [ a 0 a 1 ⋮ a M ] = [ ( f , φ 0 ) ( f , φ 1 ) ⋮ ( f , φ M ) ] ( 1 ) \left[\begin{matrix}(\varphi_{0},\varphi_{0})&(\varphi_{1},\varphi_{0})&\cdots&(\varphi_{M},\varphi_{0})\\ (\varphi_{0},\varphi_{1})&(\varphi_{1},\varphi_{1})&\cdots&(\varphi_{M},\varphi_{1})\\ \vdots&\vdots&\vdots&\vdots\\ (\varphi_{0},\varphi_{M})&(\varphi_{1},\varphi_{M})&\cdots&(\varphi_{M},\varphi_{M})\\ \end{matrix}\right] \left[\begin{matrix}a_{0}\\ a_{1}\\ \vdots\\ a_{M}\\ \end{matrix}\right]=\left[\begin{matrix}(f,\varphi_{0})\\ (f,\varphi_{1})\\ \vdots\\ (f,\varphi_{M})\\ \end{matrix}\right]\qquad(1) ⎣⎢⎢⎢⎡(φ0,φ0)(φ0,φ1)⋮(φ0,φM)(φ1,φ0)(φ1,φ1)⋮(φ1,φM)⋯⋯⋮⋯(φM,φ0)(φM,φ1)⋮(φM,φM)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡a0a1⋮aM⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡(f,φ0)(f,φ1)⋮(f,φM)⎦⎥⎥⎥⎤(1)
\qquad
\qquad 求解该线性方程组,就可以得到系数 ( a 0 , ⋯ , a M ) (a_{0},\cdots,a_{M}) (a0,⋯,aM) 的值。
\qquad 对于连续函数的内积,通常有:
\qquad\qquad ( f , φ k ) = ∫ a b f ( x ) φ k ( x ) d x (f,\varphi_{k})=\int_a^bf(x)\varphi_{k}(x)dx (f,φk)=∫abf(x)φk(x)dx
\qquad 以及
\qquad\qquad ( φ n , φ k ) = ∫ a b φ n ( x ) φ k ( x ) d x (\varphi_{n},\varphi_{k})=\int_a^b\varphi_{n}(x)\varphi_{k}(x)dx (φn,φk)=∫abφn(x)φk(x)dx
\qquad
离散情况——以线性回归为例
\qquad 离散情况时,以一维线性回归为例,已知观测样本集 { x i , y i } ∣ 0 N \{x_{i},y_{i}\}\big|_{0}^{N} {xi,yi}∣∣0N,要求出函数 f ( x ) f(x) f(x) 的逼近函数:
φ ( x ) = ∑ n = 0 1 a n φ n ( x ) = a 0 + a 1 x \qquad\qquad\varphi(x)=\sum\limits_{n=0}^{1}a_{n}\varphi_{n}(x)=a_{0}+a_{1}x φ(x)=n=0∑1anφn(x)=a0+a1x
\qquad 
\qquad 上图中,线性回归关于每个观测点 ( x i , y i ) (x_{i},y_{i}) (xi,yi) 的 ℓ 2 \ell_{2} ℓ2 损失(平方误差)为: [ φ ( x i ) − y i ] 2 [\varphi(x_i)-y_i]^2 [φ(xi)−yi]2
\qquad 误差函数定义为“误差的平方之和”:
\qquad\qquad E ( a 0 , a 1 ) = [ φ ( x 0 ) − y 0 ] 2 + [ φ ( x 1 ) − y 1 ] 2 + ⋯ + [ φ ( x N ) − y N ] 2 = ∑ i = 0 N [ φ ( x i ) − y i ] 2 = ∑ i = 0 N ( y i − a 0 − a 1 x i ) 2 \begin{aligned}E(a_{0},a_{1})&=[\varphi(x_0)-y_0]^2+[\varphi(x_1)-y_1]^2+\cdots+[\varphi(x_N)-y_N]^2\\ &=\displaystyle\sum_{i=0}^{N}[\varphi(x_i)-y_i]^2\\ &=\displaystyle\sum_{i=0}^{N}(y_i-a_{0}-a_{1}x_i)^2 \end{aligned} E(a0,a1)=[φ(x0)−y0]2+[φ(x1)−y1]2+⋯+[φ(xN)−yN]2=i=0∑N[φ(xi)−yi]2=i=0∑N(yi−a0−a1xi)2
\qquad 通过求出系数 ( a 0 , a 1 ) (a_{0},a_{1}) (a0,a1) 的值,用 φ ( x ) ≈ f ( x ) \varphi(x)\approx f(x) φ(x)≈f(x)。
- 对误差函数求 a 0 a_{0} a0 的偏导:
∂ E ( a 0 , a 1 ) ∂ a 0 = 2 ∑ i = 0 N ( y i − a 0 − a 1 x i ) ( − 1 ) = 0 \qquad\qquad\dfrac{\partial E(a_0,a_1)}{\partial a_0} =2\displaystyle\sum_{i=0}^{N}(y_i-a_{0}-a_{1}x_i)(-1)=0 ∂a0∂E(a0,a1)=2i=0∑N(yi−a0−a1xi)(−1)=0
\qquad\qquad 可以写成: a 0 ∑ i = 0 N 1 + a 1 ∑ i = 0 N x i = ∑ i = 0 N y i \qquad a_0\sum\limits_{i=0}^{N}1+a_1\sum\limits_{i=0}^{N}x_i=\sum\limits_{i=0}^{N}y_i a0i=0∑N1+a1i=0∑Nxi=i=0∑Nyi
⟹ \qquad\qquad\qquad\qquad\quad\Longrightarrow ⟹ a 0 = 1 N ∑ i = 0 N ( y i − a 1 x i ) \ a_0=\dfrac{1}{N}\displaystyle\sum_{i=0}^{N}(y_i-a_1x_i) a0=N1i=0∑N(yi−a1xi)
- 对误差函数求 a 1 a_{1} a1 的偏导:
∂ E ( a 0 , a 1 ) ∂ a 1 = 2 ∑ i = 0 N ( y i − a 0 − a 1 x i ) ( − x i ) = 0 \qquad\qquad\dfrac{\partial E(a_0,a_1)}{\partial a_1} =2\displaystyle\sum_{i=0}^{N}(y_i-a_{0}-a_{1}x_i)(-x_i)=0 ∂a1∂E(a0,a1)=2i=0∑N(yi−a0−a1xi)(−xi)=0
\qquad\qquad 可以写成: a 0 ∑ i = 0 N x i + a 1 ∑ i = 0 N x i 2 = ∑ i = 0 N y i x i \qquad a_0\sum\limits_{i=0}^{N}x_i+a_1\sum\limits_{i=0}^{N}x_i^2=\sum\limits_{i=0}^{N}y_ix_i a0i=0∑Nxi+a1i=0∑Nxi2=i=0∑Nyixi
⟹ \qquad\qquad\qquad\qquad\quad\Longrightarrow ⟹ a 1 = ∑ i = 0 N ( y i − a 0 ) x i ∑ i = 0 N x i 2 \ a_1=\dfrac{\sum\limits_{i=0}^{N}(y_i-a_0)x_i}{\sum\limits_{i=0}^{N}x_i^2} a1=i=0∑Nxi2i=0∑N(yi−a0)xi
\qquad\qquad 代入 a 0 a_0 a0,可得到: a 1 = ∑ i = 0 N y i ( x i − 1 N ∑ i = 0 N x i ) ∑ i = 0 N x i 2 − 1 N ( ∑ i = 0 N x i ) 2 \ a_1=\dfrac{\sum\limits_{i=0}^{N}y_i\left(x_i-\frac{1}{N}\sum\limits_{i=0}^{N}x_i\right)}{\sum\limits_{i=0}^{N}x_i^2-\frac{1}{N}\left(\sum\limits_{i=0}^{N}x_i\right)^2} a1=i=0∑Nxi2−N1(i=0∑Nxi)2i=0∑Nyi(xi−N1i=0∑Nxi)
\qquad\qquad 若记样本的均值为 x ˉ = 1 N ∑ i = 0 N x i \bar x=\dfrac{1}{N}\sum\limits_{i=0}^{N}x_i xˉ=N1i=0∑Nxi,则 a 1 = ∑ i = 0 N y i ( x i − x ˉ ) ∑ i = 0 N x i 2 − N x ˉ 2 \ a_1=\dfrac{\sum\limits_{i=0}^{N}y_i\left(x_i-\bar x\right)}{\sum\limits_{i=0}^{N}x_i^2-N\bar x^2} a1=i=0∑Nxi2−Nxˉ2i=0∑Nyi(xi−xˉ)
\qquad 这种求解,实际上就是求4.1节中的解线性方程组 ( 1 ) (1) (1) 的过程。
\qquad
3. 最小二乘学习(离散情况的另一种描述)
\qquad 如下图所示,已知观测样本集 { x i , y i } ∣ 0 N \{\boldsymbol x_{i},y_{i}\}\big|_{0}^{N} {xi,yi}∣∣0N,仍然采用线性模型:
\qquad\qquad φ ( x ) = ∑ n = 0 M a n φ n ( x ) = a 0 φ 0 ( x ) + a 1 φ 1 ( x ) + ⋯ + a M φ M ( x ) = θ T ϕ ( x ) = ϕ T ( x ) θ \begin{aligned}\varphi(\boldsymbol x)&=\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(\boldsymbol x)\\ &=a_{0}\varphi_{0}(\boldsymbol x)+a_{1}\varphi_{1}(\boldsymbol x)+\cdots+a_{M}\varphi_{M}(\boldsymbol x)\\ &=\boldsymbol \theta^T\boldsymbol\phi(\boldsymbol x)=\boldsymbol\phi^T(\boldsymbol x)\boldsymbol \theta \end{aligned} φ(x)=n=0∑Manφn(x)=a0φ0(x)+a1φ1(x)+⋯+aMφM(x)=θTϕ(x)=ϕT(x)θ
\qquad 其中, θ = [ a 0 , a 1 , ⋯ , a M ] T \boldsymbol\theta=[a_0,a_1,\cdots,a_M]^T θ=[a0,a1,⋯,aM]T,
\qquad ϕ ( x ) = [ φ 0 ( x ) , φ 1 ( x ) , ⋯ , φ M ( x ) ] T \boldsymbol\phi(\boldsymbol x)=[\varphi_0(\boldsymbol x),\varphi_1(\boldsymbol x),\cdots,\varphi_M(\boldsymbol x)]^T ϕ(x)=[φ0(x),φ1(x),⋯,φM(x)]T
\qquad 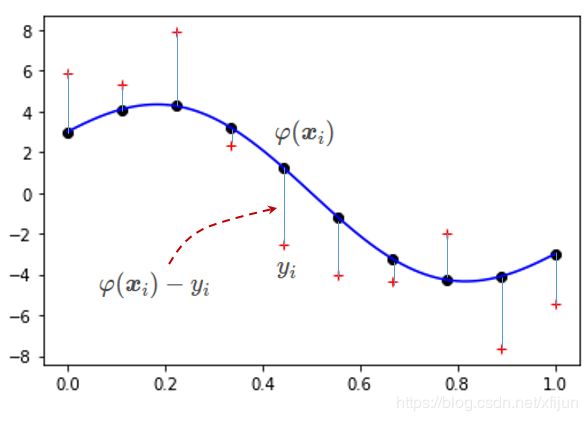
\qquad 上图中,线性模型关于每个观测点 ( x i , y i ) (\boldsymbol x_{i},y_{i}) (xi,yi) 的 ℓ 2 \ell_{2} ℓ2 损失(平方误差)为: [ φ ( x i ) − y i ] 2 [\varphi(\boldsymbol x_i)-y_i]^2 [φ(xi)−yi]2
\qquad 将“数据集所有观测点上的平方误差之和”设为损失函数 ( l o s s f u n c t i o n ) (loss\ function) (loss function):
\qquad\qquad J ( θ ) = [ φ ( x 0 ) − y 0 ] 2 + [ φ ( x 1 ) − y 1 ] 2 + ⋯ + [ φ ( x N ) − y N ] 2 = ∑ i = 0 N [ φ ( x i ) − y i ] 2 = ∑ i = 0 N [ θ T ϕ ( x i ) − y i ] 2 = ∥ Φ θ − y ∥ 2 2 \begin{aligned}J(\boldsymbol\theta)&=[\varphi(\boldsymbol x_0)-y_0]^2+[\varphi(\boldsymbol x_1)-y_1]^2+\cdots+[\varphi(\boldsymbol x_N)-y_N]^2\\ &=\displaystyle\sum_{i=0}^{N}[\varphi(\boldsymbol x_i)-y_i]^2\\ &=\displaystyle\sum_{i=0}^{N}[\boldsymbol \theta^T\boldsymbol\phi(\boldsymbol x_i)-y_i]^2\\ &=\parallel\Phi\boldsymbol\theta-\boldsymbol y \parallel_2^2\\ \end{aligned} J(θ)=[φ(x0)−y0]2+[φ(x1)−y1]2+⋯+[φ(xN)−yN]2=i=0∑N[φ(xi)−yi]2=i=0∑N[θTϕ(xi)−yi]2=∥Φθ−y∥22
\qquad 其中, y = [ y 0 , y 1 , ⋯ , y N ] T \boldsymbol y=[y_0,y_1,\cdots,y_N]^T y=[y0,y1,⋯,yN]T
\qquad Φ = [ ϕ ( x 0 ) T ϕ ( x 1 ) T ⋮ ϕ ( x N ) T ] = [ φ 0 ( x 0 ) φ 1 ( x 0 ) ⋯ φ M ( x 0 ) φ 0 ( x 1 ) φ 1 ( x 1 ) ⋯ φ M ( x 1 ) ⋮ ⋮ ⋮ φ 0 ( x N ) φ 1 ( x N ) ⋯ φ M ( x N ) ] \Phi=\left[\begin{matrix}\boldsymbol\phi(\boldsymbol x_0)^T\\ \boldsymbol\phi(\boldsymbol x_1)^T\\ \vdots\\ \boldsymbol\phi(\boldsymbol x_N)^T \end{matrix}\right]=\left[\begin{matrix}\varphi_0(\boldsymbol x_0)&\varphi_1(\boldsymbol x_0)&\cdots&\varphi_M(\boldsymbol x_0)\\ \varphi_0(\boldsymbol x_1)&\varphi_1(\boldsymbol x_1)&\cdots&\varphi_M(\boldsymbol x_1)\\ \vdots&\vdots&\ &\vdots \\ \varphi_0(\boldsymbol x_N)&\varphi_1(\boldsymbol x_N)&\cdots&\varphi_M(\boldsymbol x_N)\end{matrix}\right] Φ=⎣⎢⎢⎢⎡ϕ(x0)Tϕ(x1)T⋮ϕ(xN)T⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡φ0(x0)φ0(x1)⋮φ0(xN)φ1(x0)φ1(x1)⋮φ1(xN)⋯⋯ ⋯φM(x0)φM(x1)⋮φM(xN)⎦⎥⎥⎥⎤
\qquad
\qquad\qquad 这里的 Φ \Phi Φ 称为设计矩阵 ( d e s i g n m a t r i x ) (design\ matrix) (design matrix),其元素为 Φ n m = φ m ( x n ) \Phi_{nm}=\varphi_m(\boldsymbol x_n) Φnm=φm(xn)
\qquad
\qquad 损失函数 J ( θ ) J(\boldsymbol\theta) J(θ) 对系数 θ \boldsymbol\theta θ 求偏导:
\qquad\qquad ∂ J ( θ ) ∂ θ = 2 Φ T ( Φ θ − y ) = 0 \begin{aligned}\dfrac{\partial J(\boldsymbol\theta)}{\partial \boldsymbol\theta}&=2\Phi^T(\Phi\boldsymbol\theta-\boldsymbol y)=0 \end{aligned} ∂θ∂J(θ)=2ΦT(Φθ−y)=0
\qquad 可得到:
\qquad\qquad Φ T Φ θ = Φ T y ( 2 ) \Phi^T\Phi\boldsymbol\theta=\Phi^T\boldsymbol y\qquad\qquad\ \ \ \ \ \ \ (2) ΦTΦθ=ΦTy (2)
\qquad 显然,线性方程组(2)和(1)是等价的,可求得:
\qquad\qquad θ = ( Φ T Φ ) − 1 Φ T y ( 3 ) \boldsymbol\theta=(\Phi^T\Phi)^{-1}\Phi^T\boldsymbol y\qquad\qquad(3) θ=(ΦTΦ)−1ΦTy(3)
\qquad
最小二乘解的几何意义
\qquad 最小二乘解的几何意义如下图描述:

From 《PRML》Fig 3.2
\qquad 考虑线性方程组 Φ θ − y = 0 \Phi\boldsymbol\theta-\boldsymbol y=0 Φθ−y=0,可表示为:
\qquad\qquad [ φ 0 , φ 1 , φ 2 , ⋯ , φ M ] [ a 0 a 1 a 2 ⋮ a M ] = y [\boldsymbol\varphi_0,\boldsymbol\varphi_1,\boldsymbol\varphi_2,\cdots,\boldsymbol\varphi_M]\left[\begin{matrix}a_{0}\\ a_{1}\\ a_{2}\\ \vdots\\ a_{M}\\ \end{matrix}\right]=\boldsymbol y [φ0,φ1,φ2,⋯,φM]⎣⎢⎢⎢⎢⎢⎡a0a1a2⋮aM⎦⎥⎥⎥⎥⎥⎤=y
\qquad 其中, φ i = [ φ i ( x 0 ) , φ i ( x 1 ) , φ i ( x 2 ) , ⋯ , φ i ( x N ) ] T \boldsymbol\varphi_i=[\varphi_i(\boldsymbol x_0),\varphi_i(\boldsymbol x_1),\varphi_i(\boldsymbol x_2),\cdots,\varphi_i(\boldsymbol x_N)]^T φi=[φi(x0),φi(x1),φi(x2),⋯,φi(xN)]T
\qquad y = [ y 0 , y 1 , y 2 , ⋯ , y N ] T \boldsymbol y=[y_0,y_1,y_2,\cdots,y_N]^T y=[y0,y1,y2,⋯,yN]T
\qquad 图中的 S = C ( Φ ) \mathcal S=C(\Phi) S=C(Φ),表示矩阵 Φ = [ φ 0 , φ 1 , φ 2 , ⋯ , φ M ] \Phi=[\boldsymbol\varphi_0,\boldsymbol\varphi_1,\boldsymbol\varphi_2,\cdots,\boldsymbol\varphi_M] Φ=[φ0,φ1,φ2,⋯,φM] 的列空间 ( c o l u m n s p a c e ) (column\ space) (column space)。
- 如果 y ∈ S \boldsymbol y \in \mathcal S y∈S,线性方程组 Φ θ = y \Phi\boldsymbol\theta=\boldsymbol y Φθ=y 有唯一解
- 如果 y ∉ S \boldsymbol y\notin \mathcal S y∈/S,线性方程组 Φ θ = y \Phi\boldsymbol\theta=\boldsymbol y Φθ=y 无解,只能到 S \mathcal S S 中找一个最接近 y \boldsymbol y y 的解,最小二乘解是指图中的 y ^ \hat\boldsymbol y y^(在 ℓ 2 \ell_{2} ℓ2 范数下 ∥ y − y ^ ∥ 2 2 \parallel \boldsymbol y-\hat\boldsymbol y \parallel_{2}^{2} ∥y−y^∥22 的值最小, y ^ ∈ S \hat\boldsymbol y\in\mathcal S y^∈S)
4. 最小二乘法实现曲线拟合
4.1 线性回归(解方程组1)
\qquad 以比较简单的曲线拟合问题为例,如果我们对于函数 f ( x ) f(x) f(x) 的了解只有一个观测样本集 { ( x i , y i ) } ∣ 0 N \{(x_{i},y_{i})\}\big|_{0}^{N} {(xi,yi)}∣∣0N,如下图中绿色的 ‘+’ 所标记的这些数据点所示。

图1线性函数
\qquad 曲线拟合的目标是:基于这些观测数据 { x i , y i } ∣ 0 N \{x_{i},y_{i}\}\big|_{0}^{N} {xi,yi}∣∣0N,用最佳平方逼近的方式来估计真实函数 f ( x ) f(x) f(x) 的表达式,观测值满足 y i = f ( x i ) + ε i y_i=f(x_i)+\varepsilon_i yi=f(xi)+εi。
\qquad 令基函数为 φ n ( x ) = x n \varphi_{n}(x)=x^{n} φn(x)=xn,则多项式函数逼近为:
\qquad\qquad φ ( x ) = ∑ n = 0 M a n φ n ( x ) = a 0 + a 1 x + a 2 x 2 + ⋯ + a M x M \varphi(x)=\sum\limits_{n=0}^{M}a_{n}\varphi_{n}(x)=a_{0}+a_{1}x+a_{2}x^{2}+\cdots+a_{M}x^{M} φ(x)=n=0∑Manφn(x)=a0+a1x+a2x2+⋯+aMxM
\qquad 通过求出系数 ( a 0 , ⋯ , a M ) (a_{0},\cdots,a_{M}) (a0,⋯,aM) 的值,用 φ ( x ) ≈ f ( x ) \varphi(x)\approx f(x) φ(x)≈f(x),实际上就是计算: ( f , φ k ) = ∑ n = 0 M a n ( φ n , φ k ) (f,\varphi_{k})=\displaystyle\sum_{n=0}^{M}a_{n}(\varphi_{n},\varphi_{k}) (f,φk)=n=0∑Man(φn,φk)
\qquad 曲线拟合问题描述的是离散的情况。考虑图1中的线性拟合问题,只需要计算两个系数 a 0 a_0 a0 和 a 1 a_1 a1,近似函数 φ ( x ) = a 0 φ 0 ( x ) + a 1 φ 1 ( x ) = a 0 + a 1 x \varphi(x)=a_{0}\varphi_{0}(x)+a_{1}\varphi_{1}(x)=a_{0}+a_{1}x φ(x)=a0φ0(x)+a1φ1(x)=a0+a1x。
\qquad 也就是计算线性方程组的未知数 a 0 a_0 a0 和 a 1 a_1 a1:
\qquad\qquad [ ( φ 0 , φ 0 ) ( φ 1 , φ 0 ) ( φ 0 , φ 1 ) ( φ 1 , φ 1 ) ] [ a 0 a 1 ] = [ ( f , φ 0 ) ( f , φ 1 ) ] \left[\begin{matrix}(\varphi_{0},\varphi_{0})&(\varphi_{1},\varphi_{0})\\ (\varphi_{0},\varphi_{1})&(\varphi_{1},\varphi_{1})\\ \end{matrix}\right] \left[\begin{matrix}a_{0}\\ a_{1}\\ \end{matrix}\right]=\left[\begin{matrix}(f,\varphi_{0})\\ (f,\varphi_{1})\\ \end{matrix}\right] [(φ0,φ0)(φ0,φ1)(φ1,φ0)(φ1,φ1)][a0a1]=[(f,φ0)(f,φ1)]
\qquad 其中, φ 0 ( x ) = 1 \varphi_{0}(x)=1 φ0(x)=1, φ 1 ( x ) = x \varphi_{1}(x)=x φ1(x)=x。
\qquad 对于观测样本集 { ( x i , y i ) } ∣ 0 N \{(x_{i},y_{i})\}\big|_{0}^{N} {(xi,yi)}∣∣0N,离散形式的内积为:
\qquad\qquad ( f , φ k ) = ∑ i = 0 N y i φ k ( x i ) = { ∑ i = 0 N y i ( k = 0 ) ∑ i = 0 N y i x i ( k = 1 ) (f,\varphi_{k})=\displaystyle\sum_{i=0}^{N}y_i\varphi_{k}(x_i)=\begin{cases}\displaystyle\sum_{i=0}^{N}y_i &(k=0)\\ \displaystyle\sum_{i=0}^{N}y_ix_i &(k=1)\end{cases} (f,φk)=i=0∑Nyiφk(xi)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧i=0∑Nyii=0∑Nyixi(k=0)(k=1)
\qquad\qquad ( φ n , φ k ) = ∑ i = 0 N φ n ( x i ) φ k ( x i ) = { ∑ i = 0 N 1 ( n = 0 , k = 0 ) ∑ i = 0 N x i ( n = 0 , k = 1 ) ∑ i = 0 N x i ( n = 1 , k = 0 ) ∑ i = 0 N x i 2 ( n = 1 , k = 1 ) (\varphi_{n},\varphi_{k})=\displaystyle\sum_{i=0}^{N}\varphi_{n}(x_i)\varphi_{k}(x_i)=\left\{\begin{matrix}\displaystyle\sum_{i=0}^{N}1 &(n=0,k=0)\\ \displaystyle\sum_{i=0}^{N}x_i &(n=0,k=1)\\ \displaystyle\sum_{i=0}^{N}x_i &(n=1,k=0)\\ \displaystyle\sum_{i=0}^{N}x_i^2 &(n=1,k=1)\end{matrix}\right. (φn,φk)=i=0∑Nφn(xi)φk(xi)=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧i=0∑N1i=0∑Nxii=0∑Nxii=0∑Nxi2(n=0,k=0)(n=0,k=1)(n=1,k=0)(n=1,k=1)
\qquad 因此,线性方程组为(和第2节中的过程一样):
\qquad\qquad [ ∑ i = 0 N 1 ∑ i = 0 N x i ∑ i = 0 N x i ∑ i = 0 N x i 2 ] [ a 0 a 1 ] = [ ∑ i = 0 N y i ∑ i = 0 N y i x i ] \left[\begin{matrix}\sum\limits_{i=0}^{N}1&\sum\limits_{i=0}^{N}x_i\\ \sum\limits_{i=0}^{N}x_i&\sum\limits_{i=0}^{N}x_i^2\\ \end{matrix}\right] \left[\begin{matrix}a_{0}\\ a_{1}\\ \end{matrix}\right]=\left[\begin{matrix}\sum\limits_{i=0}^{N}y_i\\ \sum\limits_{i=0}^{N}y_ix_i\\ \end{matrix}\right] ⎣⎢⎢⎡i=0∑N1i=0∑Nxii=0∑Nxii=0∑Nxi2⎦⎥⎥⎤[a0a1]=⎣⎢⎢⎡i=0∑Nyii=0∑Nyixi⎦⎥⎥⎤
代码实现
import numpy as np
import matplotlib.pyplot as plt
def gen_lineardata(a,b,x):
y = a*x + b
y_noise = y + np.random.randn(len(x))*30
return y, y_noise
def linear_regression(y_noise,x):
a11 = len(x)
a12 = np.sum(x)
a22 = np.sum(np.power(x,2))
f1 = np.sum(y_noise)
f2 = np.sum(y_noise*x)
coef = np.dot(np.linalg.inv(np.array([[a11,a12],[a12,a22]])),np.array([f1,f2]))
return coef
if __name__ == '__main__':
x = np.linspace(0,20,200)
a = int(np.random.rand()*10)+1
b = int(np.random.rand()*20)+1
y, y_noise = gen_lineardata(a,b,x)
plt.plot(x,y,'b')
plt.plot(x,y_noise,'g+')
coef = linear_regression(y_noise,x)
a1 = coef[1]
b1 = coef[0]
print(coef)
y1,y2 = gen_lineardata(a1,b1,x)
plt.plot(x,y1,'r')
plt.legend(labels=['original data','noise data','least-squares'],loc='upper left')
plt.title('y='+str(a)+'x +'+str(b))
plt.show()
某一次的实现结果:b=11.38812346, a=6.59033571(真实值为b=10,a=7)

\qquad 线性回归的实现也可以采用解方程组(2)的方式(M=1):
def linear_regression_approx(y_noise,x,M):
design_matrix = np.asmatrix(np.ones(len(x))).T
for i in range(1,M+1):
arr = np.asmatrix(np.power(x,i)).T
design_matrix = np.concatenate((design_matrix ,arr),axis=1)
coef = (design_matrix.T*design_matrix).I*(design_matrix.T*(np.asmatrix(y_noise).T))
return np.asarray(coef)
\qquad
4.2 周期函数的逼近(解方程组2)
\qquad 针对具有周期性质的数据集,更适合采用三角函数作为基函数,即采用公式:
\qquad\qquad φ ( x ) = a 0 + a 1 cos x + b 1 sin x + ⋯ + a M cos ( M x ) + b M sin ( M x ) \varphi(x)=a_{0}+a_{1}\cos x+b_{1}\sin x+\cdots+a_{M}\cos (Mx)+b_{M}\sin (Mx) φ(x)=a0+a1cosx+b1sinx+⋯+aMcos(Mx)+bMsin(Mx)
\qquad 根据公式(3)求出系数。
import numpy as np
import matplotlib.pyplot as plt
def gen_data(x):
y = 2*np.sin(2*np.pi*x) + 3*np.cos(3*np.pi*x)
y_noise = y + np.random.randn(len(x))
return y, y_noise
def least_squares_approx(y_noise,x,M):
design_matrix = np.asmatrix(np.ones(len(x))).T
for i in range(1,M+1):
arr_sin = np.asmatrix(np.sin(i*x)).T
design_matrix = np.concatenate((design_matrix ,arr_sin),axis=1)
arr_cos = np.asmatrix(np.cos(i*x)).T
design_matrix = np.concatenate((design_matrix ,arr_cos),axis=1)
coef = (design_matrix.T*design_matrix).I*(design_matrix.T*(np.asmatrix(y_noise).T))
return np.asarray(coef)
def approx_plot(coef,x,M):
y = np.ones(len(x))*coef[0,0]
for i in range(1,M+1):
y = y + np.sin(i*x)*coef[2*i-1,0] + np.cos(i*x)*coef[2*i,0]
plt.plot(x,y,'r')
if __name__ == '__main__':
x = np.linspace(0,4,100)
y, y_noise = gen_data(x)
plt.plot(x,y,'b')
plt.plot(x,y_noise,'g+')
M = 8
coef = least_squares_approx(y_noise,x,M)
approx_plot(coef,x,M)
plt.legend(labels=['original data','noise data','least square'],loc='upper left')
plt.title('$y=2\sin(2\pi x)+3\cos(3\pi x)$')
plt.show()
运行结果:

注:本文并未深入考虑线性方程组(1)和(2)的左端系数矩阵是否可逆的问题,只是实现了通过求解析解来求出系数;在观测数据集非常庞大的时候,求解析解的方式难以实现,需要采用梯度下降法之类的最优化算法来求取近似解。