聊聊C语言和ABAP
这个公众号之前的文章,分享的都是Jerry和SAP成都研究院的同事在工作中学到的一些知识和感受。而今天这篇文章,写作的由来是因为最近我又参与了SAP成都数字创新空间应聘者的面试,和一些朋友聊了一些关于用不同的编程语言写Hello World程序的话题,突然才发现,自己从2007年毕业之后,再没有使用过C语言进行编程了。因此想做一个简单的回忆。对C语言不感兴趣的ABAP开发顾问,可以直接跳到本文讲ABAP的章节。

为什么这篇文章要把C语言和ABAP放在一起讲,而不是别的语言比如Java和ABAP呢?因为ABAP语言底层是基于C/C++实现的,包括其关键字(比如最简单的关键字WRITE的C++实现有2千多行)和虚拟机(ABAP Runtime)。SAP内部的一群计算机科学家们发明了ABAP这门伟大的语言,由它实现的各种SAP应用帮助了全球超过180个国家和地区的客户们更好地运行其业务。
通过Google我们能搜索到一些关于这些SAP计算机科学家们的介绍,比如这个链接:
http://sapexperts.wispubs.com/SAP-Professional-Journal/Articles/From-XML-to-ABAP-Data-Structures-and-Back-Bridging-the-Gap-with-XSLT?id=2CA6B036062F42C5B7A76A772A934911#.WmGiiaiWbdM

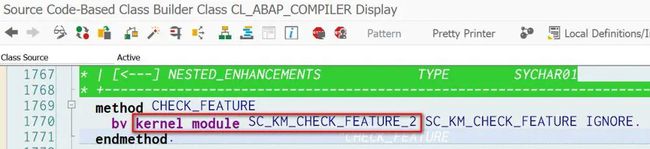
比如像下图这种用kernel module修饰的sc_km_check_feature_2, 以及每一个ABAP关键字,其C语言的实现代码在SAP内部的Netweaver系统可以查看到,但是在客户系统上,则是以二进制目标文件的形式存储,无法查看源代码。
本文的目的是希望通过C语言和ABAP编译过程的一些介绍,加深ABAP顾问们对这门语言的理解。
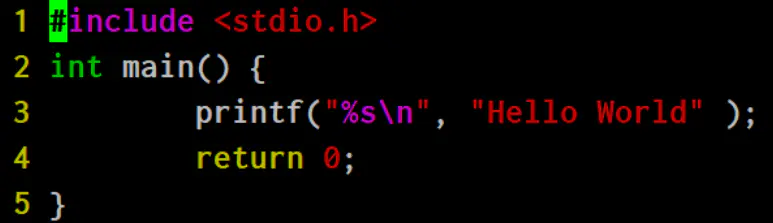
用C语言写个Hello World程序,另存为study.c:
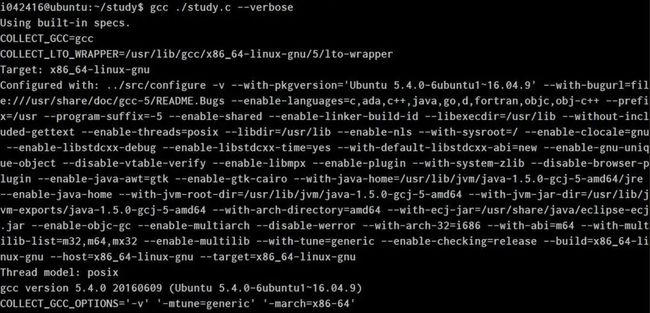
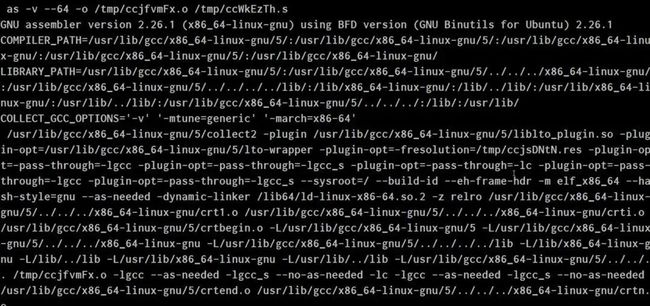
用命令行gcc ./study.c --verbose进行编译,参数verbose可供我们查看编译明细。上述命令行在我的Ubuntu系统上产生一串长长的输出:
我们可以一步步分析。首先用参数 -E查看预处理生成的目标文件study.i:
gcc -E study.c -o study.i
可以看到源代码文件只有78字节,编译预处理后生成的输出文件有17116字节。

为什么膨胀了这么多?原因是因为我源代码文件的第一行,#include
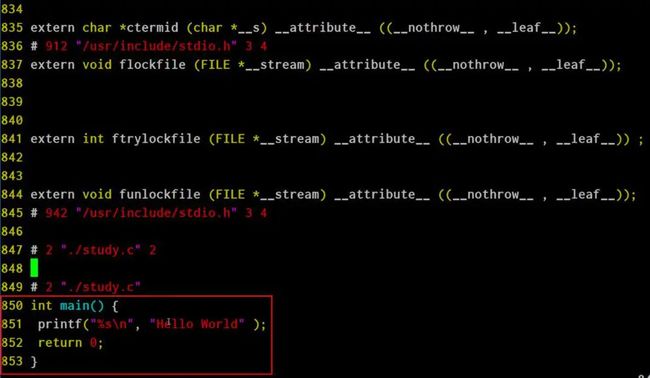
源代码文件study.c里的第一行语句 #include
用命令行gcc -S可以查看study.c编译后生成的汇编代码:
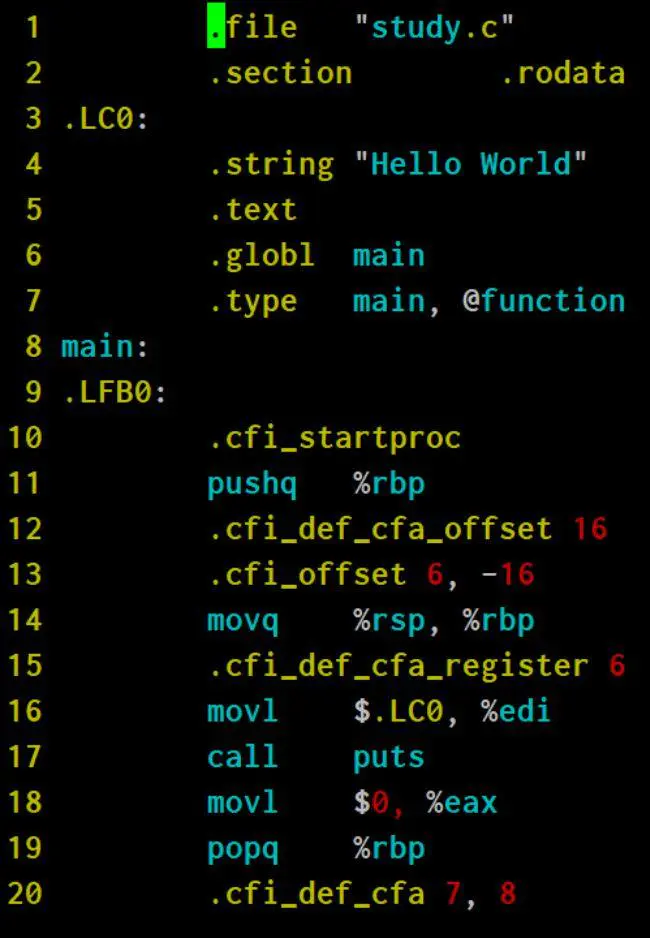
看到这些pushq, popq, %rbp,Jerry不由得想起本科汇编程序设计专业课上,我和寝室其他兄弟坐在教室最后一排看体坛周报的时光。
工作十多年后,Jerry不得不承认,当时本科开设的计算机专业课,像数据结构,操作系统,计算机组成原理,编译原理,汇编程序设计,计算机图形学这些都是有用的,工作后,公司不可能再给你时间去学习这些基础理论知识了。
虽然汇编程序设计这门课Jerry当初没有好好学,但至少教材我是妥善保存了的,以防哪天公司的工作安排需要让我把十多年前在学校学的东西重新又捡起来。

下面我们来聊聊ABAP。

SAP note 1230076 ”Generation of ABAP loads: Tips for the analysis” 介绍了一个工具程序:RSDEPEND。这个note提到,一个即便看起来最简单的ABAP Hello World报表,其实也依赖于许多标准的Repository对象,这些依赖我们假定称其为A,B,C。假设A,B,C其中有任何一个有改动产生,比如A是一个include程序,里面使用到了一个DDIC结构,在某个时刻,系统导入了一个传输请求(Transport Request), 里面包含了针对这个DDIC结构的更改,那么此时这个最简单的Hello World报表的load就成为了obsolete状态。在重新执行该报表之前,ABAP Runtime(中文译成ABAP运行时)会自动做一个load invalidation操作,生成一个最新版本的load。
什么是ABAP load?看ABAP help里的官方定义:
“In the ABAP environment, a load describes a binary representation of a repository object which is optimized for fast access, in the memory or on the database.”
翻译成中文:ABAP load是Repository对象的二进制表现形式,针对ABAP环境的快速访问而做过特别优化,可以存储在数据库表中或者加载于内存里。
我们用一个实际的例子来理解ABAP报表激活和运行时发生的事情。
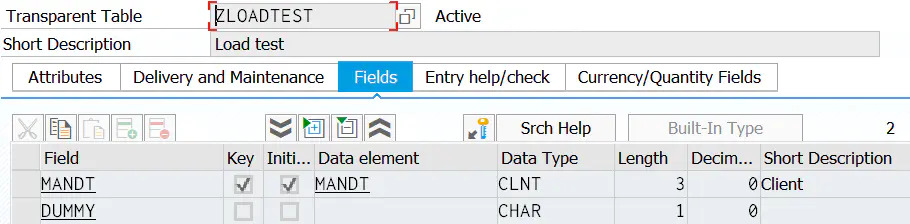
创建一张非常简单的透明表ZLOADTEST:
写一个简单的报表,命名为ZTESTLOAD。报表的源代码以压缩的格式存储在表REPOSRC的DATA字段里。

测试报表的源代码很简单,把表里的数据全部读取出来:

激活这个简单的报表(是的,在ABAP世界里,我们习惯说激活,而不是编译)。激活后生成的ABAP load存储在表REPOLOAD的字段LDATA和QDATA里。
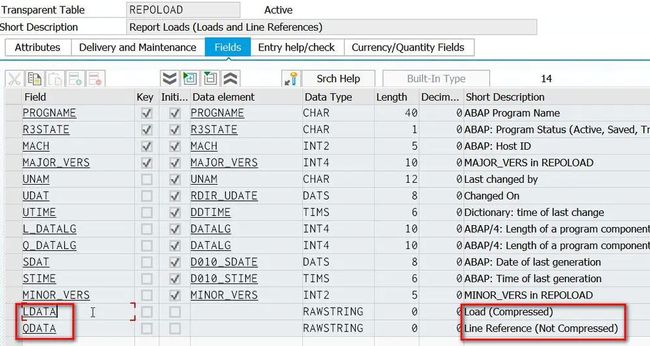
这两个字段存储的内容就是前面ABAP help提到的ABAP load在数据库表中的存储形式。
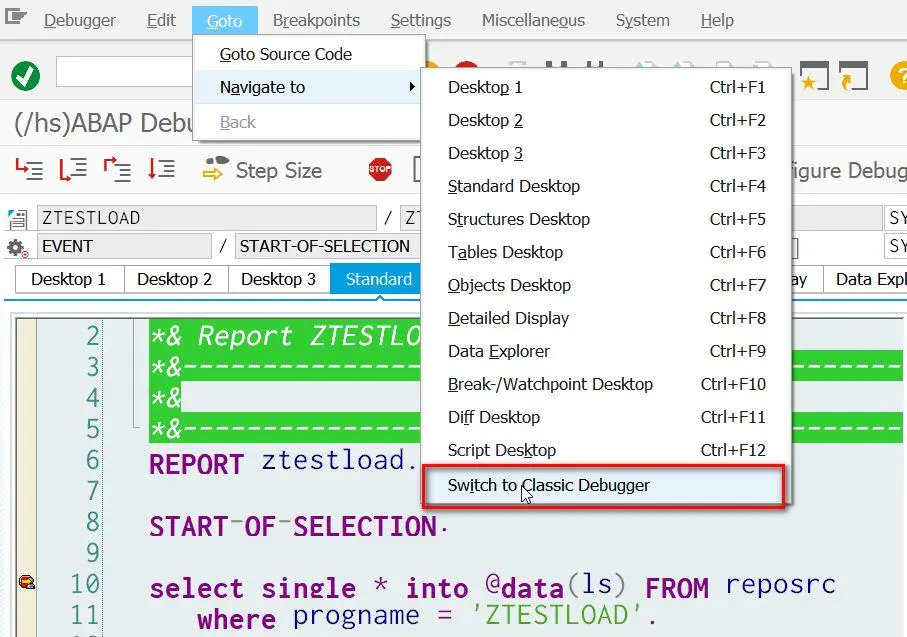
菜单Goto->Navigate to->Switch to Classic Debugger:
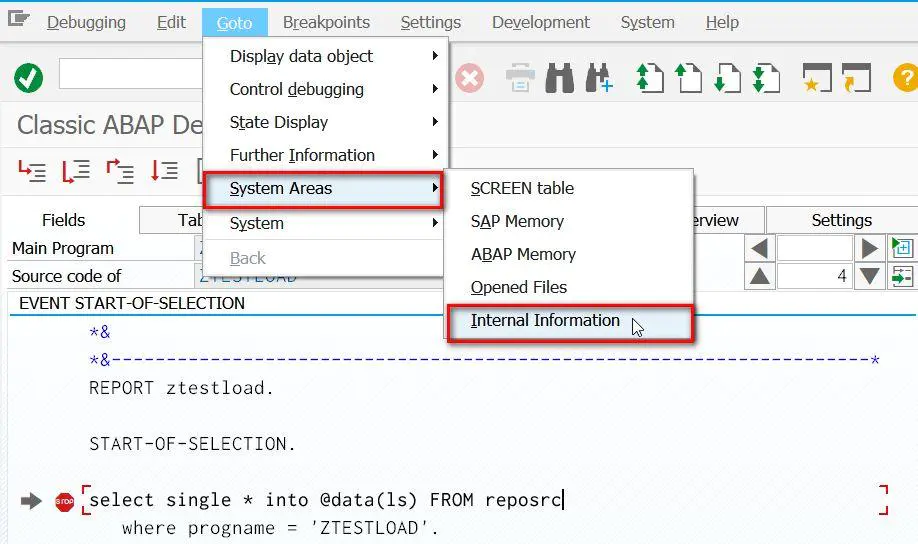
Goto->System Areas->Internal Information:
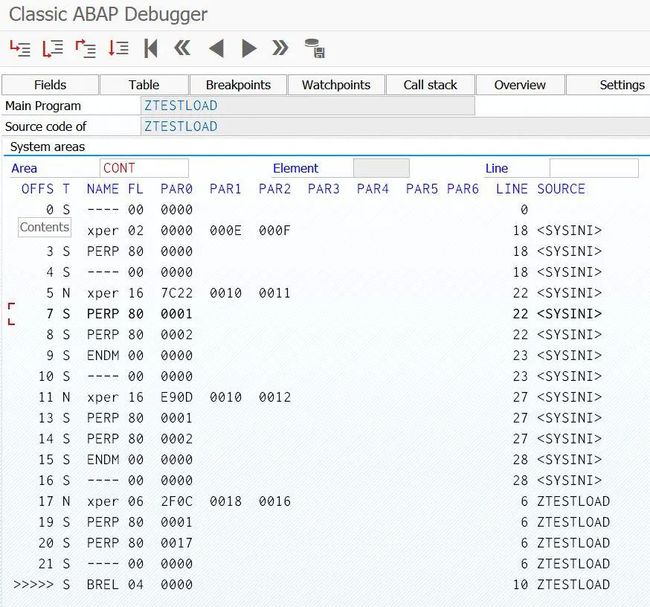
在System Area区域输入CONT,就能在下图的NAME列看到ABAP load里包含的指令。当然同开源的JVM不同,JVM字节码指令集在网上能够查到,而这些ABAP load的指令是SAP internal的,因此不能在这里做解释。
然后执行前面提到的工具报表RSDEPEND, 输入参数program name = ZTESTLOAD, 得到结果,其中测试报表的ABAP Load时间戳为07:21:02, 这个报表依赖的标准Include有:
-
-
-
-
DB__SSEL
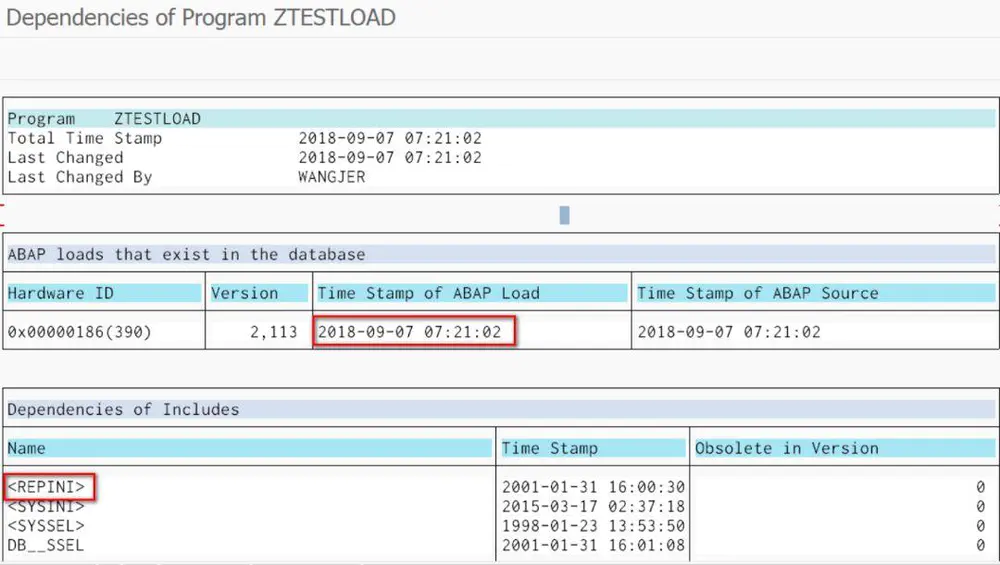
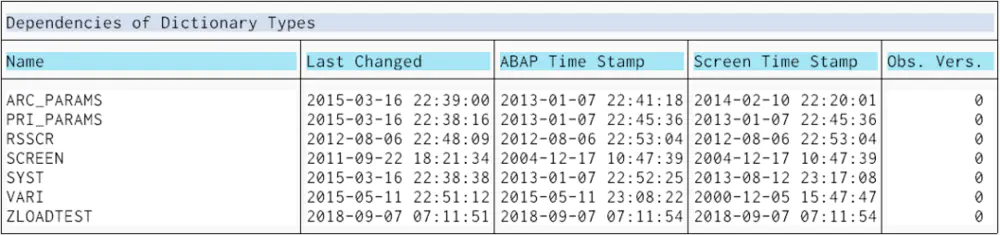
由此看出,每一个标准的ABAP报表都自动包含了这些include。如果开发人员显式地再包含其中任意一个,会遇到语法错误: Module %_PF_STATUS is already defined as a OUTPUT module .
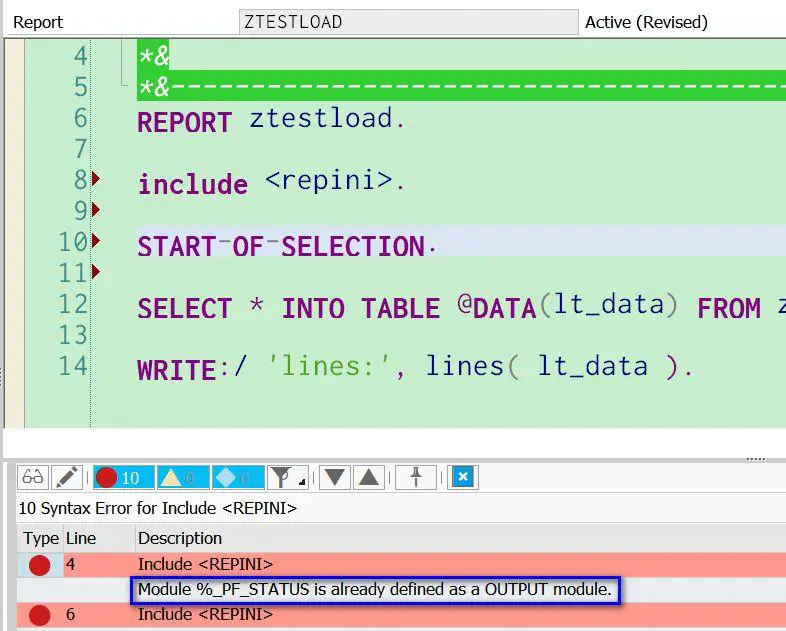
大家觉得这个
下面我们再做几轮测试。
测试1
修改透明表的描述信息,然后重新激活透明表。
执行RSDEPEND, 可以看到只有透明表的Last Changed字段发生了变化,ABAP Time Stamp和Screen Time Stamp都不变,这是我们期望的结果,因为我们只是修改了透明表的描述信息,并未修改结构。
再次执行测试报表ZTESTLOAD, 用RSDEPEND检测,发现测试报表的ABAP Load时间戳没有发生变化,这说明:即使依赖的透明表的描述信息发生变化,使用了该透明表的ABAP报表不需要重新编译,因为透明表描述信息不需要在报表执行期使用。
测试2
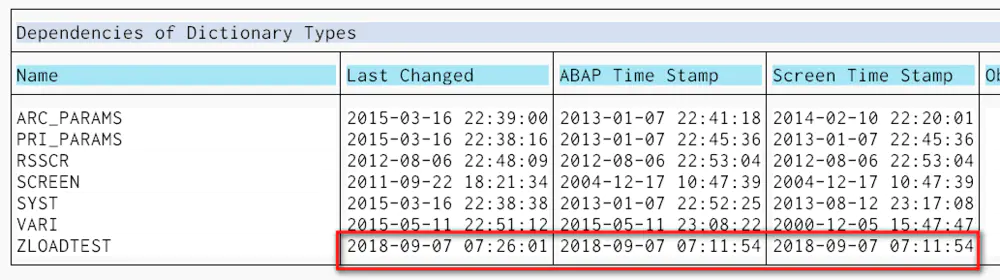
给透明表增加新的一列,再次激活。
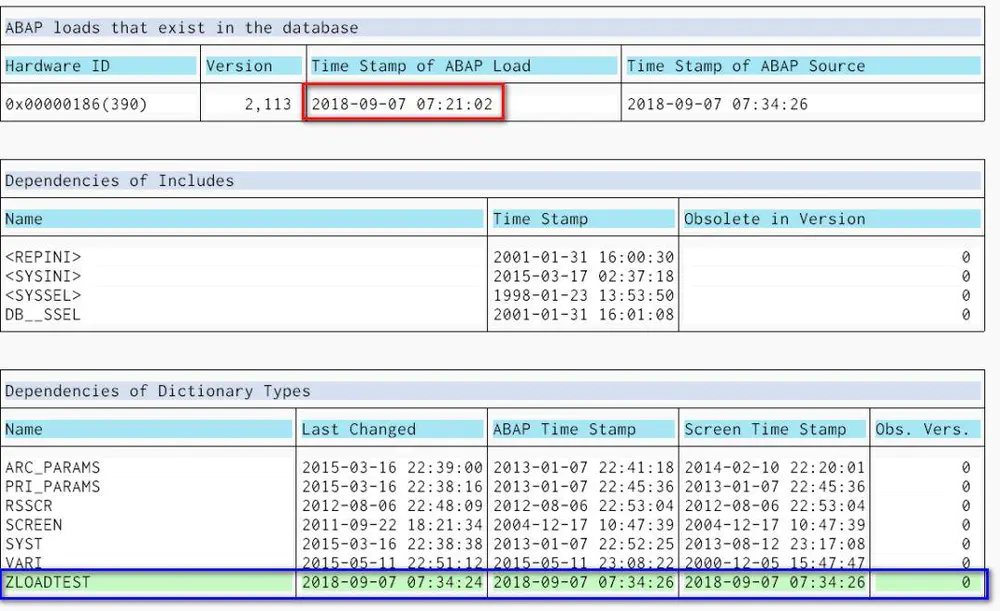
此时通过RSDEPEND发现,透明表的三个时间戳全部发生了变化,如下图蓝色矩形框所示。然而测试报表ABAP Load本身的时间戳仍然未变,这也是合理的,因为我们给透明表里增加了新的列后,还未执行测试报表。
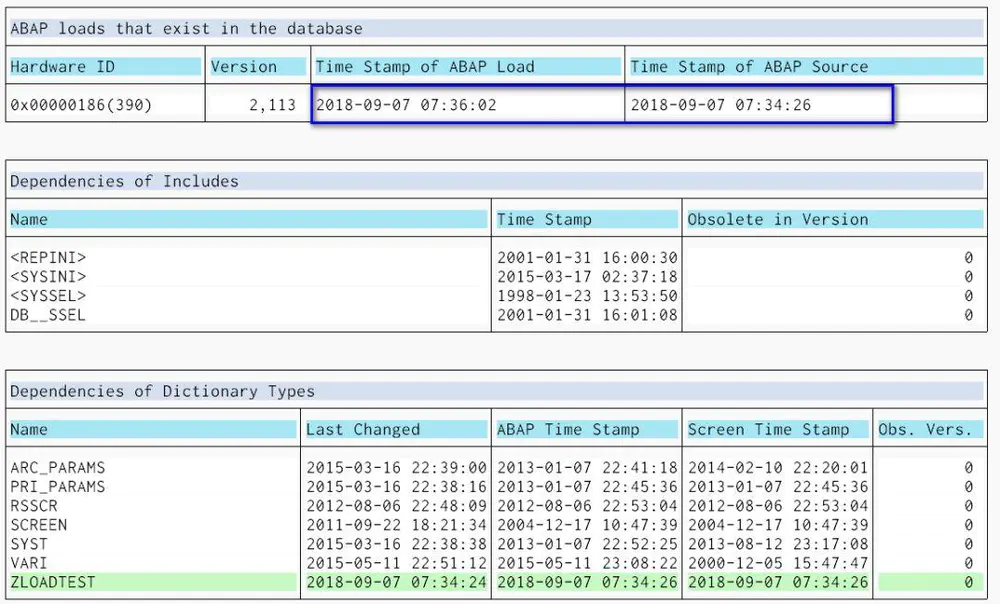
再次执行ZTESTLOAD后,这次发现它的ABAP Load已经被自动invalidate了,时间戳从07:21:02变成了07:36:02。
这也解释了一个现象:有的朋友们观察到,当系统刚升完级后,或者有一批新的传输请求导入到系统后,第一次使用SAP应用时,系统响应速度很慢。原因其实通过前文的两个测试已经说明了:系统在花费时间去做相关ABAP Load invalidation。在应用依赖的这些Load invalidation没有结束之前,系统无法响应用户请求。
为了避免用户在第一次使用应用时长时间等待,可以使用事务码SGEN预先进行Load invalidation。SGEN详细的使用方法可以参考下面这篇 文章
希望这篇文章能给那些想了解ABAP语言底层一些实现细节的顾问朋友们有所帮助。
更多阅读
-
阿里云上到底能运行SAP哪些产品?
-
ABAP vs Java,蛙泳 vs 自由泳
-
Jerry的ABAP原创技术文章合集
-
Jerry的ABAP, Java和JavaScript乱炖
-
ABAP开发人员未来应该学些什么
-
300行ABAP代码实现一个最简单的区块链原型
-
Jerry 2017年的五一小长假:8种经典排序算法的ABAP实现
要获取更多Jerry的原创文章,请关注公众号"汪子熙":

来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/24475491/viewspace-2215013/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/24475491/viewspace-2215013/