Phoenix Secondary Index
1. Phoenix 二级索引
在HBase中只有rowkey创建了索引,通过列值访问数据时,必须要scan全表然后进行filter得出自己的结果.如果某列有了二级索引,那么通过该列可以快速的定位数据而不需要scan全表.在Phoenix中,一旦找到索引entry后,就不需要在访问主表了(backup lookup),因为它将索引的数据以及感兴趣的数据直接放在index row中(通过include).Phoenix中的 index 分为两种:mutable index,immutable index.
Mutable Indexing:
通常,插入的一行数据并不是一成不变的,他可能会在任何时间被修改,mutable index就是保证数据被修改之后,该数据的索引也会做出正确的修改.索引对性能的影响发生在数据写入阶段.Phoenix在write阶段获取数据更新信息,创建索引更新信息,然后将索引更新信息运用到对应的index table上.在读数据阶段,Phoenix会自动选择index table来降低查询时间.
Example:
CREATE TABLE my_table (k VARCHAR PRIMARY KEY, v1 VARCHAR, v2 BIGINT);
CREATE INDEX my_index ON my_table (v1);
[Note] 一个table可以根据自己的列创建任意数量的index,但是,随着index的增多,写入性能会慢慢的降低.
通过include字段将你需要获取但是不好建立索引的数据添加到index中,这样可以直接通过index获取所需要的数据而不用backup lookup primary table.而且可以避免多index造成的写性能丢失.
CREATE INDEX my_index ON my_table (v2 DESC, v1) INCLUDE (v3) SALT_BUCKETS=10, DATA_BLOCK_ENCODING='NONE';
immutable indexing用于表里的数据不会被更新的场景.在这个case下,客户端管理index,要么成功写入主表数据与index数据,要么返回失败到client.一旦写入成功,数据不会变更,index数据也不需变更,也不能动态增加index,建表语句:
CREATE TABLE IF NOT EXISTS $table (HOST CHAR(2) NOT NULL,DOMAIN VARCHAR NOT NULL,FEATURE VARCHAR NOT NULL,DATE DATE NOT NULL,USAGE.CORE BIGINT,USAGE.DB BIGINT,STATS.ACTIVE_VISITOR INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)) IMMUTABLE_ROWS=true,MAX_FILESIZE=30485760;
Example:
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
在上述的第三条语句中,使用了SALT_BUCKETS, DATA_BLOCK_ENCODING,如同在创建主表时为主表添加properties一样,也可以为index添加properties.这里的SALT_BUCKETS主要是解决region Hotspotting的问题,由于rowkey设计不当,很可能绝大部分的row都会落入一个region中,那么其对应index通过设置SALT_BUCKETS[1~255]来将这些index分桶存储.
[Note] 如果主表添加了properties,那么它的index会继承这些properties.不过, index的 MAX_FILESIZE相对主表的值被降低了.
Immutable Indexing:
immutable indexing用于表里的数据不会被更新的场景.在这个case下,客户端管理index,要么成功写入主表数据与index数据,要么返回失败到client.一旦写入成功,数据不会变更,index数据也不需变更,也不能动态增加index,建表语句:
CREATE TABLE IF NOT EXISTS $table (HOST CHAR(2) NOT NULL,DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,DATE DATE NOT NULL,USAGE.CORE BIGINT,USAGE.DB BIGINT,STATS.ACTIVE_VISITOR
INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)) IMMUTABLE_ROWS=true,MAX_FILESIZE=30485760;
2.数据保证与失败恢复机制
如果client收到successful,主表数据与索引数据会被确保是写成功的.对于一行数据,实际及索引数据更新是要么都成功,要么什么没发生的操作.通过将index update信息添加到主表的WAL中来保证index update的持久性.只有index update 添加到WAL中成功后,才会执行 index/primary table的更新操作.默认地,index updates是被并行执行的,这就导致了服务器的高吞吐量.如果正在index update时regionserver宕机,通过重放写在主表WAL中的index update日志信息来保证数据一致性.因此,index table的操作都是先于primary table的.
[Note]
-
Phoenix没有提供事务支持,所以可以在主表数据更新之前看到index update结果
-
每一行的数据与其对应的index row都被保证是要么都写成功,要么都失败,不会部分写成功.
-
index数据先写入index table,然后再将实际数据写入primary table
Singular Write Path:
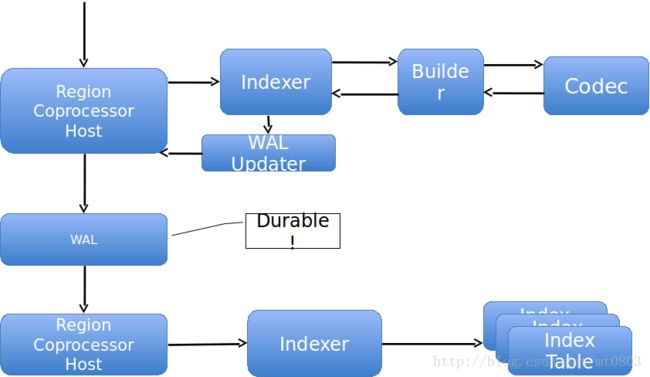
所有对Region的writes都会被coprocessor截取,然后构建index updates,接着index update写入WAL中.如果在这个点发生failure,client会收到failure,并且不会看到任何持久化的数据.一旦index update写入了WAL,Phoenix就会保证 index table和primary table的数据都能可见,即使是发生了failure. 如何保证,主要是看Phoenix的恢复策略.
Failure Policy:
Failure Situations:
-
Any time before WAL, client replay
-
Any time after WAL, HBase replay
- All-or-nothing

核心就是三句话:以index updates写入WAL为边界,在边界之前,没有数据进入HBase,那么此时failure了,client进行replay;在边界之后,也就是index updates写入了WAL后发生failure,需要HBase WAL replay;最后还有一点就是保证data updates和index updates要么都写成功,要么什么都没发生,决不能出现部分成功!
最麻烦的一部分是HBase replay.在RegionServer处理data updates时,如果它的index updates不能够被写入RegionServer,那么index首先会被自动的disable掉,在查询时,它将不会被考虑了.如果需要继续使用该index, 需要手动的执行:
ALTER INDEX my_index ON my_table REBUILD;
但是,实际中如果Phoenix不能disable该index的话,RegionServer将会立即异常结束(aborted).如果abort失败,会执行System.exit推出JVM,强制RS死亡.通过杀死RS,来replay WAL.
通过上面的步骤,会发现一个极端严重的问题:indexing有使得hbase cluster迅速挂掉的潜在威胁.因为在index updates replay到另外一个RS时,在这个RS操作出现了和down掉的RS一样的情况,那么index updates会继续replay到其他存活的RS,那么这个failure policy可能会串联的down掉所有的RS.
[Note]: mutable indexing需要一个特殊的配置,而且mutabl indexing只能用在HBase-0.94.10版本以上(0.94.8版本测试时,报出的错误发现的).
针对不同的集群环境,Phoenix针对二级索引还有几个参数可以进行对应的调优.
-
index.builder.threads.max
-
根据primary table update建立index update的线程数目
-
调高这个值可以克服读取row state的瓶颈,如果调的太高,HRegion又会遇到处理scan requests的瓶颈,已经general thread-swapping concerns.
-
Default:10
-
-
index.builder.threads.keepalivetime
-
index builder线程池里的thread expire之后,存活的时间
-
超过这个存活时间,unused thread会立马被释放,core threads是不会被保留的.如果从load角度考虑,是可以手动去释放threads
-
Default:60
-
-
index.write.threads.max
-
将index update写入index table的线程数目
-
应该大致对应index table的数目
-
Default:10
-
-
index.write.threads.keepalivetime
-
Description 大致同第二个
-
Default:10
-
-
hbase.htable.threads.max
-
index table可以使用的写线程最大数目
-
增加这个值会提高index update的并发量,提升全局吞吐
-
Default:2147483647
-
-
hbase.htable.threads.keepalivetime
-
Description 大致同第二个
-
Default:60
-
-
index.tablefactory.cache.size
-
放入缓存的index HTable数量
-
增加这个值,可以确保写index时不需要重新创建index HTable,但是值越大,memory压力越大.
-
Default:10
-
创建表:
CREATE TABLE IF NOT EXISTS $table (HOST CHAR(2) NOT NULL,DOMAIN VARCHAR NOT NULL,FEATURE VARCHAR NOT NULL,DATE DATE NOT NULL,USAGE.CORE
BIGINT,USAGE.DB BIGINT,STATS.ACTIVE_VISITOR INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)) IMMUTABLE_ROWS=true,MAX_FILESIZE=30485760;
即表的列为:HOST, DOMAIN, FEATURE, DATE, CORE, DB, ACTIVE_VISITOR
CORE值 ( 0 - 500 ) DB值 ( 0 - 2000 ) ACTIVE_VISITOR值 ( 0 - 10000)
在表没有建立索引,CORE列建立索引,CORE,DB列建立索引,CORE,DB,ACTIVE_VISITOR建立索引的case下分别导入3000万条数据,然后执行查询语句.具体性能如下:
语句A: SELECT COUNT(1) FROM $table WHERE CORE<100
从图中可以看到,建立索引后,语句平均执行时间在 5 sec 左右, 没有建立core索引时,语句执行时间在 20 sec左右.语句B: SELECT COUNT(1) FROM $table WHERE DB>500
从图中可以看到,建立索引后,语句平均执行时间在 14 sec 左右, 没有建立core索引时,语句执行时间在 33 sec左右语句C:SELECT COUNT(1) FROM $table WHERE CORE<100 AND DB>500
从图中可以看到,随着core,db索引的建立,查询时间逐步降低语句D: SELECT COUNT(1) FROM $table WHERE CORE<100 AND DB>500 OR ACTIVE_VISITOR<3000
从图中可以看到,core, db, active_visitor都建立索引后,查询时间降到最低.-
Phoenix-2.1版本支持mutable,immutable index,但是常用的mutable index在hbase-0.94.10以上版本才能使用,这个是在测试时发现.
-
从测试结果可以看出,虽然建立索引后的查询效率提升很多,但是要注意建立索引越多对写入性能的影响越大.
-
Phoenix-2.1版本支持建表时与HBase中的表对应起来,这样可以直接通过Phoenix的Sql语句来访问和插入数据,而不再使用HBase API.
- 建立Phoenix表与HBase里的表对应时,建Phoenix表的列时,数据类型一般声明成varchar,这样可直接正确读取出数据.声明其他类型,会有问题.
例如: hbase> scan 'testtable3'
ROW COLUMN+CELL
row1 column=info:c1, timestamp=1383728042793, value=1
row2 column=info:c1, timestamp=1383728044552, value=2
row3 column=info:c1, timestamp=1383728047009, value=3
phoenix> create table "testtable3" (ROW varchar not null primary key, "info"."c1"
integer);
select * from "testtable3";
+------------+------+
| ROW | c1 |
+------------+------+
| row1 | -1320878080 |
| row2 | -1304100864 |
java.lang.ArrayIndexOutOfBoundsException: 210 (出现解码问题)
如果建表语句为:create table "testtable3" (ROW varchar not null primary key, "info"."c1" varchar ); 就不会有问题了 - 大小写问题.
比如 phoenix > create table testtable ….
在HBase里对应建立的表明为 TESTTABLE,他会自动转为大写的.如果你要对应
HBase里已有的testtable,那就会失败.如果要正确去对应,需要写成
create table "testtable" ….,即添加一个双引号就变成大小写敏感了.同理,
phoenix表要对应 HBase里的表 testtable 的列 info:c1,必须写成
phoenix > create table "testtable" ….("info"."c1" varchar)... - create index test_idx on testtable (c1) include (c2) 这里的include理解:
如果直接执行: create index test_idx on testtable (c1) ,在HBase里形成的index
table如下: > scan ‘TEST_IDX’
ROW COLUMN+CELL
\xC1\x06\x00row4 column=_0:_0, timestamp=1383732128959, value=
\xC1\x06\x00row5 column=_0:_0, timestamp=1383732128959, value=
如果执行:create index test_idx on testtable (c1) include(c2),在HBase里形成的index
table如下: > scan ‘TEST_IDX’
ROW COLUMN+CELL
\xC1\x06\x00row4 column=info:_0, timestamp=1383732393752, value=
\xC1\x06\x00row4 column=info:info:C2, timestamp=1383732393752,
value=\x80\x00\x00\x06
\xC1\x06\x00row5 column=info:_0, timestamp=1383732393752, value=
\xC1\x06\x00row5 column=info:info:C2, timestamp=1383732393752,
value=\x80\x00\x00\x06
通过比较发现,include是把c2这一列的数据写入了index table中.原因:有些列需要经常访问,但是又不适合建索引,如果通过其他的inde获取具体的rowkey之后,还需要backup lookup主表,得到指定列的数据,那么通过include把需要经常访问的列加入到index table之后,可以省掉backup lookup主表的操作,进一步提升read性能.(关于include,这里很详细
http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html)