Java多线程 JMM之重排序详解
文章目录
- 重排序demo
- 什么是重排序
- 重排序的好处
- 重排序的三种情况
重排序demo
如下的代码演示了重排序的发生情况.
主要是有四个变量 xy ab .
线程1 是对 a赋初始化值为1 , 把b的值给x .
线程2 是给b赋初始化值为1 , 把a的值给y
package com.thread.jmm;
import java.util.concurrent.CountDownLatch;
/**
* 类名称:OutOfOrderExecution
* 类描述: 演示重排序的现象 “直到达到某个条件才停止”,测试小概率事件
*
* @author: https://javaweixin6.blog.csdn.net/
* 创建时间:2020/9/5 10:50
* Version 1.0
*/
public class OutOfOrderExecution {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
//记录程序运行了多少次
int i = 0;
while (true) {
//每执行一次加一
i++;
//每一次循环, 给 xy ab重新赋值为0
x = 0;
y = 0;
a = 0;
b = 0;
/**
* CountDownLatch 为闸门的作用. 可以让线程1的 a=1 线程2的 b=1 同时执行
* 构造方法传递的数字, 代表需要几次计数才能执行
*/
CountDownLatch countDownLatch = new CountDownLatch(3);
Thread thread1 = new Thread(() -> {
try {
countDownLatch.countDown();
//此处为需要等待的地方, 加上栅栏
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
a = 1;
x = b;
});
Thread thread2 = new Thread(() -> {
try {
countDownLatch.countDown();
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
b = 1;
y = a;
});
thread1.start();
thread2.start();
//线程启动后 , 开始倒数一次
countDownLatch.countDown();
//主线程等待子线程执行完毕
thread1.join();
thread2.join();
String result = "第" + i + "次(" + x + "," + y + ")";
if (x == 1 && y == 1) {
System.out.println(result);
break;
}else {
System.out.println(result);
}
}
}
}
上面的代码如果不发生重排序, 那么执行的结果可能是有如下的三种情况.
第一个情况是, 线程1先运行, 此时x获得的b的值是0 , a是1给了y . 因此结果是 x =0 , y=1
第二个情况是, 线程2 先运行, b是1, y获得的值是a为0的值, x获得的是b为1的值, 因此结果是 x=1 , y=0 .
第三种情况是:线程1执行到了a=1这一步之后, cpu调度到了线程2 , 线程2执行了b=1, 此时a=1, b=1 , 因此 x y的值分别就是1和1了.
上面的代码为了达到第三种情况, 使用了CountDownLatch , 以便于让线程1和2 能够同时执行.

运行程序后, 可以通过控制台看到 . 打印出了如下的三种情况.
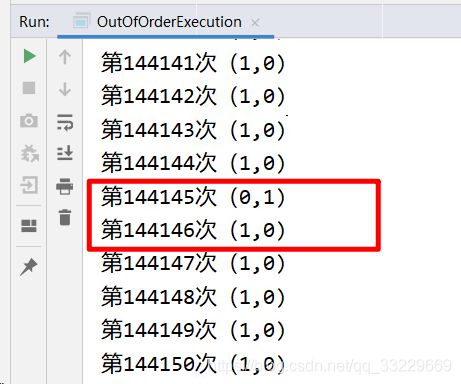

把上述代码中, x 和y的条件都改成0 . 可以看到程序在执行了12万多次后, 打印了0和0 . 此时证明了发生了重排序. 否则不会出现 0和0的情况.
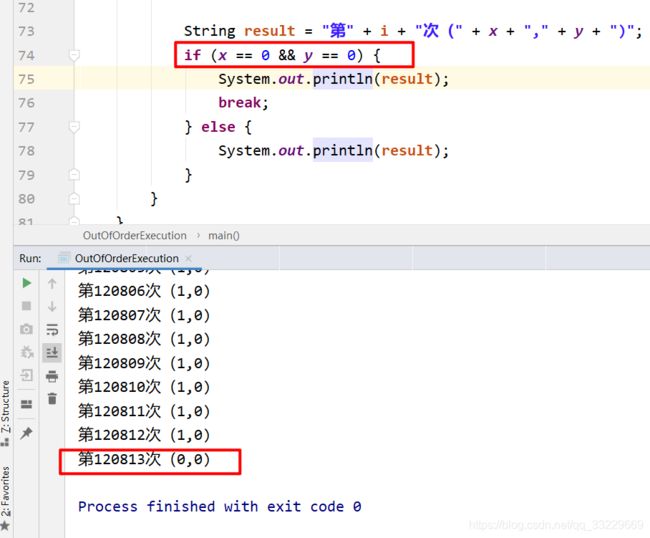
发生重排序的可能的一种情况如下. 原本是b=1在前, y=a在后. 发生了重排序后, y=a在前, b=1在后. 此时 a为= 0 , y就是0 , 执行完y=a完成后, 线程切换到线程1 , 此时x得到的b是0 , 因此结果就是0和0
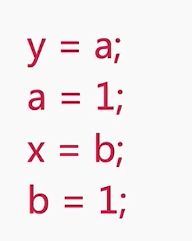
什么是重排序
在上面例子中的线程1内部的两行代码(a=1; x=b;), 实际的执行顺序和在Java文件中的顺序不一致, 代码指令并不是严格按照代码语句顺序执行的, 它们的顺序被改变了, 这就是重排序.
重排序的好处
重排序的好处是提高程序的处理速度.
如下图的示例, 右侧为对重排序的优化, 节省了对变量a的读取和赋值操作, 提升了处理速度.

重排序的三种情况
- 编译器优化: JVM, JIT编译器等
- CPU指令重排: 即使编译器不发生重排, CPU也可能发生重排序.
- 内存的"重排序" :在内存中由于有缓存的存在 , 在JMM中表现为主存和本地内存 ,不一定实时的保持一致, 这样就可能发现线程1 修改了某个共享变量, 线程2却看不到, 于是就体现出和重排序一样的线程. 例如线程1 修改了a为1 , 但是线程2还是获得的a为0的值, 这就和重排序一样,把0排到前面了. 这种现象表面为重排序, 实际为 JMM的可见性问题.