【谷歌插件爬虫实战】零基础不会代码想学爬虫?不用编写代码的图形界面化爬虫Web Scraper参上!——基于Google的扩展应用程序插件Web Scraper爬取B站全站榜TOP100
在博主通过Python相继学习了爬虫基础、两个基本库(urllib库、requests库)、三大解析库(XPath库、Beautiful Soup库、pyquery库)以及Selenium库后,通过测试谷歌插件Web Scraper进行网页爬取,发现这个小插件入门及其简单。因此,博主学了十分钟后当机立断爬取了Bilibili数据进行测试,并作此博客进行记录。
目录
- Web Scraper是什么?
- Web Scraper安装攻略
- Web Scraper爬取Bilibili全站榜TOP100实战演示
- 一、全站榜TOP100的爬取
- 二、各个视频中的发布时间、点赞数、投币数、收藏数的爬取
- 三、爬虫运行
- 四、数据导出
- 注意事项
Web Scraper是什么?
Web Scraper是一个Chrome浏览器插件,用来批量自动化地采集网页上的数据。
Web Scraper相当于对爬虫进行了封装、是一个程序封装的工具,哪怕是零基础、不懂计算机的人也能通过Web Scraper爬取所能看到的网页数据。
但是,作为一个小工具,自然有着它的局限性。Web scraper不适合下载大量图片,并且暂时只支持导出excel格式,它并不能够像代码编写爬虫那样灵活方便。
Web Scraper安装攻略
Web Scraper作为Chrome浏览器插件,一般可在谷歌应用商店进行安装。若渠道下载可联系博主,根据感兴趣的朋友人数博主会将Web Scraper的.crx插件打包发送至评论区。具体的crx插件安装方法可参考博主的另一篇博文:玩转Chrome插件?来康康这篇《Chrome扩展程序crx插件的导出与安装通用方法步骤》吧!
Web Scraper爬取Bilibili全站榜TOP100实战演示
一、全站榜TOP100的爬取
1.右键单击bilibili全站榜TOP100页面,选择检查,调出来开发者工具。点击Web Scraper,选择Create new sitemap下拉菜单中的Create Sitemap。(如果有Sitemap Json可以点击Import Sitemap直接导入Sitemap Json模板)
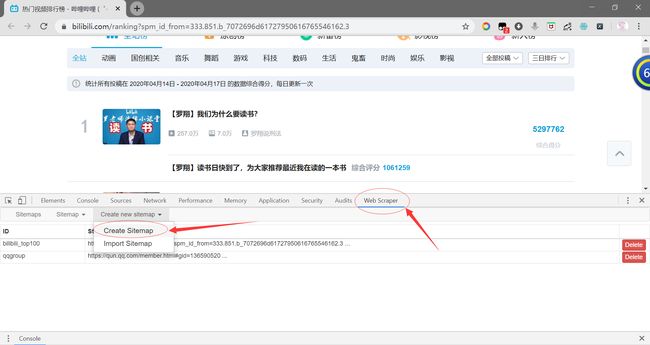
2.输入Sitemap name(项目名称)和Start URL(网页链接URL),点击Create Sitemap创建新项目。(本次实战中的Start URL即网页链接不需要转跳,如果有分页需要考虑到换页问题)

3.点击Add new selector(新建一个新的选择器)。
4.进入创建新选择器页面后,先选择一个Type(选择器类型),我们这里首先选择Element(元素)。选择元素的原因是因为我们要把网页中这一块给选择出来。
然后点击Select,将鼠标指针移动到网页元素上。

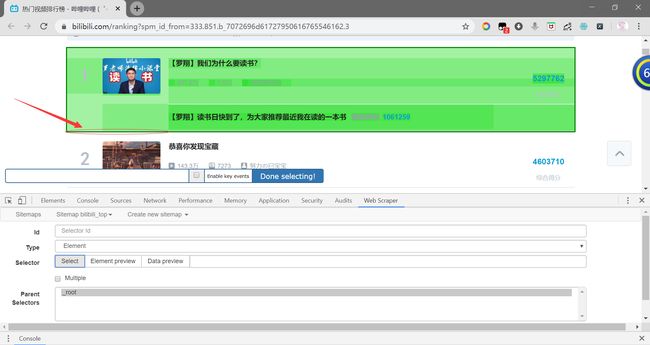
这里我们需要注意:以上这两种选择方式有所不同。必须把鼠标指针移动到元素的边缘位置(“1”上罩着绿色小方块),否则之后就无法提取到里面的排名“1”了。
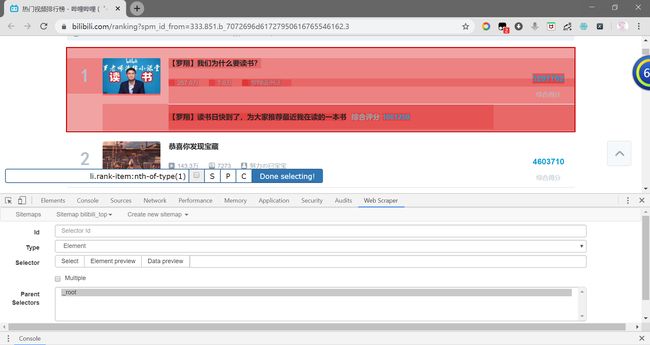
因为我们全站榜TOP100具有100个数据,因此我们需要以同样的方法选中第二个元素。这样,网页会自动帮忙选上所有的100个元素。
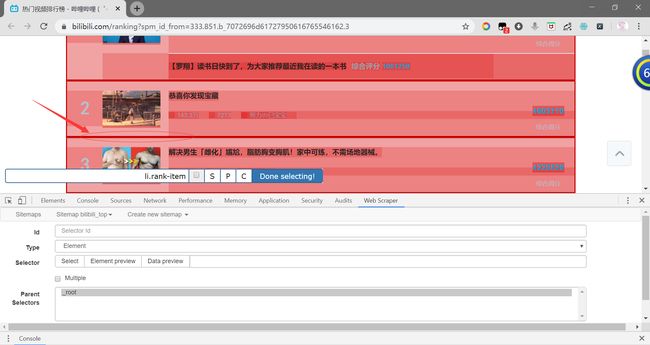
我们点击Done selecting,自动将匹配写入到Selector。由于我们需要同时选中多个元素,因此需要勾选上Multiple(多选)。最后输入id名称,点击Save selector。

5.点击元素TOP100,进入到元素TOP100之中。这时,我们需要将元素中的每个小元素块分别拿出来:序号、作品名称、观看人数、评论人数、作者名称、综合得分。


6.首先我们拿出“序号”。点击Add new selector,Id输入“作品排名”(因为“序号”太短Id名写入报警告、因此改为输入Id为“作品排名”),Type类型使用默认的Text(文本选择器)就行。点击select,选中序号“1”。点击Dne selecting将选中的匹配代码自动添加到Selector。

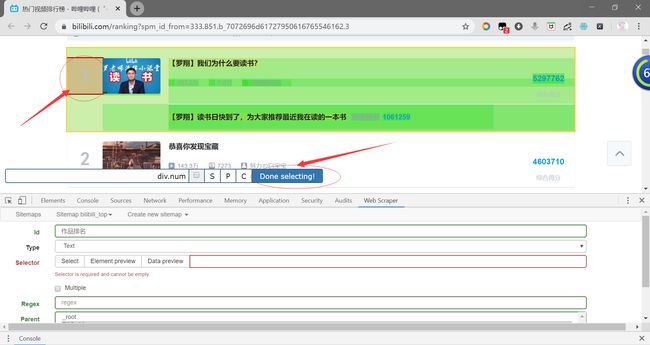
注意:由于这里是在元素内进行小元素块的选择,因此不用勾选Multiple(多选)。
直接点击Save selector保存选择器即可。
7.这时我们可以看到在TOP100中已经多出了一个Id为作品排名的selector。如果此时想要确认我们刚刚所需要爬取的序号是否已经爬取到,可以点击Data Preview。
我们可以看到,序号数据爬取成功。

8.爬取完成作品排名后,我们以同样的方法重复6的操作步骤,分别爬取作品名称、观看人数、评论人数、作者名称、综合名称。通过步骤7可以检验数据爬取是否成功。
此时,我们就完成了B站全站榜TOP100的全部数据。
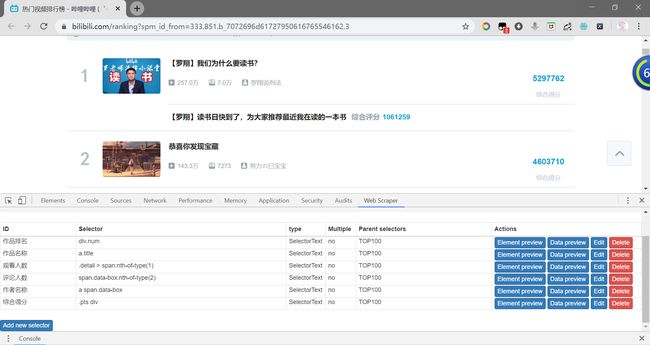
9.点击_root返回到项目根目录,点击Data Preview可观察B站全站榜TOP100页面的爬取内容信息。

此时,我们就已经完成了排行榜的爬取。
二、各个视频中的发布时间、点赞数、投币数、收藏数的爬取
1.点击TOP1视频进入到视频页面,观察页面,我们接下来要选中的是视频的发布时间、点赞人数、投币人数、收藏人数。

这里的第一步关键在于点击标题进入到视频当中,然后再去选择数据。
因此,我们首先点击TOP100进入到TOP100中,然后点击Add new selector创建一个新的选择器。
这时,我们Id输入link表示链接,Type选择Link类型,然后点击Select,选中网页中的TOP1的标题,点击Done selecting将匹配代码自动写入到Selector中。点击Save selector保存选择器。
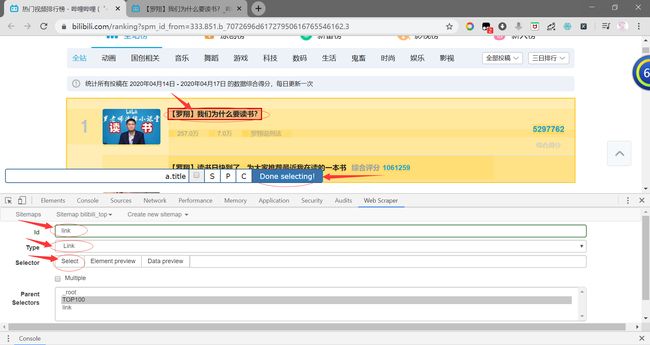
2.此时,我们需要在被点入的链接link中进行操作,即点击link进入到link内。

我们可以选择在新打开的视频页面中重新右键点击检查打开开发者工具,进入到Web Scraper中的TOP100项目的link内。

3.点击Add new selector,重复全站榜TOP100爬取的步骤6,分别爬取:发布时间、点赞人数、投币人数、收藏人数。
如果点击的时候不小心点到投币或收藏弹出页面,直接取消继续选择即可。
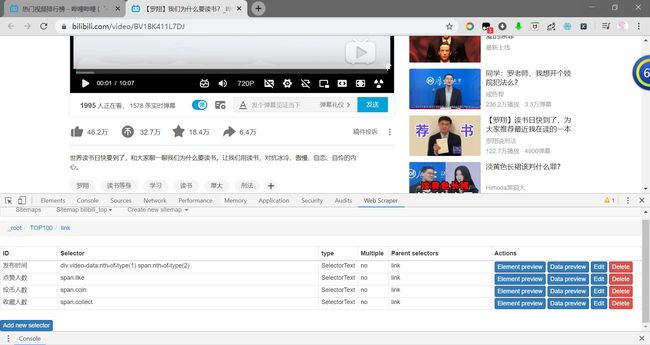
选择完毕以后,可点击Data Preview观察各个数据是否选取成功。
选取成功以后,我们就可以开始运行爬虫了。
三、爬虫运行
1.点击Sitemap bilibili_top中的Selector graph可以观看爬虫爬取路径的图像(爬虫逻辑图)。代码爬取也是如此,但是效率会比插件要快。


2.写完爬虫项目后点击Sitemap bilibili_top中的Scrape可以进行爬虫项目的运行爬取。此时,在Scrape中有Request interval(请求间隔时间)和Page load delay(页面加载完成后的延迟时间)。
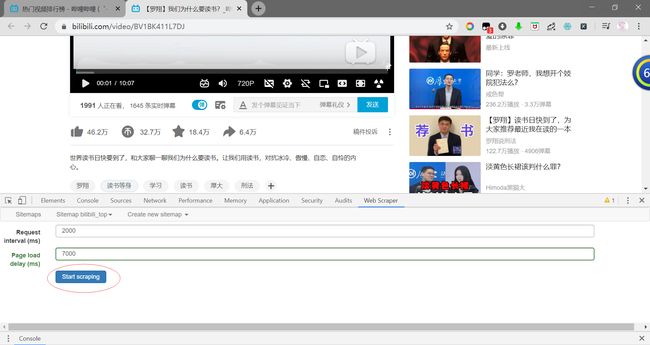
我们在加载页面时刚开始是看不到点赞人数、投币人数、收藏人数的。它们是B站通过Ajax请求传过来的响应数据。我们需要调整的主要就算Page load delay,具体数值调整根据自己网速状况即可。因为博主网速较差,之前设延迟5000有时都没能爬取出来数据,因此我选择设置7000(7秒)。
点击Start scraping,爬虫项目会自动弹出新页面像真人一样自动爬取我们所需数据。
这里弹出谷歌页面自动访问B站全站榜TOP100的底层代码如果是在Python中就是用到了爬虫中的Selenium来模拟网页的动作。
3.在爬取过程中,我们点击refer进行刷新,页面会立即返回目前已经爬取到的数据。我们可以点击Refresh Data不断进行刷新。

四、数据导出
1.假如我们数据已经爬取完毕了,可以点击Sitemap bilibili_top中的Export data as CSV导入到excel表格中。点击Download now,谷歌会自动下载已经爬取的Excel数据表格。

2.此时我们发现Excel表格作品排名并没有按照顺序。我们可以选择C这一列,点击数据中的排序,确定。选择主要关键字为作品排名,次序为升序即可。

数据整理完成。

注意事项
1.通过Web Scraper爬取数据如果爬到中途不想继续抓了,还想保留已经抓到的数据,可以断开网络。断开网络后,Web Scraper监测到网络没有响应,就会主动关闭,并将已经抓取到的数据保存。或者,在Chrome调试中的开发者工具里面点击Network,在Offline Online前面打勾,完成断网。
2.使用CSS伪类抓取固定数量数据后停止:在 Element 的 Selector 后面加上(-n+number),如果只抓取50条数据,则把number 改为50即可。