Redis缓存的使用
源码地址:https://github.com/bigBigRiver/redis.git
为什么要使用Redis缓存?
1、在高频访问数据库的情况下,缓解数据库的压力。
2、读取速度快。
流程是怎么样的?
1、当有查询请求的时候,先是访问Redis,如果Redis中有数据则直接返回,不需要访问数据库。如果没有,则访问数据库,将查询结果返回并在Redis中缓存起来,下一次访问就可以直接在Redis中读取了。
2、当有更新请求(包括插入)的时候,会同时更新数据库和Redis缓存,保持缓存和数据库一直。
Windows下,Redis的使用(仅限开发的时候使用,因为服务器基本都是用linux系统的)
下载地址:https://github.com/MicrosoftArchive/redis/releases
我下载的是Redis-x64-3.2.100.zip,解压之后cd进入Redis目录。
1、输入redis-server redis.windows.conf,Redis服务就启动好了。(窗口需要一直开着)
2、再新打开一个cmd窗口(Redis客户端),进入Redis目录,输入redis-cli -h 127.0.0.1 -p 6379,即可连接成功。
3、如果需要修改默认端口号,打开redis.windows.conf文件,找到port 6379修改即可。
4、如果需要做成windows服务,输入 redis-server --service-install redis.windows.conf即可。
5、如果需要安装Redis可视化软件Redis Desktop Manager,参考:https://www.jianshu.com/p/ccc3ebe29f7b
常用命令:
卸载服务:redis-server --service-uninstall
开启服务:redis-server --service-start
停止服务:redis-server --service-stop
Linux下,Redis的使用(CentOS7为例)
1、下载、解压、编译Redis
$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz
$ tar xzf redis-5.0.5.tar.gz
$ cd redis-5.0.5
$ make2、进入到解压后的 src 目录,通过如下命令启动Redis:(注意,不需要进入src目录)
$ src/redis-server3、使用内置客户端连接测试
[root@VM_16_13_centos redis-5.0.5]# src/redis-cli
127.0.0.1:6379> ping
PONG4、解除Redis的保护模式,这样其他计算机就可以连接了。
127.0.0.1:6379> CONFIG SET protected-mode no
OK5、linux下,启动Redis之后的窗口是可以关闭的。可以使用ps -ef|grep redis查看redis服务对应的进程信息。
下面是Redis Desktop Manager可视化软件的截图,管理Windows上和Linux上的Redis都非常方便,推荐使用!
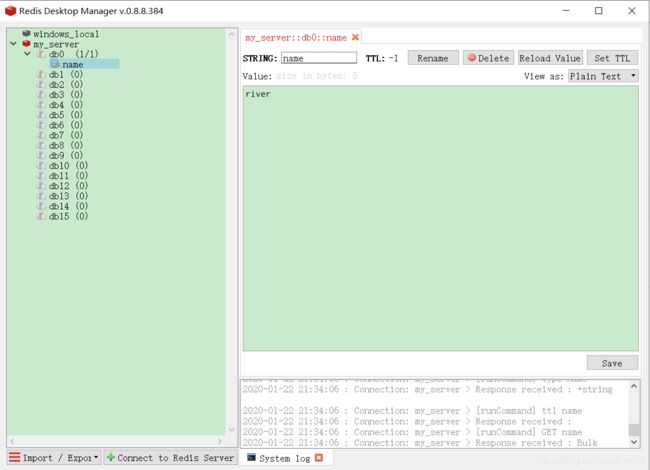
以上是环境的介绍,下面开始介绍Redis缓存的使用
1、添加依赖,配置application.yml文件
springboot项目已经加入了Redis缓存的依赖了。
spring:
redis:
host: 127.0.0.1
port: 63792、在Application类上加入@EnableCaching
@SpringBootApplication
@EnableCaching
public class RedisApplication {
public static void main(String[] args) {
SpringApplication.run(RedisApplication.class, args);
}
}3、@Cacheable注解的使用
作用(文章开头流程的第一条):当有查询请求的时候,先是访问Redis,如果Redis中有数据则直接返回,不需要访问数据库。如果没有,则访问数据库,将查询结果返回并在Redis中缓存起来,下一次访问就可以直接在Redis中读取了。
/**
* @author river
* 2020/1/22
*/
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
UserService userService;
@GetMapping("/findByUserNameLike")
@Cacheable(cacheNames = "user", key = "'river'+666")
public List findByUserNameLike(String userName) {
String name = userName + "%";
return userService.findByUserNameLike(name);
}
}
用debug模式,在String name这句打断点。第一次访问findByUserNameLike接口的时候会进入断点,第二次访问的时候就不会进入断点了,因为访问的是Redis缓存了。在Redis中对应的存储结构如下图:
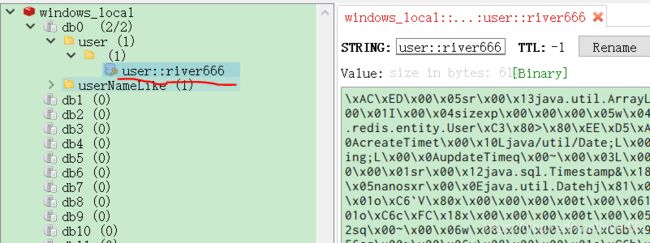
4、@CachePut注解的使用
作用(流程的第二条):将数据写入缓存中。
/**
* @author river
* 2020/1/22
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
UserRepository userRepository;
@Override
public List findByUserNameLike(String userName) {
return userRepository.findByUserNameLike(userName);
}
@Override
@Cacheable(cacheNames = "user", key = "'userInfo'")
public User findByUserName(String userName) {
return userRepository.findByUserName(userName);
}
@Override
@CachePut(cacheNames = "user", key = "'userInfo'")
public User saveOrUpdateUser(User user) {
return userRepository.save(user);
}
} 看到saveOrUpdateUser()这个方法标有注解@CachePut,更新数据库的同时写入Redis缓存中。这样当查询到新增的数据时,可以直接从缓存中取出。如果没有了@CachePut,调用findByUserName将拿到旧的缓存数据。
5、避免拿到旧的缓存数据,还可以使用@CacheEvict注解删除相应的缓存。
@Override
@CacheEvict(cacheNames = "user", key = "'userInfo'")
public User saveOrUpdateUser(User user) {
return userRepository.save(user);
}修改saveOrUpdateUser()方法,凡是修改信息的时候,删除相应的缓存。具体使用@CacheEvict还是@CachePut,要根据项目需要灵活使用。
6、使用@CacheConfig,简写代码
/**
* @author river
* 2020/1/22
*/
@Service
@CacheConfig(cacheNames = "user")
public class UserServiceImpl implements UserService {
@Autowired
UserRepository userRepository;
@Override
public List findByUserNameLike(String userName) {
return userRepository.findByUserNameLike(userName);
}
@Override
@Cacheable(key = "'userInfo'")
public User findByUserName(String userName) {
return userRepository.findByUserName(userName);
}
@Override
@CacheEvict(key = "'userInfo'")
public User saveOrUpdateUser(User user) {
return userRepository.save(user);
}
} 7、@Cacheable注解的补充
此注解还有两个常用属性,condition和unless,修改的代码如下:
@GetMapping("/findByUserNameLike")
@Cacheable(cacheNames = "user", key = "'river'+666", condition = "#userName.length() > 5", unless = "#result.size()>0")
public List findByUserNameLike(String userName) {
String name = userName + "%";
return userService.findByUserNameLike(name);
} 说明:
1、condition属性中的意思是,需要查询字符串userName的长度大于5才会缓存查询结果。
2、unless属性中的意思是,除非查询结果集的大小为0,其他情况都缓存查询结果。(即没有查到数据不需要缓存的意思)
这两个属性分别是对输入和输出做一个过滤的作用。
3、返回的json串中,如果不想要显示某个字段,加上@JsonIgnore即可。
4、以上两个属性使用的是Spring EL表达式,有兴趣的可以研究研究!
觉得有用的老铁赞一下呗~