tensorflow 多分类
刚开始入门学习tensorflow,这两天参考http://www.jianshu.com/p/d443aab9bcb1 将例子跑了一下。此例子,是二分类,但是其使用了softmax,可以用来进行三分类。于是改写如下,不知道对不对,希望大家能够帮忙指出问题,不胜感激!
大体思路如下:
首先使用word2vec训练好词向量;
然后将训练数据positive,negative,neutral三类各70个,分别放在三个不同不同文件中,进行训练得到模型。
再将测试三类测试数据各20个,分别放在positive_test, negative_test, neutral_test三个文件中,进行测试准确率。
【前期只是验证正确性,所以数据量比较少】
import gensim
import tensorflow as tfmodel=gensim.models.Word2Vec.load('wiki.zh.text.model')from os.path import isfile, join
positiveFile = 'data/positive'
negativeFile = 'data/negative'
neutralFile='data/neutral'
numWords = []
with open(positiveFile, "r", encoding='utf-8') as f:
for line in f.readlines():
#line=f.readline()
counter = len(line.split())
numWords.append(counter)
print('Positive files finished')
with open(negativeFile, "r", encoding='utf-8') as f:
for line in f.readlines():
#line=f.readline()
counter = len(line.split())
numWords.append(counter)
print('Negative files finished')
with open(neutralFile, "r", encoding='utf-8') as f:
for line in f.readlines():
#line=f.readline()
counter = len(line.split())
numWords.append(counter)
print('Neutral files finished')
print('The total number of words in the files is', max(numWords))
print('The total number of words in the files is', sum(numWords))
print('The average number of words in the files is', sum(numWords)/len(numWords))Positive files finished
Negative files finished
Neutral files finished
The total number of words in the files is 36
The total number of words in the files is 2905
The average number of words in the files is 13.833333333333334
说明:这一步,得到最大长度是36,因此后面可以将maxSeqLength设置为36
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(numWords, 5)
plt.xlabel('Sequence Length')
plt.ylabel('Frequency')
plt.axis([0, 40, 0, 100])[0, 40, 0, 100]

import numpy as np
Clients_vectors = np.array([model[word] for word in (model.wv.vocab)])
print(Clients_vectors.shape)(814983, 400)
batchSize = 24
maxSeqLength = 36
embedding_dim=400
lines=[]
with open(positiveFile, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
init_data=np.array(np.zeros((batchSize, maxSeqLength, embedding_dim),dtype=np.float32))
for i in range(batchSize):
line=lines[i]
list_temp=line.split()
line_length=len(list_temp)
for j in range(maxSeqLength):
if(j1):
init_data[i][j]=model[list_temp[j]] maxSeqLength = 36
embedding_dim=400
#我们可以开始构建我们的 TensorFlow 图模型。首先,我们需要去定义一些超参数,
#比如批处理大小,LSTM的单元个数,分类类别和训练次数。
batchSize = 24
lstmUnits = 64
numClasses = 3
iterations = 1000
tf.reset_default_graph()
data=init_data
labels = tf.placeholder(tf.float32, [batchSize, numClasses])
#我们将 LSTM cell 和三维的数据输入到 tf.nn.dynamic_rnn ,这个函数的功能是展开整个网络,并且构建一整个 RNN 模型。
lstmCell = tf.contrib.rnn.BasicLSTMCell(lstmUnits)
lstmCell = tf.contrib.rnn.DropoutWrapper(cell=lstmCell, output_keep_prob=0.75)
value, _ = tf.nn.dynamic_rnn(lstmCell, data, dtype=tf.float32)
#dynamic RNN 函数的第一个输出可以被认为是最后的隐藏状态向量。这个向量将被重新确定维度,
#然后乘以最后的权重矩阵和一个偏置项来获得最终的输出值。
weight = tf.Variable(tf.truncated_normal([lstmUnits, numClasses]))
bias = tf.Variable(tf.constant(0.1, shape=[numClasses]))
value = tf.transpose(value, [1, 0, 2])
last = tf.gather(value, int(value.get_shape()[0]) - 1)
prediction = (tf.matmul(last, weight) + bias)
#需要定义正确的预测函数和正确率评估参数。正确的预测形式是查看最后输出的0-1向量是否和标记的0-1向量相同。
correctPred = tf.equal(tf.argmax(prediction,1), tf.argmax(labels,1))
accuracy = tf.reduce_mean(tf.cast(correctPred, tf.float32))
#使用一个标准的交叉熵损失函数来作为损失值。对于优化器,我们选择 Adam,并且采用默认的学习率。
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=labels))
optimizer = tf.train.AdamOptimizer().minimize(loss)
sess = tf.Session()
#使用 Tensorboard 来可视化损失值和正确率
import datetime
tf.summary.scalar('Loss', loss)
tf.summary.scalar('Accuracy', accuracy)
merged = tf.summary.merge_all()
logdir = "tensorboard/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") + "/"
writer = tf.summary.FileWriter(logdir, sess.graph)lines=[]
with open(positiveFile, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
with open(negativeFile, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
with open(neutralFile, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
input_data = tf.placeholder(tf.int32, [batchSize, maxSeqLength, embedding_dim])
init_data=np.array(np.zeros((210, maxSeqLength, embedding_dim),dtype=np.float32))
for i in range(210):
line=lines[i]
list_temp=line.split()
line_length=len(list_temp)
for j in range(maxSeqLength):
if(j1):
if(list_temp[j] in model.wv.vocab.keys()):#有的词语,word2vec里面找不到,所以使用了这句
init_data[i][j]=model[list_temp[j]]
#训练网络
from random import randint
def getTrainBatch():
labels = []
arr = np.zeros([batchSize, maxSeqLength, embedding_dim])
for i in range(batchSize):
if (i % 3 == 0):
#positive
num = randint(0,69)
labels.append([1,0,0])
elif(i % 3==1):
#negative
num = randint(70,139)
labels.append([0,0,1])
else:
#neutral
num=randint(140,209)
labels.append([0,1,0])
arr[i] = init_data[num]
return arr, labels
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(iterations):
#Next Batch of reviews
nextBatch, nextBatchLabels = getTrainBatch();
sess.run(optimizer, {input_data: nextBatch, labels: nextBatchLabels})
#Write summary to Tensorboard
if (i % 50 == 0):
summary = sess.run(merged, {input_data: nextBatch, labels: nextBatchLabels})
writer.add_summary(summary, i)
#Save the network every 10,000 training iterations
if (i % 100 == 0 and i != 0):
save_path = saver.save(sess, "models/pretrained_lstm.ckpt", global_step=i)
print("saved to %s" % save_path)
writer.close() saved to models/pretrained_lstm.ckpt-100
saved to models/pretrained_lstm.ckpt-200
saved to models/pretrained_lstm.ckpt-300
saved to models/pretrained_lstm.ckpt-400
saved to models/pretrained_lstm.ckpt-500
saved to models/pretrained_lstm.ckpt-600
saved to models/pretrained_lstm.ckpt-700
saved to models/pretrained_lstm.ckpt-800
saved to models/pretrained_lstm.ckpt-900

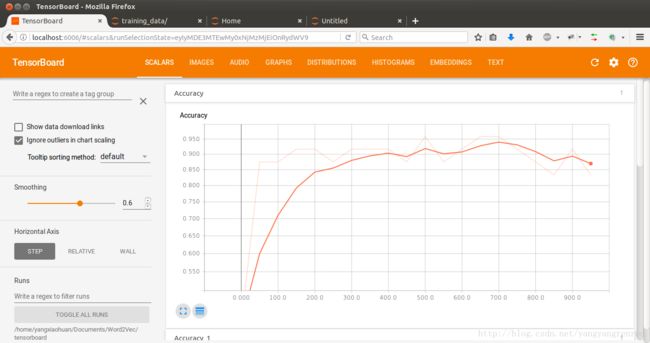
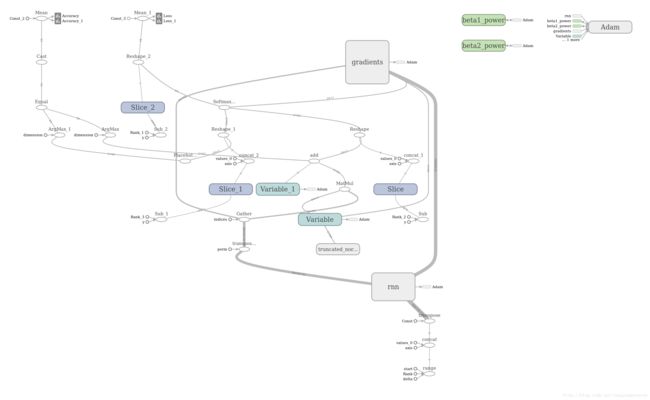
特别是这个图片,我觉得没有像其他图片那样简单,看着好复杂,不知道对错,或者有没有办法简化此图片
#对模型进行测试
positiveFile_test = 'data/positive_test'
negativeFile_test = 'data/negative_test'
neutralFile_test='data/neutral_test'
lines=[]
with open(positiveFile_test, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
with open(negativeFile_test, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
with open(neutralFile_test, "r", encoding='utf-8') as f:
for line in f.readlines():
lines.append(line)
input_data = tf.placeholder(tf.int32, [batchSize, maxSeqLength, embedding_dim])
init_data=np.array(np.zeros((60, maxSeqLength, embedding_dim),dtype=np.float32))
for i in range(60):
line=lines[i]
list_temp=line.split()
line_length=len(list_temp)
for j in range(maxSeqLength):
if(j1):
if(list_temp[j] in model.wv.vocab.keys()):#有的词语,word2vec里面找不到,所以使用了这句
init_data[i][j]=model[list_temp[j]]
from random import randint
def getTestBatch():
labels = []
arr = np.zeros([batchSize, maxSeqLength, embedding_dim])
for i in range(batchSize):
if (i % 3 == 0):
#positive
num = randint(0,19)
labels.append([1,0,0])
elif(i % 3==1):
#negative
num = randint(20,39)
labels.append([0,0,1])
else:
#neutral
num=randint(40,59)
labels.append([0,1,0])
arr[i] = init_data[num]
return arr, labels
iterations = 10
for i in range(iterations):
nextBatch, nextBatchLabels = getTestBatch();
print("Accuracy for this batch:", (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100) Accuracy for this batch: 87.5
Accuracy for this batch: 91.6666686535
Accuracy for this batch: 91.6666686535
Accuracy for this batch: 91.6666686535
Accuracy for this batch: 87.5
Accuracy for this batch: 100.0
Accuracy for this batch: 87.5
Accuracy for this batch: 87.5
Accuracy for this batch: 87.5
Accuracy for this batch: 95.8333313465