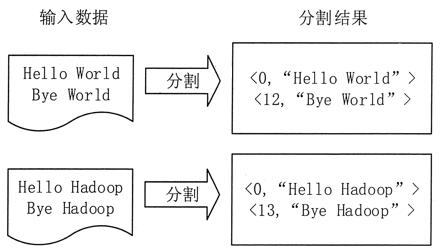
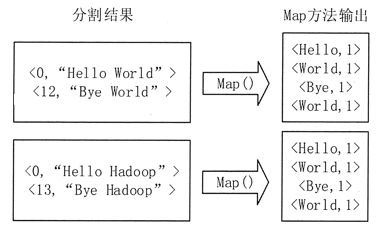
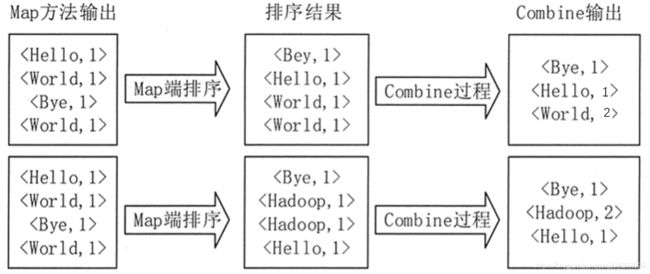
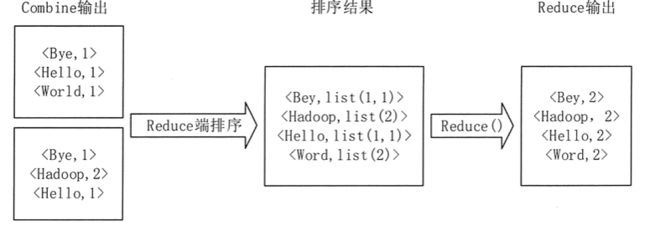
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
- hbase介绍
CrazyL-
云计算+大数据hbase
hbase是一个分布式的、多版本的、面向列的开源数据库hbase利用hadoophdfs作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写、适用于非结构化数据存储的数据库系统hbase利用hadoopmapreduce来处理hbase、中的海量数据hbase利用zookeeper作为分布式系统服务特点:数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)面向列:面向列(族)的
- Spark集群的三种模式
MelodyYN
#Sparksparkhadoopbigdata
文章目录1、Spark的由来1.1Hadoop的发展1.2MapReduce与Spark对比2、Spark内置模块3、Spark运行模式3.1Standalone模式部署配置历史服务器配置高可用运行模式3.2Yarn模式安装部署配置历史服务器运行模式4、WordCount案例1、Spark的由来定义:Hadoop主要解决,海量数据的存储和海量数据的分析计算。Spark是一种基于内存的快速、通用、可
- 月度总结 | 2022年03月 | 考研与就业的抉择 | 确定未来走大数据开发路线
「已注销」
个人总结hadoop
一、时间线梳理3月3日,寻找到同专业的就业伙伴3月5日,着手准备Java八股文,决定先走Java后端路线3月8月,申请到了校图书馆的考研专座,决定暂时放弃就业,先准备考研,买了数学和408的资料书3月9日-3月13日,因疫情原因,宿舍区暂封,这段时间在准备考研,发现内容特别多3月13日-3月19日,大部分时间在刷Hadoop、Zookeeper、Kafka的视频,同时在准备实习的项目3月20日,退
- 科锐国际(计算机类),汤臣倍健,中建三局,宁德时代,途游游戏,得物,顺丰,康冠科技24春招内推
weixin_53585422
c++算法pythonjavac语言
科锐国际(计算机类),汤臣倍健,中建三局,宁德时代,途游游戏,得物,顺丰,康冠科技24春招内推①汤臣倍健【内推岗位】:市场类、营销类、研发类、电商类、职能类、IT技术类、商业分析类、生产运营类【内推链接】https://sourl.cn/JSDhLU【推荐码】ES3W2T②科锐国际(OD项目组--计算机专场)【招聘岗位】软件开发工程师、软件测试工程师、大数据开发工程师、运维工程师等计算机类岗位,2
- HBase介绍
mingyu1016
数据库
概述HBase是一个分布式的、面向列的开源数据库,源于google的一篇论文《bigtable:一个结构化数据的分布式存储系统》。HBase是GoogleBigtable的开源实现,它利用HadoopHDFS作为其文件存储系统,利用HadoopMapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。HBase的表结构HBase以表的形式存储数据。表有行和列组成。列划分为
- Hadoop windows intelij 跑 MR WordCount
piziyang12138
一、软件环境我使用的软件版本如下:IntellijIdea2017.1Maven3.3.9Hadoop分布式环境二、创建maven工程打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建java工程即可,不用勾选Creatfromarchetype,如果想创建web工程或者使用骨架可以勾选)image.png设置GroupId和Artif
- ArcGIS地图切片原理与算法
数智侠
GIS
ArcGIS地图切图系列之(一)切片原理解析点击打开链接ArcGIS地图切图系列之(二)JAVA实现点击打开链接ArcGIS地图切图系列之(三)MapReduce实现点击打开链接
- 数据中台建设方案-基于大数据平台(下)
FRDATA1550333
大数据数据库架构数据库开发数据库
数据中台建设方案-基于大数据平台(下)1数据中台建设方案1.1总体建设方案1.2大数据集成平台1.3大数据计算平台1.3.1数据计算层建设计算层技术含量最高,最为活跃,发展也最为迅速。计算层主要实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持。大数据基础平台技术能力的高低,主要依赖于该层组件的发展。本建设方案满足甲方对于数据计算层建设的基本要求:利用了MapReduce、Spar
- MIT6.824 课程-MapReduce
余为民同志
6.824mapreduce分布式6.824
MapReduce:在大型集群上简化数据处理概要MapReduce是一种编程模型,它是一种用于处理和生成大型数据集的实现。用户通过指定一个用来处理键值对(Key/Value)的map函数来生成一个中间键值对集合。然后,再指定一个reduce函数,它用来合并所有的具有相同中间key的中间value。现实生活中有许多任务可以通过该模型进行表达,具体案例会在论文中展现出来。以这种函数式风格编写的程序能够
- Hadoop之mapreduce -- WrodCount案例以及各种概念
lzhlizihang
hadoopmapreduce大数据
文章目录一、MapReduce的优缺点二、MapReduce案例--WordCount1、导包2、Mapper方法3、Partitioner方法(自定义分区器)4、reducer方法5、driver(main方法)6、Writable(手机流量统计案例的实体类)三、关于片和块1、什么是片,什么是块?2、mapreduce启动多少个MapTask任务?四、MapReduce的原理五、Shuffle过
- Yarn介绍 - 大数据框架
why do not
大数据hadoop
YARN的概述YARN是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序YARN是Hadoop2.x版本中的一个新特性。它的出现其实是为了解决第一代MapReduce编程框架的不足,提高集群环境下的资源利用率,这些资源包括内存,磁盘,网络,IO等。Hadoop2.X版本中重新设计的这个YARN集群
- 浅析大数据Hadoop之YARN架构
haotian1685
python数据清洗人工智能大数据大数据学习深度学习大数据大数据学习YARNhadoop
1.YARN本质上是资源管理系统。YARN提供了资源管理和资源调度等机制1.1原HadoopMapReduce框架对于业界的大数据存储及分布式处理系统来说,Hadoop是耳熟能详的卓越开源分布式文件存储及处理框架,对于Hadoop框架的介绍在此不再累述,读者可参考Hadoop官方简介。使用和学习过老Hadoop框架(0.20.0及之前版本)的同仁应该很熟悉如下的原MapReduce框架图:1.2H
- 实时数仓之实时数仓架构(Hudi)(1),2024年最新熬夜整理华为最新大数据开发笔试题
2401_84181221
程序员架构大数据
+Hudi:湖仓一体数据管理框架,用来管理模型数据,包括ODS/DWD/DWS/DIM/ADS等;+Doris:OLAP引擎,同步数仓结果模型,对外提供数据服务支持;+Hbase:用来存储维表信息,维表数据来源一部分有Flink加工实时写入,另一部分是从Spark任务生产,其主要作用用来支持FlinkETL处理过程中的LookupJoin功能。这里选用Hbase原因主要因为Table的HbaseC
- 最新【JAVA问题解决方案】02,字节跳动大数据开发高级工程师
2401_84586779
大数据面试学习
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化资料的朋友,可以戳这里获取一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!publicvoidexcelTest(){Lists
- Hive的优势与使用场景
傲雪凌霜,松柏长青
后端大数据hivehadoop数据仓库
Hive的优势Hive作为一个构建在Hadoop上的数据仓库工具,具有许多优势,特别是在处理大规模数据分析任务时。以下是Hive的主要优势:1.与Hadoop生态系统的紧密集成Hive构建在Hadoop分布式文件系统(HDFS)之上,能够处理海量数据并进行分布式计算。它利用Hadoop的MapReduce或Spark来执行查询,具备高度扩展性,适合大数据处理。2.支持SQL-like查询语言(Hi
- HiveSQL一本通 - 案例实操,2024年最新大数据开发编程基础班
疯狂的石头。
程序员大数据
count(stu_id)stu_countfromscore_infogroupbycourse_idhavingstu_count>=15;(3)查询结果。course_idstu_count0119021903196.3.4查询结果排序和分组指定条件1.查询学生的总成绩并按照总成绩降序排序(1)思路分析。本题主要考查分组聚合和orderby关键字的使用。(2)查询语句。hive>select
- Spark概念知识笔记
kuntoria
最近总结了个人的各项能力,发现在大数据这方面几乎没有涉及,因此想补充这方面的知识,丰富自己的知识体系,大数据生态主要包含:Hadoop和Spark两个部分,Spark作用相当于MapReduceMapReduce和Spark对比如下磁盘由于其物理特性现在,速度提升非常困难,远远跟不上CPU和内存的发展速度。近几十年来,内存的发展一直遵循摩尔定律,价格在下降,内存在增加。现在主流的服务器,几百GB或
- 【Hadoop】- MapReduce & YARN 初体验[9]
星星法术嗲人
hadoophadoopmapreduce
目录提交MapReduce程序至YARN运行1、提交wordcount示例程序1.1、先准备words.txt文件上传到hdfs,文件内容如下:1.2、在hdfs中创建两个文件夹,分别为/input、/output1.3、将创建好的words.txt文件上传到hdfs中/input1.4、提交MapReduce程序至YARN1.5、可通过node1:8088查看1.6、返回我们的服务器,检查输出文
- Spark一些个人总结
易逑实战数据
大数据sparkbigdatascala
文章目录前言一、Spark是什么二、Spark用来做什么三、Spark的优势是什么四、为什么用Spark五、Spark解决了什么问题总结前言随着大数据技术的发展,一些更加优秀的组件被提了出来,比如现在最常用的Spark组件,基于RDD原理在大数据处理中占据了越来越重要的作用。在此我们探索了Spark的原理,以及其在大数据开发中的重要作用。一、Spark是什么Spark是一个用来实现快速,通用的集群
- DAG (directed acyclic graph) 作为大数据执行引擎的优点
joeywen
分布式计算StormSparkStorm杂谈StormsparkDAG
TL;DR-ConceptuallyDAGmodelisastrictgeneralizationofMapReducemodel.DAG-basedsystemslikeSparkandTezthatareawareofthewholeDAGofoperationscandobetterglobaloptimizationsthansystemslikeHadoopMapReducewhicha
- 最全金融数据_PySpark-3(2),大数据开发学习的三个终极问题及学习路线规划
2401_84185145
大数据面试学习
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新需要这份系统化资料的朋友,可以戳这里获取frompyspark.ml.evaluationimportBinaryClassificationEv
- Hadoop组件
静听山水
Hadoophadoop
这张图片展示了Hadoop生态系统的一些主要组件。Hadoop是一个开源的大数据处理框架,由Apache基金会维护。以下是每个组件的简短介绍:HBase:一个分布式、面向列的NoSQL数据库,基于GoogleBigTable的设计理念构建。HBase提供了实时读写访问大量结构化和半结构化数据的能力,非常适合大规模数据存储。Pig:一种高级数据流语言和执行引擎,用于编写MapReduce任务。Pig
- Hadoop-MapReduce机制原理
H.S.T不想卷
大数据hadoopmapreduce大数据
MapReduce机制原理1、MapReduce概述2、MapReduce特点3、MapReduce局限性4、MapTask5、Map阶段步骤:6、Reduce阶段步骤:7、MapReduce阶段图1、MapReduce概述 HadoopMapReduce是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)
- EMR组件部署指南
ivwdcwso
运维EMR大数据开源运维
EMR(ElasticMapReduce)是一个大数据处理和分析平台,包含了多个开源组件。本文将详细介绍如何部署EMR的主要组件,包括:JDK1.8ElasticsearchKafkaFlinkZookeeperHBaseHadoopPhoenixScalaSparkHive准备工作所有操作都在/data目录下进行。首先安装JDK1.8:yuminstalljava-1.8.0-openjdk部署
- Java 快速入门 知识精简(1)
Tangy范
Javajava开发语言
语言特点特点一:面向对象俩个基本概念:类,对象三大特性:封装,继承,多态特点二:健壮性去掉了指针,内存的申请与释放提供了相对安全的内存管理和访问机制特点三:跨平台性由JVM负责Java程序在系统中的运行JVMforUNIXJVMforWindowsJVMforMac应用领域:JavaWeb开发后台开发大数据开发Android应用程序开发:客户端开发知识结构编程语言核心结构:主要知识点:变量、基本语
- hive学习记录
2302_80695227
hive学习hadoop
一、Hive的基本概念定义:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。Hive将HQL(HiveQueryLanguage)转化成MapReduce程序或其他分布式计算引擎(如Tez、Spark)的任务进行计算。数据存储:Hive处理的数据存储在HDFS(HadoopDistributedFileSystem)上。执行引擎:Hive的
- Mapreduce是什么
whisky丶
简单来说,MapReduce是一个编程模型,用以进行大数据量的计算。HadoopMapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。Mapreduce的特点:软件框架并行处理可靠且容错大规模集群海量数据集
- Hadoop之MapReduce
qq_43198449
1.MapReduce解决的问题1)数据问题:10G的TXT文件2)生活问题:统计分类上海市的图书馆的书2.MapReduce是什么MapReduce是一种分布式的离线计算框架,是一种编程模型,用于大规模数据集(大于1TB)的并行运算将自己的程序运行在分布式系统上。概念是:Map(映射)"和"Reduce(归约)指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduc
- java杨辉三角
3213213333332132
java基础
package com.algorithm;
/**
* @Description 杨辉三角
* @author FuJianyong
* 2015-1-22上午10:10:59
*/
public class YangHui {
public static void main(String[] args) {
//初始化二维数组长度
int[][] y
- 《大话重构》之大布局的辛酸历史
白糖_
重构
《大话重构》中提到“大布局你伤不起”,如果企图重构一个陈旧的大型系统是有非常大的风险,重构不是想象中那么简单。我目前所在公司正好对产品做了一次“大布局重构”,下面我就分享这个“大布局”项目经验给大家。
背景
公司专注于企业级管理产品软件,企业有大中小之分,在2000年初公司用JSP/Servlet开发了一套针对中
- 电驴链接在线视频播放源码
dubinwei
源码电驴播放器视频ed2k
本项目是个搜索电驴(ed2k)链接的应用,借助于磁力视频播放器(官网:
http://loveandroid.duapp.com/ 开放平台),可以实现在线播放视频,也可以用迅雷或者其他下载工具下载。
项目源码:
http://git.oschina.net/svo/Emule,动态更新。也可从附件中下载。
项目源码依赖于两个库项目,库项目一链接:
http://git.oschina.
- Javascript中函数的toString()方法
周凡杨
JavaScriptjstoStringfunctionobject
简述
The toString() method returns a string representing the source code of the function.
简译之,Javascript的toString()方法返回一个代表函数源代码的字符串。
句法
function.
- struts处理自定义异常
g21121
struts
很多时候我们会用到自定义异常来表示特定的错误情况,自定义异常比较简单,只要分清是运行时异常还是非运行时异常即可,运行时异常不需要捕获,继承自RuntimeException,是由容器自己抛出,例如空指针异常。
非运行时异常继承自Exception,在抛出后需要捕获,例如文件未找到异常。
此处我们用的是非运行时异常,首先定义一个异常LoginException:
/**
* 类描述:登录相
- Linux中find常见用法示例
510888780
linux
Linux中find常见用法示例
·find path -option [ -print ] [ -exec -ok command ] {} \;
find命令的参数;
- SpringMVC的各种参数绑定方式
Harry642
springMVC绑定表单
1. 基本数据类型(以int为例,其他类似):
Controller代码:
@RequestMapping("saysth.do")
public void test(int count) {
}
表单代码:
<form action="saysth.do" method="post&q
- Java 获取Oracle ROWID
aijuans
javaoracle
A ROWID is an identification tag unique for each row of an Oracle Database table. The ROWID can be thought of as a virtual column, containing the ID for each row.
The oracle.sql.ROWID class i
- java获取方法的参数名
antlove
javajdkparametermethodreflect
reflect.ClassInformationUtil.java
package reflect;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtMethod;
import javassist.Modifier;
import javassist.bytecode.CodeAtt
- JAVA正则表达式匹配 查找 替换 提取操作
百合不是茶
java正则表达式替换提取查找
正则表达式的查找;主要是用到String类中的split();
String str;
str.split();方法中传入按照什么规则截取,返回一个String数组
常见的截取规则:
str.split("\\.")按照.来截取
str.
- Java中equals()与hashCode()方法详解
bijian1013
javasetequals()hashCode()
一.equals()方法详解
equals()方法在object类中定义如下:
public boolean equals(Object obj) {
return (this == obj);
}
很明显是对两个对象的地址值进行的比较(即比较引用是否相同)。但是我们知道,String 、Math、I
- 精通Oracle10编程SQL(4)使用SQL语句
bijian1013
oracle数据库plsql
--工资级别表
create table SALGRADE
(
GRADE NUMBER(10),
LOSAL NUMBER(10,2),
HISAL NUMBER(10,2)
)
insert into SALGRADE values(1,0,100);
insert into SALGRADE values(2,100,200);
inser
- 【Nginx二】Nginx作为静态文件HTTP服务器
bit1129
HTTP服务器
Nginx作为静态文件HTTP服务器
在本地系统中创建/data/www目录,存放html文件(包括index.html)
创建/data/images目录,存放imags图片
在主配置文件中添加http指令
http {
server {
listen 80;
server_name
- kafka获得最新partition offset
blackproof
kafkapartitionoffset最新
kafka获得partition下标,需要用到kafka的simpleconsumer
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.
- centos 7安装docker两种方式
ronin47
第一种是采用yum 方式
yum install -y docker
- java-60-在O(1)时间删除链表结点
bylijinnan
java
public class DeleteNode_O1_Time {
/**
* Q 60 在O(1)时间删除链表结点
* 给定链表的头指针和一个结点指针(!!),在O(1)时间删除该结点
*
* Assume the list is:
* head->...->nodeToDelete->mNode->nNode->..
- nginx利用proxy_cache来缓存文件
cfyme
cache
user zhangy users;
worker_processes 10;
error_log /var/vlogs/nginx_error.log crit;
pid /var/vlogs/nginx.pid;
#Specifies the value for ma
- [JWFD开源工作流]JWFD嵌入式语法分析器负号的使用问题
comsci
嵌入式
假如我们需要用JWFD的语法分析模块定义一个带负号的方程式,直接在方程式之前添加负号是不正确的,而必须这样做:
string str01 = "a=3.14;b=2.71;c=0;c-((a*a)+(b*b))"
定义一个0整数c,然后用这个整数c去
- 如何集成支付宝官方文档
dai_lm
android
官方文档下载地址
https://b.alipay.com/order/productDetail.htm?productId=2012120700377310&tabId=4#ps-tabinfo-hash
集成的必要条件
1. 需要有自己的Server接收支付宝的消息
2. 需要先制作app,然后提交支付宝审核,通过后才能集成
调试的时候估计会真的扣款,请注意
- 应该在什么时候使用Hadoop
datamachine
hadoop
原帖地址:http://blog.chinaunix.net/uid-301743-id-3925358.html
存档,某些观点与我不谋而合,过度技术化不可取,且hadoop并非万能。
--------------------------------------------万能的分割线--------------------------------
有人问我,“你在大数据和Hado
- 在GridView中对于有外键的字段使用关联模型进行搜索和排序
dcj3sjt126com
yii
在GridView中使用关联模型进行搜索和排序
首先我们有两个模型它们直接有关联:
class Author extends CActiveRecord {
...
}
class Post extends CActiveRecord {
...
function relations() {
return array(
'
- 使用NSString 的格式化大全
dcj3sjt126com
Objective-C
格式定义The format specifiers supported by the NSString formatting methods and CFString formatting functions follow the IEEE printf specification; the specifiers are summarized in Table 1. Note that you c
- 使用activeX插件对象object滚动有重影
蕃薯耀
activeX插件滚动有重影
使用activeX插件对象object滚动有重影 <object style="width:0;" id="abc" classid="CLSID:D3E3970F-2927-9680-BBB4-5D0889909DF6" codebase="activex/OAX339.CAB#
- SpringMVC4零配置
hanqunfeng
springmvc4
基于Servlet3.0规范和SpringMVC4注解式配置方式,实现零xml配置,弄了个小demo,供交流讨论。
项目说明如下:
1.db.sql是项目中用到的表,数据库使用的是oracle11g
2.该项目使用mvn进行管理,私服为自搭建nexus,项目只用到一个第三方 jar,就是oracle的驱动;
3.默认项目为零配置启动,如果需要更改启动方式,请
- 《开源框架那点事儿16》:缓存相关代码的演变
j2eetop
开源框架
问题引入
上次我参与某个大型项目的优化工作,由于系统要求有比较高的TPS,因此就免不了要使用缓冲。
该项目中用的缓冲比较多,有MemCache,有Redis,有的还需要提供二级缓冲,也就是说应用服务器这层也可以设置一些缓冲。
当然去看相关实现代代码的时候,大致是下面的样子。
[java]
view plain
copy
print
?
public vo
- AngularJS浅析
kvhur
JavaScript
概念
AngularJS is a structural framework for dynamic web apps.
了解更多详情请见原文链接:http://www.gbtags.com/gb/share/5726.htm
Directive
扩展html,给html添加声明语句,以便实现自己的需求。对于页面中html元素以ng为前缀的属性名称,ng是angular的命名空间
- 架构师之jdk的bug排查(一)---------------split的点号陷阱
nannan408
split
1.前言.
jdk1.6的lang包的split方法是有bug的,它不能有效识别A.b.c这种类型,导致截取长度始终是0.而对于其他字符,则无此问题.不知道官方有没有修复这个bug.
2.代码
String[] paths = "object.object2.prop11".split("'");
System.ou
- 如何对10亿数据量级的mongoDB作高效的全表扫描
quentinXXZ
mongodb
本文链接:
http://quentinXXZ.iteye.com/blog/2149440
一、正常情况下,不应该有这种需求
首先,大家应该有个概念,标题中的这个问题,在大多情况下是一个伪命题,不应该被提出来。要知道,对于一般较大数据量的数据库,全表查询,这种操作一般情况下是不应该出现的,在做正常查询的时候,如果是范围查询,你至少应该要加上limit。
说一下,
- C语言算法之水仙花数
qiufeihu
c算法
/**
* 水仙花数
*/
#include <stdio.h>
#define N 10
int main()
{
int x,y,z;
for(x=1;x<=N;x++)
for(y=0;y<=N;y++)
for(z=0;z<=N;z++)
if(x*100+y*10+z == x*x*x
- JSP指令
wyzuomumu
jsp
jsp指令的一般语法格式: <%@ 指令名 属性 =”值 ” %>
常用的三种指令: page,include,taglib
page指令语法形式: <%@ page 属性 1=”值 1” 属性 2=”值 2”%>
include指令语法形式: <%@include file=”relative url”%> (jsp可以通过 include