spark:开发本地测试的wordcount程序


1.使用Java开发本地测试的wordcount程序-1
2.使用Scala开发本地测试的wordcount程序-1
测试文件上传:
hadoop fs -put wordcount.txt /wordcount.txt
使用eclipse开发实现:
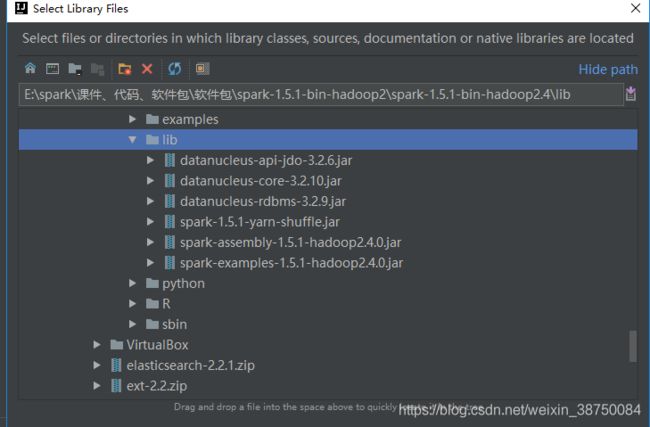
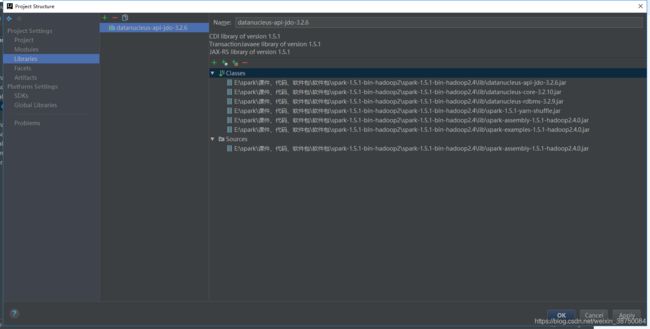
开发时注意导入 spark-assembly-1.6.0-hadoop2.6.0.jar包。
读取本地文件:
scalaWordCountDemoLocalFile.sh
/usr/local/spark/bin/spark-submit \
--class com.spark.demo.ScalaWordCountDemoLocalFile \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 1 \
/usr/local/spark-study/test_jars/ScalaWordCountDemo.jar \ScalaWordCountDemoLocalFile 读取本地文件(报错)
package com.spark.demo
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
/**
* scala统计字符出现次数
*/
object ScalaWordCountDemoLocalFile {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("ScalaWordCountDemo");
val sc = new SparkContext(conf)
val lines = sc.textFile("/usr/local/spark-study/test_files/wordcount.txt")
val words=lines.flatMap{line => line.split(" ")}
val pairs = words.map{word=>(word,1)}
val wordCount = pairs.reduceByKey{_+_}
wordCount.foreach(wordCount=>println(wordCount._1 + " appeared "+wordCount._2 +"times..."))
sc.stop()
}
}
读取hdfs文件:
scalaWordCountDemoHdfsFile.sh
/usr/local/spark/bin/spark-submit \
--class com.spark.demo.ScalaWordCountDemoHdfsFile \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 1 \
/usr/local/spark-study/test_jars/ScalaWordCountDemo.jar \ScalaWordCountDemoHdfsFile读取HDFS文件:
package com.spark.demo
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
/**
* scala统计字符出现次数
* 读取 hdfs文件
*/
object ScalaWordCountDemoHdfsFile {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("ScalaWordCountDemo");
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://sparkproject1:9000/wordcount.txt") //路径配置为/wordcount.txt也可以
val words=lines.flatMap{line => line.split(" ")}
val pairs = words.map{word=>(word,1)}
val wordCount = pairs.reduceByKey{_+_}
wordCount.foreach(wordCount=>println(wordCount._1 + " appeared "+wordCount._2 +"times..."))
sc.stop()
}
}执行结果:
19/06/13 03:40:21 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
19/06/13 03:40:21 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1967 bytes)
19/06/13 03:40:21 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 1)
19/06/13 03:40:21 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/06/13 03:40:21 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 21 ms
scala appeared 1times...
spark appeared 1times...
hadoop appeared 1times...
hello appeared 4times...
java appeared 1times...
paython appeared 1times...
19/06/13 03:40:21 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/06/13 03:40:21 INFO scheduler.DAGScheduler: ResultStage 1 (foreach at ScalaWordCountDemo.scala:20) finished in 0.141 s
19/06/13 03:40:21 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 143 ms on localhost (1/1)
19/06/13 03:40:21 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/06/13 03:40:21 INFO scheduler.DAGScheduler: Job 0 finished: foreach at ScalaWordCountDemo.scala:20, took 4.431661 s
19/06/13 03:40:21 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
19/06/13 03:40:21 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
使用IDEA开发实现:

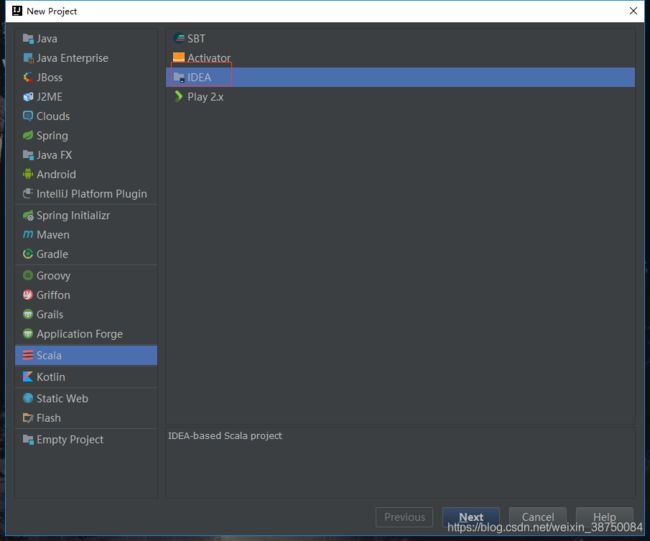
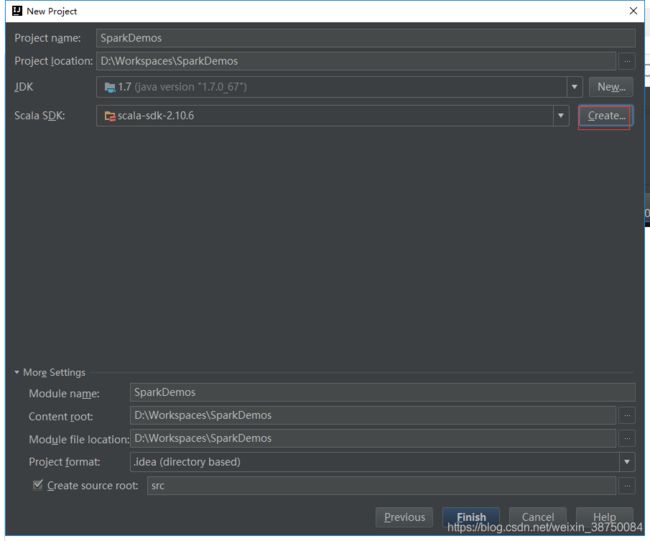
创建几个目录:
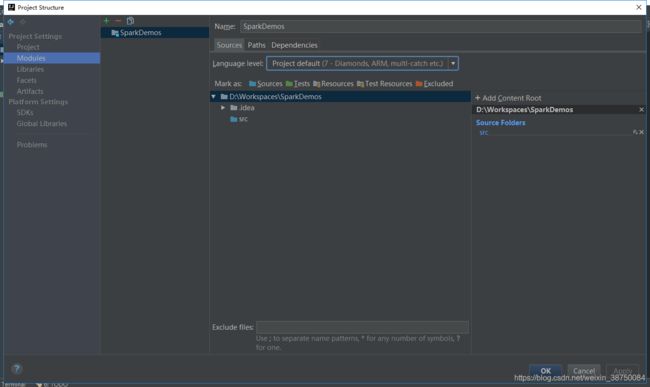
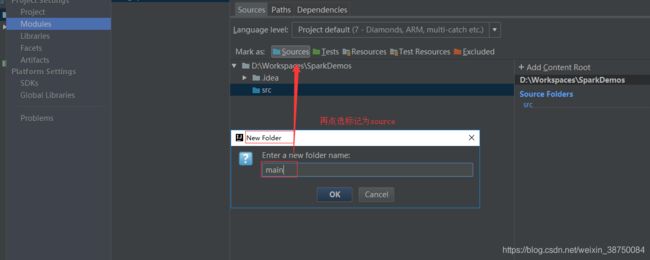
新增完毕:
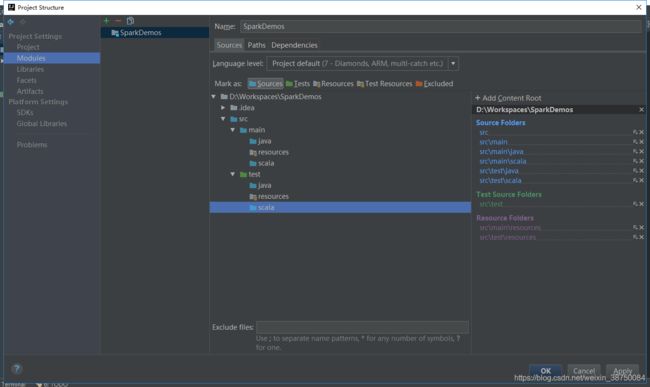
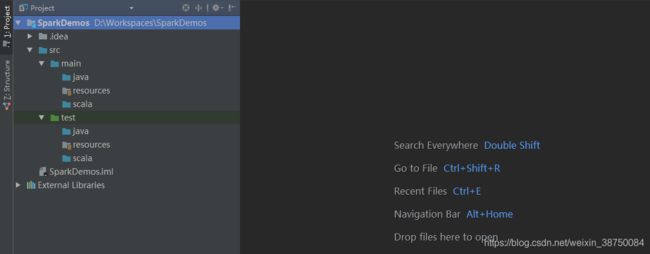
新建一个package:
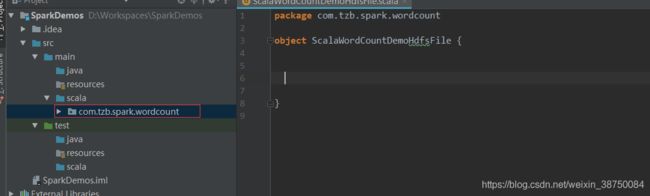
导包:
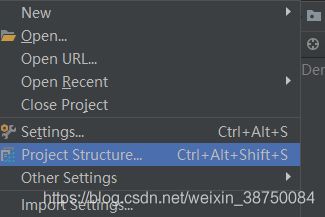
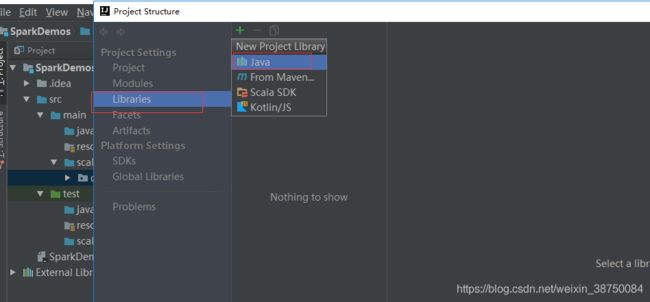
课程视频:
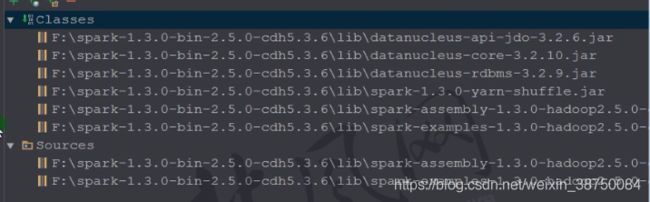
我的:
即可。
代码:
package com.tzb.spark.wordcount
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* scala统计字符出现次数
* 读取 hdfs文件
*/
object ScalaWordCountDemoHdfsFile {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("ScalaWordCountDemo").setMaster("local");//注意本地运行时加上.setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://sparkproject1:9000/wordcount.txt")
val words=lines.flatMap{line => line.split(" ")}
val pairs = words.map{word=>(word,1)}
val wordCount = pairs.reduceByKey{_+_}
wordCount.foreach(wordCount=>println(wordCount._1 + " appeared "+wordCount._2 +"times..."))
sc.stop()
}
}右键-执行run
执行结果:
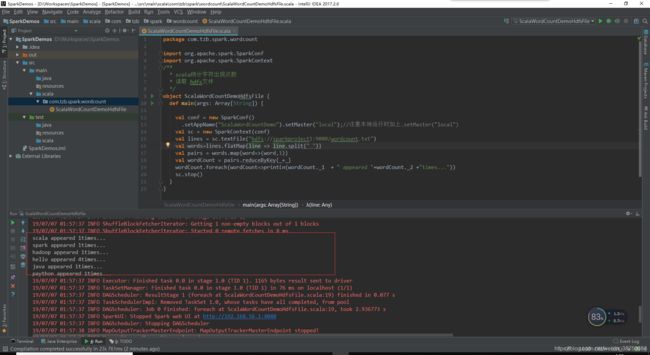
这是本地可调试。
hdfs上创建多级文件夹:
hadoop dfs -mkdir -p /spark/spark-studay/test_results
将结果写出到hdfs文件:
上面代码最后加上一行:
wordCount.saveAsTextFile("hdfs://sparkproject1:9000/spark/spark-studay/test_results")然后再次执行run:
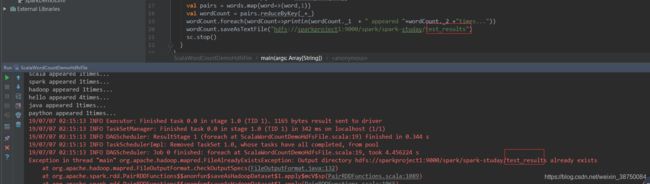
所以要写出的目录不能是已经存在的
目录换为:
wordCount.saveAsTextFile("hdfs://sparkproject1:9000/spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile")
再次执行run,报错说无权限 :

19/07/07 02:17:35 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/07/07 02:17:35 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 69 ms on localhost (1/1)
19/07/07 02:17:35 INFO DAGScheduler: ResultStage 1 (foreach at ScalaWordCountDemoHdfsFile.scala:19) finished in 0.070 s
19/07/07 02:17:35 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/07/07 02:17:35 INFO DAGScheduler: Job 0 finished: foreach at ScalaWordCountDemoHdfsFile.scala:19, took 2.642317 s
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=tang, access=WRITE, inode="/spark/spark-studay/test_results":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:257)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:238)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:216)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkPermission(DefaultAuthorizationProvider.java:145)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:138)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6345)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6327)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6279)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:4146)让我奇怪的是用户名怎么会是tang
参考这篇文章:
https://blog.csdn.net/u010885548/article/details/80624154
最终,总结下来解决办法大概有三种:
1、在系统的环境变量或java JVM变量里面添加HADOOP_USER_NAME,这个值具体等于多少看自己的情况,以后会运行HADOOP上的Linux的用户名。(修改完重启eclipse,不然可能不生效)
2、将当前系统的帐号修改为hadoop
3、使用HDFS的命令行接口修改相应目录的权限,hadoop fs -chmod 777 /user,后面的/user是要上传文件的路径,不同的情况可能不一样,比如要上传的文件路径为hdfs://namenode/user/xxx.doc,则这样的修改可以,如果要上传的文件路径为hdfs://namenode/java/xxx.doc,则要修改的为hadoop fs -chmod 777 /java或者hadoop fs -chmod 777 /,java的那个需要先在HDFS里面建立Java目录,后面的这个是为根目录调整权限。
查看我的windows环境变量确实配置了 username为tang:
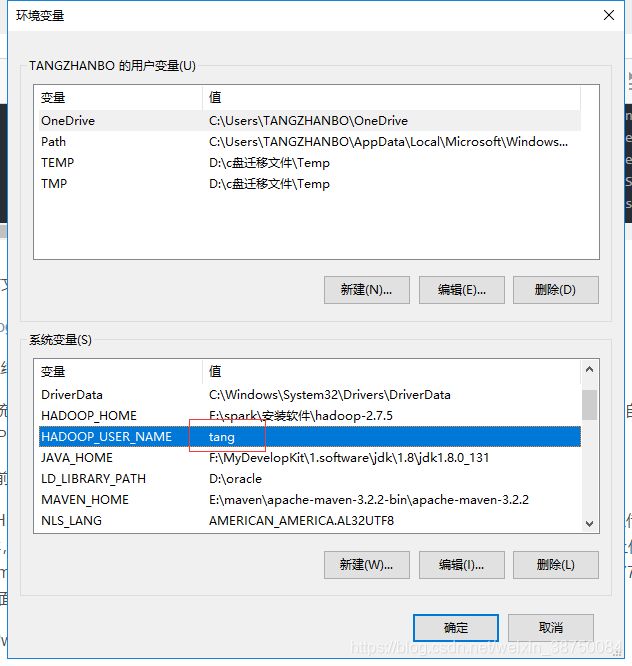
因为我是root用户建的文件夹 ,所以这里改为root

再次执行run试一次:
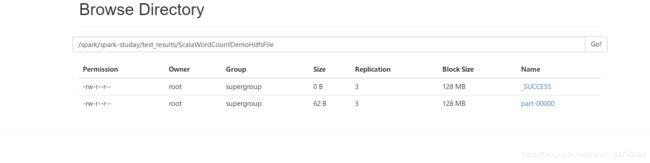
读取结果文件:
hadoop dfs -text /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile/part-00000
[root@sparkproject1 lib]# hadoop dfs -text /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile/part-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
19/06/13 05:49:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(scala,1)
(spark,1)
(hadoop,1)
(hello,4)
(java,1)
(paython,1)
[root@sparkproject1 lib]# 打包:
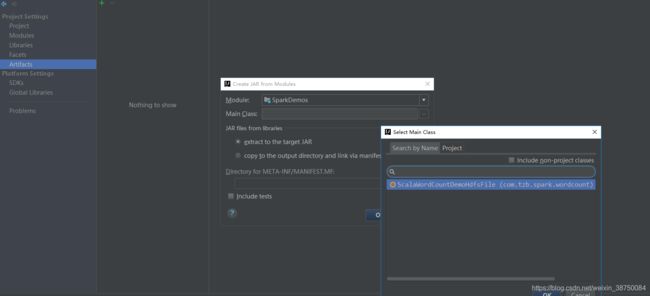
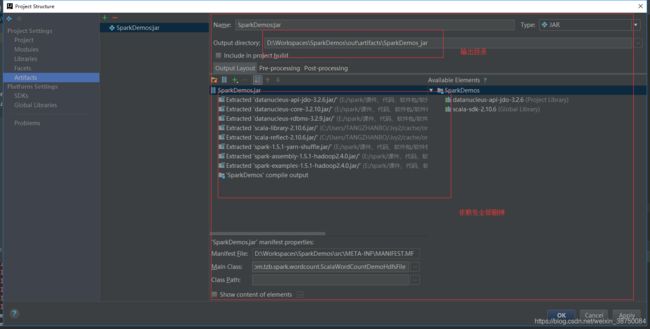
点击ok,然后:
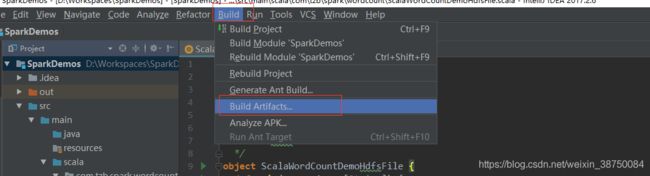
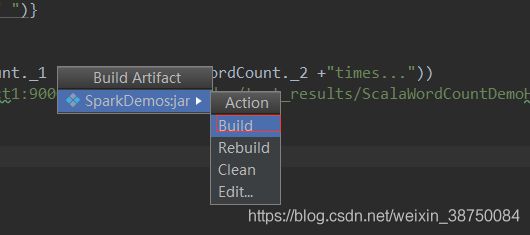
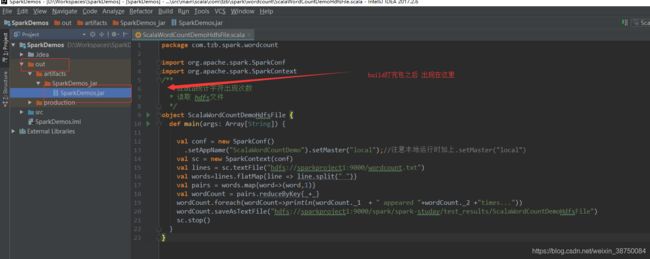
传到linux测试:
执行脚本:
scalaWordCountDemoHdfsFileIDEA.sh
/usr/local/spark/bin/spark-submit \
--class com.tzb.spark.wordcount.ScalaWordCountDemoHdfsFile \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 1 \
/usr/local/spark-study/test_jars/SparkDemos.jar \报错:
19/06/13 06:09:12 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 166 ms on localhost (1/1)
19/06/13 06:09:12 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/06/13 06:09:13 INFO scheduler.DAGScheduler: Job 0 finished: foreach at ScalaWordCountDemoHdfsFile.scala:19, took 1.594695 s
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://sparkproject1:9000/spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile already exists
at org.apache.hadoop.mapred.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:132)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply$mcV$sp(PairRDDFunctions.scala:1089)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1065)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1065)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:147)执行命令删除已存在的文件夹:
hadoop fs -rm -r -skipTrash /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile
[root@sparkproject1 test_sh]# hadoop fs -rm -r -skipTrash /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile
19/06/13 06:18:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Deleted /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile再次执行,则成功了:
./scalaWordCountDemoHdfsFileIDEA.sh
19/06/13 06:20:37 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1959 bytes)
19/06/13 06:20:37 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 1)
19/06/13 06:20:37 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/06/13 06:20:37 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 17 ms
scala appeared 1times...
spark appeared 1times...
hadoop appeared 1times...
hello appeared 4times...
java appeared 1times...
paython appeared 1times...
19/06/13 06:20:37 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/06/13 06:20:37 INFO scheduler.DAGScheduler: ResultStage 1 (foreach at ScalaWordCountDemoHdfsFile.scala:19) finished in 0.153 s
19/06/13 06:20:37 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 156 ms on localhost (1/1)
19/06/13 06:20:37 INFO scheduler.TaskSchedule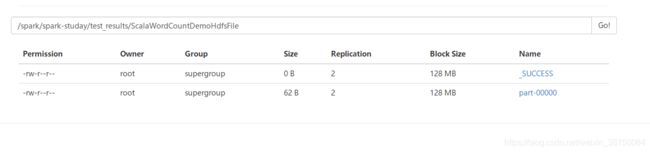
读取结果:
注意hadoop fs 和 hadoop dfs都 可以
[root@sparkproject1 test_sh]# hadoop fs -text /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile/part-00000
19/06/13 06:24:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(scala,1)
(spark,1)
(hadoop,1)
(hello,4)
(java,1)
(paython,1)
[root@sparkproject1 test_sh]# hadoop dfs -text /spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile/part-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
19/06/13 06:24:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(scala,1)
(spark,1)
(hadoop,1)
(hello,4)
(java,1)
(paython,1)
[root@sparkproject1 test_sh]#
完整日志:
[root@sparkproject1 test_sh]# ./scalaWordCountDemoHdfsFileIDEA.sh
19/06/13 06:20:21 INFO spark.SparkContext: Running Spark version 1.5.1
19/06/13 06:20:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/06/13 06:20:22 INFO spark.SecurityManager: Changing view acls to: root
19/06/13 06:20:22 INFO spark.SecurityManager: Changing modify acls to: root
19/06/13 06:20:22 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
19/06/13 06:20:24 INFO slf4j.Slf4jLogger: Slf4jLogger started
19/06/13 06:20:24 INFO Remoting: Starting remoting
19/06/13 06:20:25 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:52216]
19/06/13 06:20:25 INFO util.Utils: Successfully started service 'sparkDriver' on port 52216.
19/06/13 06:20:25 INFO spark.SparkEnv: Registering MapOutputTracker
19/06/13 06:20:25 INFO spark.SparkEnv: Registering BlockManagerMaster
19/06/13 06:20:25 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-6d271bdf-7a37-4272-b305-bfa39aa15dcb
19/06/13 06:20:25 INFO storage.MemoryStore: MemoryStore started with capacity 52.2 MB
19/06/13 06:20:25 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-681805de-e15d-4fb9-b512-6d2ea1ac6dad/httpd-95037a0b-8c12-44e8-9b0b-02cd093956b5
19/06/13 06:20:25 INFO spark.HttpServer: Starting HTTP Server
19/06/13 06:20:25 INFO server.Server: jetty-8.y.z-SNAPSHOT
19/06/13 06:20:25 INFO server.AbstractConnector: Started [email protected]:33495
19/06/13 06:20:25 INFO util.Utils: Successfully started service 'HTTP file server' on port 33495.
19/06/13 06:20:25 INFO spark.SparkEnv: Registering OutputCommitCoordinator
19/06/13 06:20:31 INFO server.Server: jetty-8.y.z-SNAPSHOT
19/06/13 06:20:31 INFO server.AbstractConnector: Started [email protected]:4040
19/06/13 06:20:31 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
19/06/13 06:20:31 INFO ui.SparkUI: Started SparkUI at http://192.168.124.100:4040
19/06/13 06:20:31 INFO spark.SparkContext: Added JAR file:/usr/local/spark-study/test_jars/SparkDemos.jar at http://192.168.124.100:33495/jars/SparkDemos.jar with timestamp 1560378031277
19/06/13 06:20:31 WARN metrics.MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
19/06/13 06:20:31 INFO executor.Executor: Starting executor ID driver on host localhost
19/06/13 06:20:31 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39473.
19/06/13 06:20:31 INFO netty.NettyBlockTransferService: Server created on 39473
19/06/13 06:20:32 INFO storage.BlockManagerMaster: Trying to register BlockManager
19/06/13 06:20:32 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:39473 with 52.2 MB RAM, BlockManagerId(driver, localhost, 39473)
19/06/13 06:20:32 INFO storage.BlockManagerMaster: Registered BlockManager
19/06/13 06:20:33 WARN util.SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
19/06/13 06:20:33 INFO storage.MemoryStore: ensureFreeSpace(137584) called with curMem=0, maxMem=54747463
19/06/13 06:20:33 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 134.4 KB, free 52.1 MB)
19/06/13 06:20:34 INFO storage.MemoryStore: ensureFreeSpace(12812) called with curMem=137584, maxMem=54747463
19/06/13 06:20:34 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 12.5 KB, free 52.1 MB)
19/06/13 06:20:34 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:39473 (size: 12.5 KB, free: 52.2 MB)
19/06/13 06:20:34 INFO spark.SparkContext: Created broadcast 0 from textFile at ScalaWordCountDemoHdfsFile.scala:15
19/06/13 06:20:35 INFO mapred.FileInputFormat: Total input paths to process : 1
19/06/13 06:20:36 INFO spark.SparkContext: Starting job: foreach at ScalaWordCountDemoHdfsFile.scala:19
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Registering RDD 3 (map at ScalaWordCountDemoHdfsFile.scala:17)
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Got job 0 (foreach at ScalaWordCountDemoHdfsFile.scala:19) with 1 output partitions
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Final stage: ResultStage 1(foreach at ScalaWordCountDemoHdfsFile.scala:19)
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at ScalaWordCountDemoHdfsFile.scala:17), which has no missing parents
19/06/13 06:20:36 INFO storage.MemoryStore: ensureFreeSpace(4152) called with curMem=150396, maxMem=54747463
19/06/13 06:20:36 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 52.1 MB)
19/06/13 06:20:36 INFO storage.MemoryStore: ensureFreeSpace(2321) called with curMem=154548, maxMem=54747463
19/06/13 06:20:36 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 52.1 MB)
19/06/13 06:20:36 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:39473 (size: 2.3 KB, free: 52.2 MB)
19/06/13 06:20:36 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:861
19/06/13 06:20:36 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at ScalaWordCountDemoHdfsFile.scala:17)
19/06/13 06:20:36 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
19/06/13 06:20:36 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 2195 bytes)
19/06/13 06:20:36 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
19/06/13 06:20:36 INFO executor.Executor: Fetching http://192.168.124.100:33495/jars/SparkDemos.jar with timestamp 1560378031277
19/06/13 06:20:36 INFO util.Utils: Fetching http://192.168.124.100:33495/jars/SparkDemos.jar to /tmp/spark-681805de-e15d-4fb9-b512-6d2ea1ac6dad/userFiles-f594246a-977c-4589-9c9e-6c1b4f0d4292/fetchFileTemp8865284365614466296.tmp
19/06/13 06:20:36 INFO executor.Executor: Adding file:/tmp/spark-681805de-e15d-4fb9-b512-6d2ea1ac6dad/userFiles-f594246a-977c-4589-9c9e-6c1b4f0d4292/SparkDemos.jar to class loader
19/06/13 06:20:36 INFO rdd.HadoopRDD: Input split: hdfs://sparkproject1:9000/wordcount.txt:0+56
19/06/13 06:20:36 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
19/06/13 06:20:36 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
19/06/13 06:20:36 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
19/06/13 06:20:36 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
19/06/13 06:20:36 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
19/06/13 06:20:37 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver
19/06/13 06:20:37 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 875 ms on localhost (1/1)
19/06/13 06:20:37 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/06/13 06:20:37 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (map at ScalaWordCountDemoHdfsFile.scala:17) finished in 0.979 s
19/06/13 06:20:37 INFO scheduler.DAGScheduler: looking for newly runnable stages
19/06/13 06:20:37 INFO scheduler.DAGScheduler: running: Set()
19/06/13 06:20:37 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1)
19/06/13 06:20:37 INFO scheduler.DAGScheduler: failed: Set()
19/06/13 06:20:37 INFO scheduler.DAGScheduler: Missing parents for ResultStage 1: List()
19/06/13 06:20:37 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at ScalaWordCountDemoHdfsFile.scala:18), which is now runnable
19/06/13 06:20:37 INFO storage.MemoryStore: ensureFreeSpace(2264) called with curMem=156869, maxMem=54747463
19/06/13 06:20:37 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.2 KB, free 52.1 MB)
19/06/13 06:20:37 INFO storage.MemoryStore: ensureFreeSpace(1400) called with curMem=159133, maxMem=54747463
19/06/13 06:20:37 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1400.0 B, free 52.1 MB)
19/06/13 06:20:37 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:39473 (size: 1400.0 B, free: 52.2 MB)
19/06/13 06:20:37 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:861
19/06/13 06:20:37 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at ScalaWordCountDemoHdfsFile.scala:18)
19/06/13 06:20:37 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
19/06/13 06:20:37 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1959 bytes)
19/06/13 06:20:37 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 1)
19/06/13 06:20:37 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/06/13 06:20:37 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 17 ms
scala appeared 1times...
spark appeared 1times...
hadoop appeared 1times...
hello appeared 4times...
java appeared 1times...
paython appeared 1times...
19/06/13 06:20:37 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/06/13 06:20:37 INFO scheduler.DAGScheduler: ResultStage 1 (foreach at ScalaWordCountDemoHdfsFile.scala:19) finished in 0.153 s
19/06/13 06:20:37 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 156 ms on localhost (1/1)
19/06/13 06:20:37 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/06/13 06:20:37 INFO scheduler.DAGScheduler: Job 0 finished: foreach at ScalaWordCountDemoHdfsFile.scala:19, took 1.637427 s
19/06/13 06:20:38 INFO storage.BlockManagerInfo: Removed broadcast_2_piece0 on localhost:39473 in memory (size: 1400.0 B, free: 52.2 MB)
19/06/13 06:20:38 INFO spark.ContextCleaner: Cleaned accumulator 2
19/06/13 06:20:38 INFO storage.BlockManagerInfo: Removed broadcast_1_piece0 on localhost:39473 in memory (size: 2.3 KB, free: 52.2 MB)
19/06/13 06:20:38 INFO spark.ContextCleaner: Cleaned accumulator 1
19/06/13 06:20:38 INFO spark.SparkContext: Starting job: saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20
19/06/13 06:20:38 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 143 bytes
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Got job 1 (saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20) with 1 output partitions
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Final stage: ResultStage 3(saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20)
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 2)
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Missing parents: List()
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Submitting ResultStage 3 (MapPartitionsRDD[5] at saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20), which has no missing parents
19/06/13 06:20:38 INFO storage.MemoryStore: ensureFreeSpace(113216) called with curMem=150396, maxMem=54747463
19/06/13 06:20:38 INFO storage.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 110.6 KB, free 52.0 MB)
19/06/13 06:20:38 INFO storage.MemoryStore: ensureFreeSpace(38400) called with curMem=263612, maxMem=54747463
19/06/13 06:20:38 INFO storage.MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 37.5 KB, free 51.9 MB)
19/06/13 06:20:38 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on localhost:39473 (size: 37.5 KB, free: 52.2 MB)
19/06/13 06:20:38 INFO spark.SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:861
19/06/13 06:20:38 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 3 (MapPartitionsRDD[5] at saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20)
19/06/13 06:20:38 INFO scheduler.TaskSchedulerImpl: Adding task set 3.0 with 1 tasks
19/06/13 06:20:38 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 3.0 (TID 2, localhost, PROCESS_LOCAL, 1959 bytes)
19/06/13 06:20:38 INFO executor.Executor: Running task 0.0 in stage 3.0 (TID 2)
19/06/13 06:20:38 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/06/13 06:20:38 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 1 ms
19/06/13 06:20:39 INFO output.FileOutputCommitter: Saved output of task 'attempt_201906130620_0003_m_000000_2' to hdfs://sparkproject1:9000/spark/spark-studay/test_results/ScalaWordCountDemoHdfsFile/_temporary/0/task_201906130620_0003_m_000000
19/06/13 06:20:39 INFO mapred.SparkHadoopMapRedUtil: attempt_201906130620_0003_m_000000_2: Committed
19/06/13 06:20:39 INFO executor.Executor: Finished task 0.0 in stage 3.0 (TID 2). 1165 bytes result sent to driver
19/06/13 06:20:39 INFO scheduler.DAGScheduler: ResultStage 3 (saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20) finished in 0.677 s
19/06/13 06:20:39 INFO scheduler.DAGScheduler: Job 1 finished: saveAsTextFile at ScalaWordCountDemoHdfsFile.scala:20, took 0.777526 s
19/06/13 06:20:39 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 3.0 (TID 2) in 679 ms on localhost (1/1)
19/06/13 06:20:39 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
19/06/13 06:20:39 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
19/06/13 06:20:39 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.124.100:4040
19/06/13 06:20:39 INFO scheduler.DAGScheduler: Stopping DAGScheduler
19/06/13 06:20:39 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
19/06/13 06:20:39 INFO storage.MemoryStore: MemoryStore cleared
19/06/13 06:20:39 INFO storage.BlockManager: BlockManager stopped
19/06/13 06:20:39 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
19/06/13 06:20:39 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
19/06/13 06:20:39 INFO spark.SparkContext: Successfully stopped SparkContext
19/06/13 06:20:39 INFO util.ShutdownHookManager: Shutdown hook called
19/06/13 06:20:39 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-681805de-e15d-4fb9-b512-6d2ea1ac6dad
19/06/13 06:20:39 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
19/06/13 06:20:39 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
[root@sparkproject1 test_sh]#