windows下使用idea maven配置spark运行环境、运行WordCount例子以及碰到的问题
一、安装JAVA JDK 、Maven 、scala
这些安装都比较简单都可以去官网下载最新版本的安装包一一安装就可以了。
scala官网下载地址:http://www.scala-lang.org/download/
二、安装idea scala 插件
setting—>plugins页面点击下面的角Browse repositories… 选项搜素scala点击安装。
这里面不建议在线安装插件,建议根据Updated 2014/12/18去下载离线的scala插件,比如本文中的IDEA Updated日期是2014/12/18然后找到对应的插件版本是1.2.1,下载即可。下面是scala插件的离线下载地址。 scala插件离线下载地址:https://plugins.jetbrains.com/plugin/1347-scala
然后根据Update日期去找Intellij IDEA对应得scala插件,不同版本的IDEA对应的scala插件不一样,请务必下载对应的scala插件否则无法识别。
离线插件下载完成后,将离线scala插件通过如下方式加入到IDEA中去:点击Install plugin from disk…,然后找到你scala插件的zip文件的本机磁盘位置,点ok即可
三、Intellij IDEA通过Maven搭建spark环境
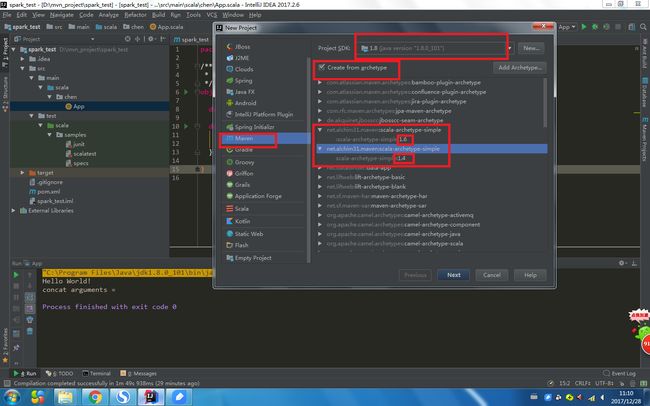
- (1)打开IDEA新建一个maven项目。
依次选择file-->new project--->maven 点击create from archetyep,选择scala-archetype—simple插件(有可能版本不对会造成问题,文章后面有解决办法。)
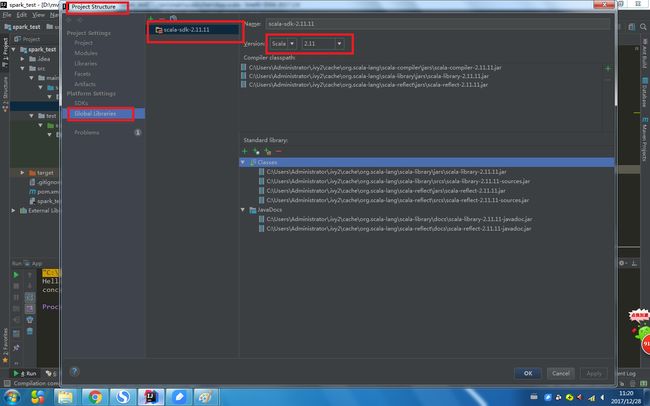
- (2)添加scala sdk。 file-->project structure-->global libaraies选择scala对应版本,千万要对应不然会造成编译代码的通不过。
四、碰到的一些问题的解决
1.编译时idea报错:Error:scalac: error while loading JUnit4, Scala signature
Error:scalac: error while loading JUnit4, Scala signature
JUnit4 has wrong version
expected: 5.0
found: 4.1 in JUnit4.class这个错误是由于我是直接用的maven提供的模版,而没有注意Archetype中的版本问题。各版本一定要注意对应,解决方法是点击Add Archetype, 添加新的scala-archetype-simple,填写GAV, groupID:net.alchim31.maven ArtifactID:scala-archetype-simple Version:1.4 如果还有问题,去maven仓库找合适的版本http://mvnrepository.com
2.scala报错:scala error:bad option ‘-make:transitive
scala报错:scala error:bad option ‘-make:transitivescala版本问题,scala2.11不支持make参数,将pom.xml中的这个参数去掉即可解决
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>3.ShouldMatchers is not a member of package org.scalatest
编译的时候报这些错误,就jar包没有加载好,去maven仓库找scala版本对应的jar包,参考如下:
<properties>
<maven.compiler.source>1.6maven.compiler.source>
<maven.compiler.target>1.6maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.11scala.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.11version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.specs2groupId>
<artifactId>specs2-core_2.12artifactId>
<version>4.0.2version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.specs2groupId>
<artifactId>specs2-junit_2.12artifactId>
<version>3.8.9version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.specs2groupId>
<artifactId>specs2_2.11artifactId>
<version>3.3.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.scalatestgroupId>
<artifactId>scalatest_2.11artifactId>
<version>3.0.1-SNAP1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.scalatestgroupId>
<artifactId>scalatest-funspec_2.11artifactId>
<version>3.0.0-SNAP13version>
dependency>
<dependency>
<groupId>org.scalatestgroupId>
<artifactId>scalatest_2.12artifactId>
<version>3.2.0-SNAP7version>
<scope>testscope>
dependency>
dependencies>4、Failed to execute goal org.apache.maven.plugins:maven-archetype-plugin:3.0.1:generate (default-cli) on project standalone-pom: The desired archetype does not exist (net.alchim31.maven::scala-archetype-simple:1.6 ) -> [Help 1]
Failed to execute goal org.apache.maven.plugins:maven-archetype-plugin:3.0.1:generate (default-cli) on project standalone-pom: The desired archetype does not exist (net.alchim31.maven::scala-archetype-simple:1.6 ) -> [Help 1]-
JAVA_HOME没有设置或者设置有误、amven_home设置有误
-
删除/org/apache/maven/plugins/下的maven-archetype-plugin
-
maven-archetype-plugin 2.3版本的插件有问题,换其它版本进行创建(方案可行)
更新 maven-archetype-plugin版本:
造成这个问题是版本不对maven-archetype-plugin,参考上面的问题1的解决办法: 这个错误是由于我是直接用的maven提供的模版,而没有注意Archetype中的版本问题。各版本一定要注意对应,解决方法是点击在创建maven项目的选择archetype的时候点击Add Archetype, 添加新的scala-archetype-simple,填写GAV, groupID:net.alchim31.maven ArtifactID:scala-archetype-simple Version:1.4 如果还有问题,去maven仓库找合适的版本http://mvnrepository.com
5.spark saveAsTextFile保存到文件
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
解决参考链接:http://blog.csdn.net/kimyoungvon/article/details/51308651
下载地址:winutils.exe:https://github.com/srccodes/hadoop-common-2.2.0-bin
我的解决方法:
下载winutils.exe和hadoop.dll文件,hadoop.dll文件放到system32下面,winutils.exe放到C:\hadoop_home\bin文件夹下,然后设置代码: 在代码中添加:
System.setProperty ("hadoop.home.dir", "C:\\hadoop_home\\")五、运行WordCount例子。 我是使用scala版本是2.11 spark版本是,下面是我pom.xml以供参考:
<properties>
<maven.compiler.source>1.6maven.compiler.source>
<maven.compiler.target>1.6maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.11scala.version>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<spark.version>2.1.0spark.version>
<scala.version>2.11.11scala.version>
<hadoop.version>2.7.0hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.0version>
dependency>
..............
..............wordcount代码:
package chen
import org.apache.spark._
object WordCount {
System.setProperty ("hadoop.home.dir", "C:\\hadoop_home\\")
def main(args: Array[String]) {
var masterUrl = "local[1]"
var inputPath = "D:\\spark_data\\data.txt"
var outputPath = "D:\\spark_data\\output"
if (args.length == 1) {
masterUrl = args(0)
} else if (args.length == 3) {
masterUrl = args(0)
inputPath = args(1)
outputPath = args(2)
}
println(s"masterUrl:${masterUrl}, inputPath: ${inputPath}, outputPath: ${outputPath}")
val sparkConf = new SparkConf().setMaster(masterUrl).setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val rowRdd = sc.textFile(inputPath)
val resultRdd = rowRdd.flatMap(line => line.split("\\s+"))
.map(word => (word, 1)).reduceByKey(_ + _)
resultRdd.saveAsTextFile(outputPath)
}
}data.txt:
chen chenxun sb
chenxun
chenliiii
jjjjjjjjjj
ddd
jjjjjjjjjj
jjjjjjjjjj jjjjjjjjj
chenxun chen chenxun chen chen chen在output目录下看到一些文件:
part-00000
_SUCCESS
.part-00000.crc
._SUCCESS.crc打开part-00000看到spark计算结果:
(chenxun,4)
(sb,1)
(ddd,1)
(jjjjjjjjjj,3)
(jjjjjjjjj,1)
(chen,5)
(chenliiii,1)