paper survey(2019.06.23)——Multi-Scale
类似于之前的paper调研的论文,本博文主要是对于multi-scale在low-level-vision中的应用做调研
《Down-Scaling with Learned Kernels in Multi-Scale Deep Neural Networks for Non-Uniform Single Image》
论文开篇提到“Multi-scale approach has been used for blind image video deblurring problems to yield excellent performance for both conventional and recent deep-learning-based state-of-the-art methods.”看来在deblur领域multi-scale应用较为广泛。那么对于去模糊的任务,multi scale是有效的,那在其他low-level-vision任务上也应该有效
propose convolutional neural network (CNN)-based down-scale methods for multi-scale deep-learning-based non-uniform single image deblurring.
对于模糊问题的建模(这也是熟知的公式啦~)

目前去模糊有两类: One is to use neural networks to explicitly estimate non-uniform blurs G and the other is to use networks to directly estimate the original sharp image x without estimating blurs
之前三篇跟multi-scale相关的博客的方法则是直接恢复sharp image,are using so-called multi-scale (coarse-to-fine) approaches with down-scaled image(s).
There are two types of generating down-scaled image (or information): 1) down-sampling after filtering with a fixed kernel such as Gaussian or bicubic so that local information will be encoded with reduced spatial dimension and 2) down-scaling with deep neural networks so that global information will be encoded with further reduced spatial dimension.
contributions:
1、we propose a novel convolutional neural network (CNN)-based down-scaling method that is in between conventional downsampling methods with fixed kernel and recent deep neural network based methods with global information encoding.
2、We argue that our CNN-based down-scaling allows to perform spatial dimension reduction (空间尺寸缩减) with learned kernels to encode local information such as strong edges and keeps the number of channels at each scale so that too much global information is not encoded locally after downscaling.
3、With our CNN-based down-scaling modules, we propose a deep multi-scale single image deblurring network based on RCAN (Residual Channel Attention Networks) that is a state-of-the-art method for super resolution as a backbone network.
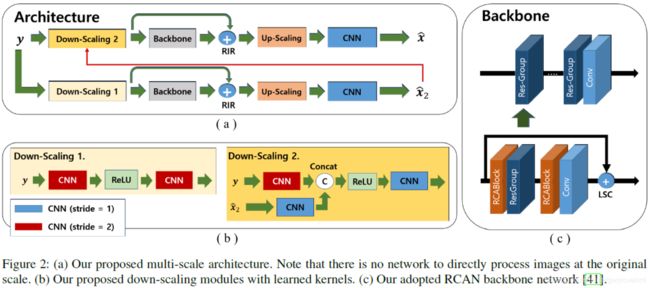
对于传统的bicubic 下采样,due to the fixed kernel, some important high-frequency information for deblurring may be removed to avoid aliasing.For example, it is well-known that strong edges help to reliably estimate blur kernels, thus it may be beneficial to preserve some of these high-frequency details even in down-scaled information for deblurring.
所以作者采用了CNN网络来实现下采样。We propose CNN-based down-scaling modules instead of using conventional down-sampling.
《Single Image Blind Deblurring Using Multi-Scale Latent Structure Prior》
Latent(潜在)
we propose to restore sharp images from the coarsest scale to the finest scale on a blurry image pyramid, and progressively update the prior image using the newly restored sharp image. These coarse-to-fine priors are referred to as Multi-Scale Latent Structures (MSLS). Leveraging the MSLS prior, our algorithm comprises two phases: 1) we first preliminarily restore sharp images in the coarse scales; 2) we then apply a refinement process in the finest scale to obtain the final deblurred image.
这篇论文是非CNN的,所以后面就不再看了~
《Hybrid Function Sparse Representation towards Image Super Resolution》
Multi-scale renement is then proposed to utilize the scalable property of the dictionary to improve the results.
In this paper, we propose hybrid function sparse representation(混合函数稀疏表示) (HFSR), which uses function-based dictionary to replace conventional training-based dictionary.
《Multi-scale deep neural networks for real image super-resolution》
(这篇论文是今年cvpr19超分比赛的paper,针对今年的数据集,通过multi-scale来解决真实图片的超分问题。这篇论文好像只排21名?那应该只是挂到arvix上~~~)
Firstly, due to the high computation complexity in high-resolution spaces, we process an input image mainly in two different downscaling spaces, which could greatly lower the usage of GPU memory.
Then, to reconstruct the details of an image, we design a multi-scale residual network (MsRN) in the downscaling spaces based on the residual blocks.
Besides, we propose a multi-scale dense network based on the dense blocks to compare with MsRN.
In reality, images are often obtained by different kinds of cameras. Besides, to reconstruct the SR image with high quality, the upscaling factors of close-shot and long-shot could be different. Overall, the challenge of realistic image SR is that we need to develop a method which has generalization capacity to both the upscaling factors and downscaling operators.
Multiscale residual networks
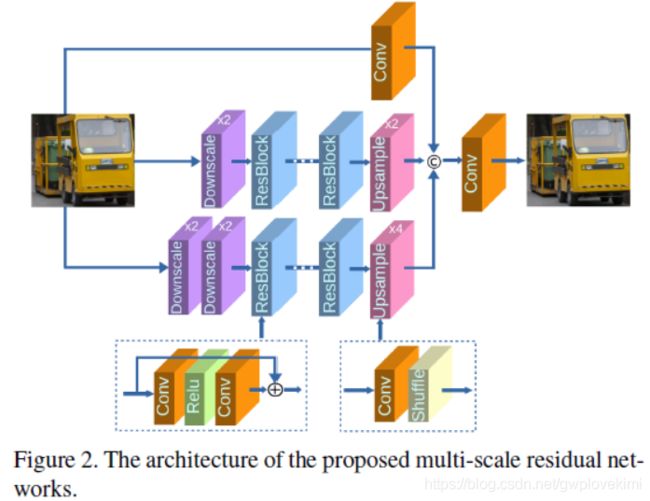
Multiscale dense networks


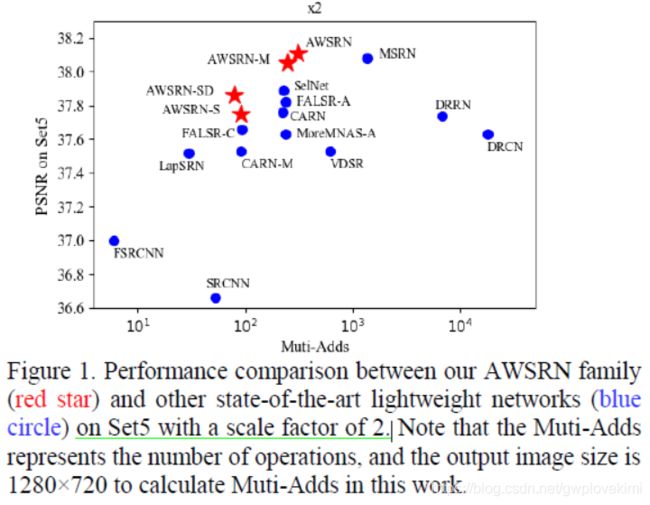
《Lightweight Image Super-Resolution with Adaptive Weighted Learning Network》
In this work, a lightweight SR network, named Adaptive Weighted Super-Resolution Network (AWSRN), is proposed for SISR to address this issue. A novel local fusion block (LFB) is designed in AWSRN for efficient residual learning, which consists of stacked adaptive weighted residual units (AWRU) and a local residual fusion unit (LRFU).Moreover, an adaptive weighted multi scale (AWMS) module is proposed to make full use of features in reconstruction layer. AWMS consists of several different scale convolutions, and the redundancy(冗余) scale branch can be removed according to the contribution of adaptive weights in AWMS for lightweight network.
Moreover, most SR networks only have a single-scale reconstruction layer with convolution, transposed convolution or subpixelshuffle, resulting in insufficiently used feature information from the nonlinear mapping module. Although the way of multi-scale reconstruction provides more information, it induces more parameters which result in large number of computational operations.
Contributions:
1、propose an adaptive weighted local fusion block (LFB) in the nonlinear mapping module, which consists of multiple adaptive weighted residual units (AWRUs) and a local residual fusion unit (LRFU) as shown in Figure 2. The adaptive learning weights in AWRU can help the flow of information and gradients more efficiently and effectively, while LRFU can effectively fuse multi-level residual information in LFB.
2、We propose an AWMS reconstruction module, which can make full use of the features from nonlinear mapping module to improve the reconstruction quality. Moreover, the redundant scale branches can be removed according to the weighted contribution to further reduce network parameters.
3、The proposed lightweight AWSRN achieves superior SR reconstruction performance compared to state-of-the-art CNN-based SISR algorithms. As shown in Figure 1, the proposed AWSRN algorithm achieves state-of-the-art performance on Set5 with a scale factor of 2. Moreover, the AWSRN family has a good trade-off between reconstruction performance and the number of operations
网络结构如下所示:
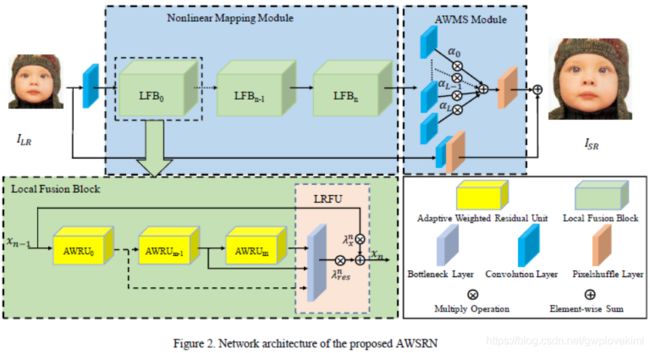
这篇论文有种连连看的感觉~我就没有再深入探究其网络结构了~
《Image Super-Resolution by Neural Texture Transfer》
Neural Texture Transfer(神经纹理转移)
Reference-based super-resolution (RefSR),
be promising in recovering high-resolution (HR) details when a reference (Ref) image with similar content as that of the LR input is given.unleash(释放) the potential of RefSR by leveraging more texture details from Ref images with stronger robustness even when irrelevant Ref images are provided. we formulate the RefSR problem as neural texture transfer. We design an end-to-end deep model which enriches HR details by adaptively transferring the texture from Ref images according to their textural similarity.
RefSR utilizes rich textures from the HR references (Ref) to compensate for the lost details in the LR images, relaxing the ill-posed issue and producing more detailed and realistic textures with the help of reference images.
we propose a new RefSR algorithm, named Super-Resolution by Neural Texture Transfer (SRNTT), which adaptively transfers textures from the Ref images to the SR image. More specifically, SRNTT conducts local texture matching in the feature space and transfers matched textures to the final output through a deep model. The texture transfer model learns the complicated dependency between LR and Ref textures, and leverages(杠杆) similar textures while suppressing dissimilar textures(不同的纹理).

In contrast to SISR where only a single LR image is used as input, RefSR methods introduce additional images to assist the SR process. In general, the reference images need to possess similar texture and/or content structure with the LR image. The references could be selected from adjacent frames in a video, images from web retrieval(web检索), an external database (dictionary) , or images from different view points.
本文借鉴图像风格化 (image stylization)中神经纹理迁移(Neural Texture Transfer)思想,利用参考图像中的纹理,弥补低分辨率图像的细节信息。本文方法主要包括两步:1)特征空间的纹理匹配,2)移匹配的纹理。另外,本文提出一个CUFFED5数据集,这个数据集包含不同相似级别的参考图像。
对于传统的SISR问题,虽然使用感知相关的约束,比如感知损失(perceptual loss)和对抗损失(adversarial loss)能提升图像质量,使图像看起来更清晰,但是会生假的纹理(hallucinate fake textures)和人工的特征(artifacts)。也就是说,使用感知损失常常得不到真实的纹理细节信息。
基于参考(reference-based)的方法, 即RefSR,通过利用高分辨率(HR)参考图像的丰富纹理来补偿低分辨率(LR)图像丢失的细节。但是之前的方法需要参考图像与LR包含相似的内容,并且需要图像对齐,否则的话,这些方法效果会很差。RefSR理想上应该可以有效利用参考图像,如果参考图像与LR不同,也不应该损害LR的复原效果,即RefSR应不差于SISR。
为了解决传统RefSR的缺点,本文不需要图像对齐,而是通过在特征空间上匹配的方法,将语义相关的特征进行迁移·。
SRNTT整体框架,主要包含局部纹理特征匹配(交换)和纹理迁移两部分:
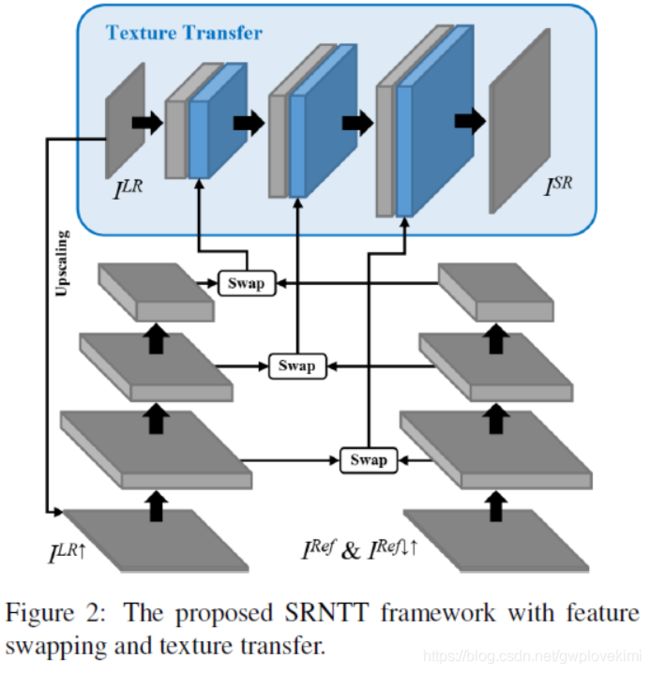
(这是一篇比较有趣的论文,但好像跟我目前调研的方向不太吻合,后面再来细看)
参考资料:
https://blog.csdn.net/muyiyushan/article/details/88752720
https://blog.csdn.net/wangchy29/article/details/88566724
https://cloud.tencent.com/developer/article/1411180
《Extreme Channel Prior Embedded Network for Dynamic Scene Deblurring》
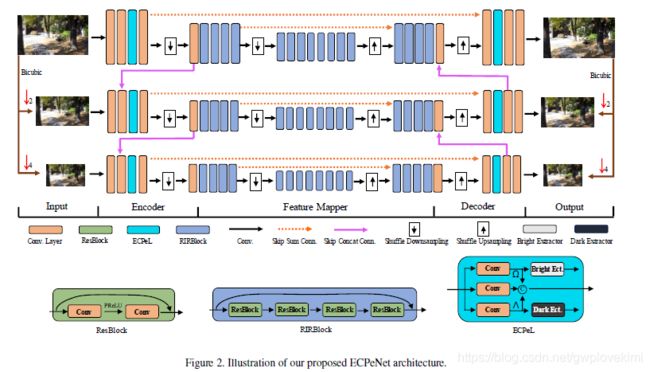
In this work, we propose an Extreme Channel Prior embedded Network (ECPeNet) to plug the extreme channel priors (i.e., priors on dark and bright channels) into a network architecture for effective dynamic scene deblurring. A novel trainable extreme channel prior embedded layer (ECPeL) is developed to aggregate both extreme channel and blurry image representations, and sparse regularization is introduced to regularize the ECPeNet model learning.Furthermore, we present an effective multi-scale network architecture that works in both coarse-to-fine and fine-to- coarse manners for better exploiting information flow across scales.
目前大多数用multi-scale方法的deblur大多数都是:Furthermore, existing deep dynamic scene deblurring models usually adopt multi-scale network architecture but only consider the coarse-to-fine information flow. That is, blind deblurring is first performed at the small scale, and then deblurring results (or latent representations) are combined with feature representations of a larger scale for further refinement. However, we show that feature representations of a larger scale actually also benefit the dynamic scene deblurring at a smaller scale.To this end, we present a more effective multi-scale network architecture that works in both coarse-to-fine and fine-to-coarse manners for better exploiting information flow across scales.之前看过的deblur的论文都是从细scale到large scale,但是这篇论文则是两个方向都走。
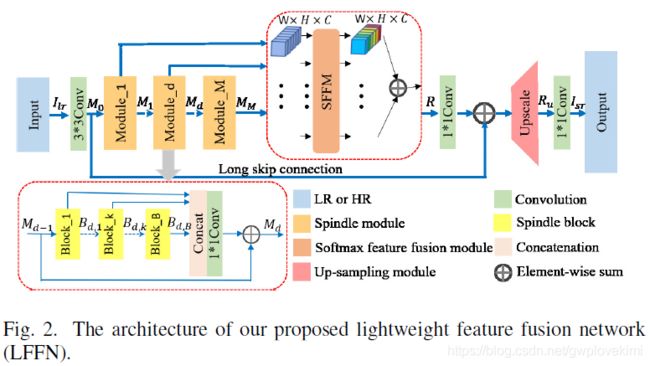
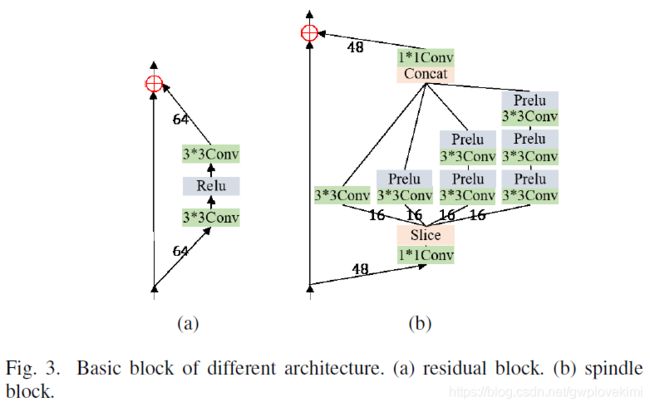
《Lightweight Feature Fusion Network for Single Image Super-Resolution》
We propose a lightweight feature fusion network (LFFN) that can fully explore multi-scale contextual information and greatly reduce network parameters while maximizing SISR results. LFFN is built on spindle (纺锤) blocks and a softmax feature fusion module (SFFM).Specifically, a spindle block is composed of a dimension extension unit, a feature exploration unit and a feature refinement unit. The dimension extension layer expands low dimension to high dimension and implicitly (隐式) learns the feature maps which is suitable for the next unit. The feature exploration unit performs linear and nonlinear feature exploration aimed at different feature maps. The feature refinement layer is used to fuse and refine features. SFFM fuses the features from different modules in a self-adaptive learning manner with softmax function, making full use of hierarchical (分级)information with a small amount of parameter cost.
《A Multiscale Image Denoising Algorithm Based On Dilated Residual Convolution Network》
Dilated Convolution可以算是一种既不会导致信息丢失,有可以提升感受野的方法
Model-based optimization methods are flexible for handling different inverse problems but are usually time-consuming. In contrast, deep learning methods have fast testing speed but the performance of these CNNs is still inferior.
《Multi-Scale Recursive and Perception-Distortion Controllable Image Super{Resolution》
Perception-Distortion(感知失真)
这次看的大多数是arxiv上的论文,质量好多都很一般。。。。
《U-Finger: Multi-Scale Dilated Convolutional Network for Fingerprint Image Denoising and Inpainting》
这篇论文比较有实际意义
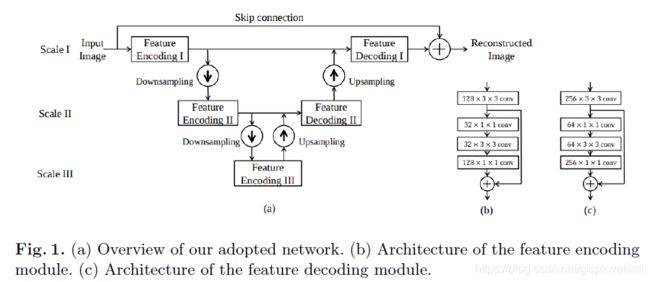
《Hyperspectral Image Denoising Employing a Spatial-Spectral Deep Residual Convolutional Neural Network》
Hyperspectral (高光谱)