【Python学习】python学习手册--第七章 字符串
Python中的字符串与其他语言中的字符串类型相似,它可以保存文本与符号信息。与c/c++语言不一样的是,Python中没有单个字符的类型(char),只有单个字符的字符串(单个字符也算作字符串)。Python中的字符串也是属于一种Python中稍大一类的对象类型——序列的代表
字符串常量
>>> "Learning ' Harder" # 双引号下的字符串
"Learning ' Harder"
>>> ' Keep " learning ' # 单引号下的字符串
' Keep " learning '
>>> 'Learning ' daily ' # 字符串中不能有多余的单引号
File "", line 1
' Learning ' daily '
^
SyntaxError: invalid syntax
>>> 'Learning \' daily ' #除非用转义字符
"Learning ' daily "
#原始字符串r字母在字符串之前,表示该字符串是原始字符(引号内的全为字符串,不存在转义字符)
>>> r"Learning \' daily "
"Learning \\' daily "
>>> - 单双引号中的字符串是一样的,同样的字符内容,在单引号和双引号内都表示同样的字符串,并无差别。
- 单引号中的字符串可以包含双引号,反之亦然。
- 字符串可以用“+”号来合并不同字符串的内容
- 反斜杠(转义字符)可以引入特殊的字节编码,能够让我们嵌入不能通过键盘键入的字符,如回车符,制表符。
- raw字符串可以抑制转义字符,在windows下表示路径时,很常见。事实上,当使用raw字符来表示字符串时,碰到转义字符会自动加上反斜杠在字符串中表示出”\”字符。
- 三引号用来表示字符块,字符串中的回车符,在三引号中会自动转换成为换行符。三引号也常常用来当做文档字符串,当它出现在特定地点的时候,会被当做注释一样的字符串。也可以用来注释掉无用代码。
字符串的基本操作
>>> lxm="Python"
>>> lxm*8
'PythonPythonPythonPythonPythonPythonPythonPython'
>>> lxm2="Learning "
>>> lxm2+lxm
'Learning Python'
>>> for c in lxm2:
... print(c,end=' ')
...
L e a r n i n g
>>> for循环语句指派一个变量,去获取一个序列中的元素,并对每个元素执行for循环中的语句。变量c就成为了获取序列中元素的指针。
索引和分片
字符串是序列,是字符的有序集合,这种情况下,我们就可以使用索引(偏移量)来提取相应位置上的元素。Python还支持负索引,从技术上讲,负索引指向的是这个负数加上整个字符串长度,得到正的偏移量。
>>> lxm="Learning"
>>> lxm[0]
'L'
>>> lxm[-2]
'n'
>>> lxm[-1]
'g'
>>> lxm[0:3]
'Lea'
>>> lxm[0:-2] #切片:从0至-2(不包含-2)的偏移所有字符串
'Learni'
>>> 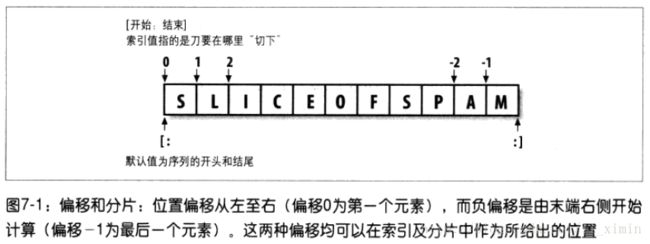
- 索引S[i]:获取特定偏移的元素。
- 第一个元素的偏移为0
- 负偏移意味着从字符串末端向前偏移。最后一位为-1。
- 分片S[i:j]:提取相应一部分子序列生成新对象。
- 上边界S[j]并不包含在新对象内
- 下边界S[i]包含在新对象内
- 分界的边界默认(如果没给出i,j的值,表示为S[:])为0和整个字符串的长度,即把整个字符串进行了拷贝,例如S[:j] 与 S[0:j]效果一致,S[i:]与S[i:len(S)]效果一致。
扩展分片:第三个限制值
当分片效果出出现了第三个限制值也叫做步长(Stride),那么完整形式的分片变成了S[i:j:k],表示在S序列中,从索引i取到索引j-1,每隔k个元素取一次得到的新对象。
>>> lxm[1:-1]
'earnin'
>>> lxm[1:-1:2]
'eri'
>>> lxm[1:-1:3]
'en'
>>> 当然第三个限制值也可以取负值,表示取值的方向相反,从序列尾部开始向前取值。
>>> lxm
'Learning'
>>> lxm[::-1]
'gninraeL'
>>> lxm[::-2]
'gire'
>>> lxm[::-3]
'gne'
>>> lxm[1:3:-1] #负步长时,前面的索引也应该调换顺序,不然不会输出任何新对象。
''
>>> lxm[3:1:-1] #步长-1,表示倒序切片,首尾索引调换顺序。
'ra'
>>> 字符串转换
>>> int('4321')
4321
>>> str(4321) # str函数直接创建字符串对象
'4321'
>>> repr(4321)
'4321'
>>> repr('str') # repr函数返回会多一层引号
"'str'"
>>> str('str')
'str'
>>> 字符串也可以转化成相应的内存中的二级制编码ASCII码,利用ord函数或chr函数:
>>> ord('a')
97
>>> ord('b') #将单个字符转换为相应的ascii码
98
>>> chr(98) #将ascii码转化为相应的字符
'b'
>>> chr(97)
'a'
>>> 字符串是不可变的对象,我们一般通过重新给变量名赋值来改变相应的变量引用的字符串,但是字符串对象本身并没有改变,只是新建了对象,重新赋值罢了。
>>> lxm
'Learning'
>>> lxm="Keep "+lxm # 每次这样的操作,都会生成一个新的字符串对象,并将这个新的字符串对象赋值给原理的变量名
>>> lxm
'Keep Learning'
>>> 字符串方法
方法的调用与面向对象编程方法一样,调用相应object对象中的属性(方法)attribute,可以写为object.attribute。首先指定对象,调用对象中的方法,传递参数,最后会返回相应的结果(或者在可变的对象上做相应的修改),因为字符串有不可变性,很多方法都是返回了相应的新对象:
>>> lxm.replace("Keep","Keeping")
'Keeping Learning'
>>> lxm # 并没有改变原来的变量所引用的对象
'Keep Learning'
>>> lxm.find("Lear")
5
>>> lxm.join(["You must "," harder"]) #将参数中的列表字符串合在一起,并用原字符串作为分隔符,隔开
'You must Keep Learning harder'
>>> lxm=lxm.join(["You must "," harder"])
>>> lxm
'You must Keep Learning harder'
>>> lxm.split(" ") # 将参数作为分隔符,把字符串分隔成若干个字符串列表
['You', 'must', 'Keep', 'Learning', 'harder']
>>> lxm.isdigit() # 判断是否是数字
False
>>> lxm.upper() #转化成为大写
'YOU MUST KEEP LEARNING HARDER'
>>> lxm.lower() #全部转化为小写
'you must keep learning harder'
>>> lxm.endswith("harder") #判断是否以"harder"结尾
True
>>> lxm.startswith("harder") #判断是否以"harder"开头
False
>>> lxm.find("harder") #查找"harder"字符串相应的起始索引位置
23
>>> lxm.find("No") #如果没找到则返回-1
-1
>>> 其它更多的字符串方法可以使用dir和help方法来了解。
字符串格式表达式
格式化字符串:
- 在%操作符左侧,放置一个需要进行格式化的字符串,在字符串中,有一个或若干个需要嵌入的转换目标,都以%开头,具体情况需要视嵌入对象的类型而定。(%s 表示字符串 %d表示整型等等)
- 在%操作符的右侧放置一个元组对象,元组中包含的对象,会依照先后顺序嵌入左侧的目标位置上去。
>>> "I have %d %s and I am %d years old"%(3,"dogs",27)
'I have 3 dogs and I am 27 years old'
>>> 格式化总是返回一个新的字符串对象作为结果,而不是在原有的字符串上进行修改

还有基于字典的格式化表达方式:
>>> lxm={"num":4,"sp":"cats","age":27}
>>> test="I have %(num)d %(sp)s and I am %(age)d years old"
>>> test%lxm
'I have 4 cats and I am 27 years old' 字符串格式化调用方法
字符串中有format方法,该方法使用主体字符串作为模板,方法的参数作为主体模板需要替换的值。主体字符串中,需要用花括号来表示需要替换的字符串的位置。
>>> test
'I have {num} {sp} and I am {age} years old'
>>> test.format(num=4,age=27,sp='cats') #通过关键字来替换字符串模板
'I have 4 cats and I am 27 years old'
>>> test='I have {0} {1} and I am {2} years old'
>>> test.format(4,'cats',27) #通过参数位置来替换字符串模板
'I have 4 cats and I am 27 years old'
>>> test='I have {num} {0} and I am {age} years old'
>>> test.format('cats',num=4,age=27) #两种方式一起使用
'I have 4 cats and I am 27 years old'
>>> 添加具体格式化
可以在格式化字符串模板中,添加额外的语法来实现更复杂的格式化需求:
模板中的花括号内的内容可以具体写成如下形式:
{fieldname!conversionflag:formatspec}
在这个式子中,它们分别是:
- fieldname是指定参数的关键字或者参数位置,后面可以跟上.name或者[index]来表示参数中嵌套的深层属性(比如参数是字典或列表)。
- conversionflag可以是r、s或a分别是该值对应repr,str或ascii内置函数的一次调用。
- Formatspec:指定如何表示该值,包括字段宽度,对齐方式,小数,补零,小数精度等细节。
具体的formatspec的形式描述如下:
[[fill]align][sign][#][0][width][.percision][typecode]
align可以是<,>,=或^,分别表示左对齐,右对齐,一个标记字符后的补充或居中对齐。更多替换语法请参考手册。
>>> "{0:>10}=={1:<10}".format('string','12342')
' string==12342 '
>>> "{0:<10}=={1:>10}".format('string','12342')
'string == 12342'
>>> "{0:^10}=={1:^10}".format('string','12342')
' string == 12342 '
>>> %格式化表达式在大部分时候使用起来更加方便,更容易编写。
为什么用新的格式化方法
- 拥有%表达式所没有的一些额外功能
- 可以更明确的进行替代引用
- 有一个更容易记忆的方法名
- 不支持用于单个和多个替代值大小写的不同语法
Python通常意义下的类型分类
在Python中主要有三种主要类型的分类:
- 数字:整数,浮点数,分数等
- 序列 :列表,字符串,元组
- 映射: 字典
集合是自成一体的分类。
Python中的核心类型又可以分为可变类和不可变类:
- 不可变类型,即不能在原来的对象上进行修改:数字,字符串元组,不可变集合
- 可变类型,可以在原来的对象上进行修改:列表,字典,可变集合
总结
本章讲述了Python的核心类型,字符串。字符串主要用来表示文本信息,Python中的字符串对象拥有很多常用的方法,可以提供给开发者快速使用。由于字符串是不可变的,这些方法往往是返回了一个新的字符串对象,如果要保存该对象,就需要用变量来引用该对象,以便程序下文使用。