【Andrew Ng 深度学习】(一)神经网络和深度学习
【Andrew Ng 深度学习】(一)神经网络和深度学习
- (一)神经网络和深度学习
- week 1. 深度学习概论
- 1.4 为什么深度学习会在近年来兴起
- week 2. 神经网络基础
- 2.2 - 2.3 logistics regression
- 2.4 梯度下降 - Gradient Descent
- 2.5 - 2.6 导数
- 2.7 计算图 - Computation Graph
- 2.8 计算图的导数计算
- 2.9 logistic 中的梯度下降法
- 2.10 m个样本的梯度下降法
- 2.11 - 2.12 向量化 - Vectorization
- 2.13 - 2.14 向量化 Logistics 回归
- 2.15 Python 中的广播
- 2.16 关于python/numpy向量的说明
- 2.17 Jupyter/Ipython 快速指南
- 2.18 logistic 损失函数的解释
- week 3. 浅层神经网络
- 3.1 - 3.5 神经网络表示、计算、向量化
- 3.6 激活函数
- 3.7 为什么需要非线性激活函数?
- 3.8 激活函数的导数
- 3.9* 神经网络的梯度下降法
- 3.10 (选修)直观理解反向传播
- 3.11 随机初始化
- week 4. 深层网络基础
- 4.1 - 4.2 深层神经网络
- 4.3 核对矩阵的维数
- 4.4 为什么使用深层表示
- 4.5 搭建深层神经网络块
- 4.6 前向和反向传播
- 4.7 参数VS超参数
返回目录
【2019-10-7】
(一)神经网络和深度学习
week 1. 深度学习概论
1.4 为什么深度学习会在近年来兴起
三个原因:
- Data
- Computation
- Algorithms
ReLU比Sigmoid效果好,因为sigmoid和tanh的gradient在饱和区域非常平缓,接近于0,很容易造成vanishing gradient的问题,减缓收敛速度。 ReLU为什么比Sigmoid效果好
week 2. 神经网络基础
2.2 - 2.3 logistics regression
- 逻辑回归损失函数 Loss function: L ( y ^ , y ) = − ( y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ) L(\hat y,y) = -(y \log \hat y + (1-y)\log{(1-\hat y)}) L(y^,y)=−(ylogy^+(1−y)log(1−y^))
直观地,
如果 y = 1 y=1 y=1, L ( y ^ , y ) = − log y ^ L(\hat y,y) = -\log \hat y L(y^,y)=−logy^;
如果 y = 0 y=0 y=0, L ( y ^ , y ) = − log ( 1 − y ^ ) L(\hat y,y) = -\log{(1-\hat y)} L(y^,y)=−log(1−y^)
(不使用 误差平方 L ( y ^ , y ) = 1 2 ( y ^ − y ) 2 L(\hat y,y) = \frac{1}{2} (\hat y - y)^2 L(y^,y)=21(y^−y)2作为损失:因为非凸,很多个局部最优,梯度下降不好用) - 成本函数 Cost function: J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) J(w,b)=\frac{1}{m} \sum_{i=1}^m{L(\hat y^{(i)},y^{(i)})} J(w,b)=m1∑i=1mL(y^(i),y(i))
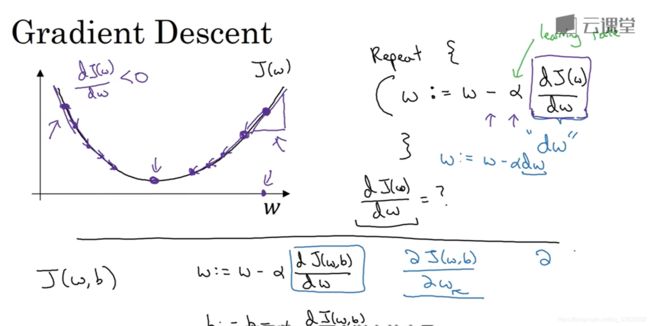
2.4 梯度下降 - Gradient Descent
minimize J ( w , b ) J(w,b) J(w,b)
2.5 - 2.6 导数
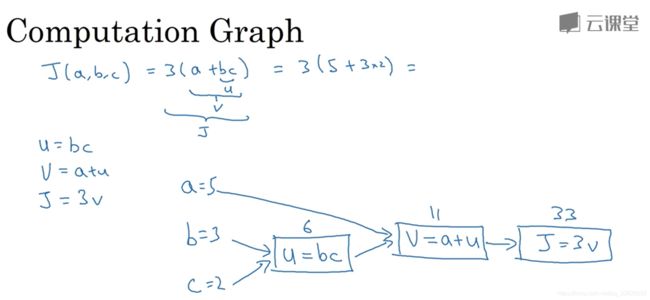
2.7 计算图 - Computation Graph
2.8 计算图的导数计算

2.9 logistic 中的梯度下降法

2.10 m个样本的梯度下降法

2.11 - 2.12 向量化 - Vectorization
消除代码中显示的for循环,加快运算速度
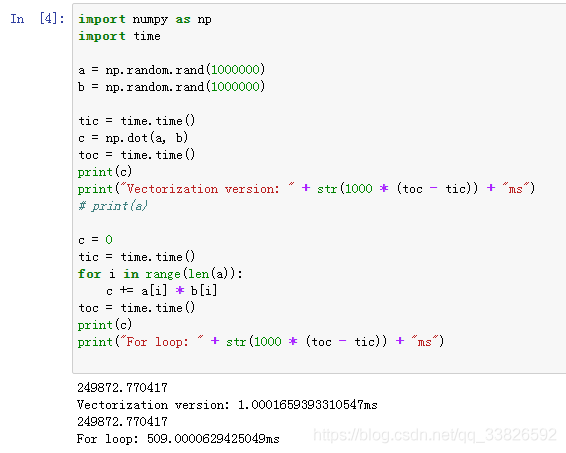
numpy常用矩阵运算:
np.dot(w, x)
np.exp(v)
np.log(v)
np.abs(v)
np.maximum(v, 0)
v ** 2
1 / v
2.13 - 2.14 向量化 Logistics 回归

2.15 Python 中的广播

2.16 关于python/numpy向量的说明
尽量不用 一维 数组
如:a = np.random.randn(5) 改为 a = np.random.randn(5, 1) 或 a = np.random.randn(1, 5)
断言 assert
a = np.random.randn(5, 1)
assert a.shape == (4, 1), "shape错误"
2.17 Jupyter/Ipython 快速指南
2.18 logistic 损失函数的解释
y ^ = σ ( w T x + b ) \hat y = \sigma (w^Tx+b) y^=σ(wTx+b), where σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1;
y ^ \hat y y^ 为 x x x 条件下 y = 1 y=1 y=1 的概率 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x);
因此,
如果 y = 1 y=1 y=1: p ( y ∣ x ) = y ^ p(y|x)=\hat y p(y∣x)=y^ ,即 y = 1 y=1 y=1的概率;
如果 y = 0 y=0 y=0: p ( y ∣ x ) = 1 − y ^ p(y|x)=1-\hat y p(y∣x)=1−y^ ,即 y = 0 y=0 y=0的概率;
由于 y y y只能取 0 0 0或者 1 1 1,因此上述两个式子合为一个:
p ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y p(y|x)=\hat y^y(1-\hat y)^{1-y} p(y∣x)=y^y(1−y^)1−y.
由于 log \log log 函数严格单调递增,最大化 log ( p ( y ∣ x ) ) \log (p(y|x)) log(p(y∣x)) 等价于最大化 p ( y ∣ x ) p(y|x) p(y∣x) ;
log ( p ( y ∣ x ) ) = log ( y ^ y ( 1 − y ^ ) 1 − y ) = y log y ^ + ( 1 − y ) log ( 1 − y ^ ) \log (p(y|x)) = \log (\hat y^y(1-\hat y)^{1-y}) = y\log \hat y + (1-y)\log (1-\hat y) log(p(y∣x))=log(y^y(1−y^)1−y)=ylogy^+(1−y)log(1−y^)
因此损失函数 Loss function为: L ( y ^ , y ) = − ( y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ) L(\hat y,y) = -(y \log \hat y + (1-y)\log{(1-\hat y)}) L(y^,y)=−(ylogy^+(1−y)log(1−y^))。
而 m m m个训练样本的总体成本函数该如何表示?
首先,整个训练集中标签的概率为(假设所有样本独立同分布)
p ( labels in training set ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ) p(\text{labels in training set}) = \prod_{i=1}^{m} p(y^{(i)}|x^{(i)}) p(labels in training set)=i=1∏mp(y(i)∣x(i))
最大似然估计,需寻找一组参数,使得给定样本的观测值概率最大,但令这个概率最大化,等价于令其对数最大化,于是在等式两边取对数
log p ( labels in training set ) = log ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ) = ∑ i = 1 m log p ( y ( i ) ∣ x ( i ) ) = ∑ i = 1 m − L ( y ^ ( i ) , y ( i ) ) \begin{aligned} \log p(\text{labels in training set}) & = \log \prod_{i=1}^{m} p(y^{(i)}|x^{(i)}) \\ & = \sum_{i=1}^{m} \log p(y^{(i)}|x^{(i)}) \\ & = \sum_{i=1}^{m} -L(\hat y^{(i)}, y^{(i)}) \end{aligned} logp(labels in training set)=logi=1∏mp(y(i)∣x(i))=i=1∑mlogp(y(i)∣x(i))=i=1∑m−L(y^(i),y(i))
因此,成本函数Cost function为 J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) J(w,b)=\frac{1}{m} \sum_{i=1}^m{L(\hat y^{(i)},y^{(i)})} J(w,b)=m1∑i=1mL(y^(i),y(i))
week 3. 浅层神经网络
3.1 - 3.5 神经网络表示、计算、向量化
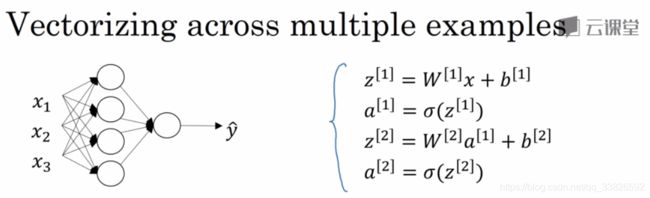

3.6 激活函数
搭建神经网络,有很多不同的选择:隐藏单元数、激活函数、如何初始化权重。
激活函数包括隐层里用哪一个激活函数、以及输出单元用什么激活函数。
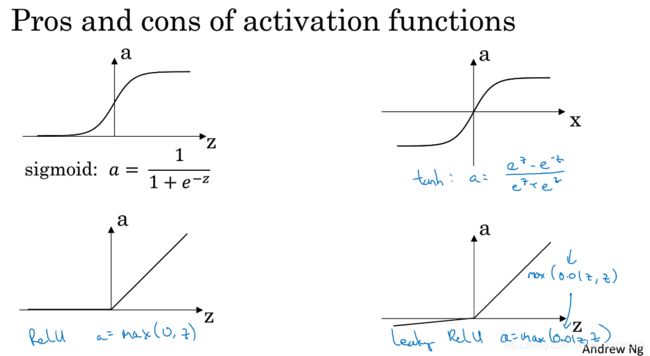
常用的激活函数:
sigmoid函数: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
双曲正切函数tanh: tanh ( z ) = e z − e − z e z + e − z \tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}} tanh(z)=ez+e−zez−e−z,几乎在所有场合效果都比sigmoid好(一个例外是二分类时的输出层,sigmoid输出0到1之间更合理),因为平均值更接近于0,具有类似于数据中心化的效果,使输出数据平均值更接近于0,而不是sigmoid的0.5,这有助于下一层的学习。
而sigmoid和tanh都有一个缺点,就是当z非常大或非常小的时候,导数的梯度(斜率)会很小(接近于0),这时会拖慢梯度下降法,因此有所谓的修正线性单元ReLU: ReLU ( z ) = max ( 0 , z ) \text{ReLU}(z)=\max(0,z) ReLU(z)=max(0,z)。ReLU的缺点是,当z为负时,导数等于零。
最常用:ReLU,隐层激活函数默认选他。
ReLU和带泄露的ReLU的好处在于,对于很多z空间,激活函数的导数(斜率)和0差很远,所以在实践中使用ReLU,会使神经网络的学习速度快很多。
另外,对于z的一半范围来说,ReLU的斜率为零,但在实践中,有足够多的隐藏单元,令z大于0,所欲对大多数训练样本来说是很快的。
具体怎么选择,要根据实际应用,可以通过在数据集上交叉验证来选择参数。
3.7 为什么需要非线性激活函数?
如果不使用非线性激活函数,模型的输出 y ^ \hat y y^ 不过是输入特征 x x x 的线性组合,那么不论神经网络有多少层,都跟去掉隐藏层后是一样的。
3.8 激活函数的导数
| activation function name | function | Derivatives |
|---|---|---|
| sigmoid | g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1 | g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) g'(z)=g(z)(1-g(z)) g′(z)=g(z)(1−g(z)) |
| tanh | g ( z ) = e z − e − z e z + e − z g(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}} g(z)=ez+e−zez−e−z | g ′ ( z ) = 1 − ( g ( z ) ) 2 g'(z)=1-(g(z))^2 g′(z)=1−(g(z))2 |
| ReLU | g ( z ) = max ( 0 , z ) g(z)=\max(0,z) g(z)=max(0,z) | g ′ ( z ) = { 0 z < 0 1 z ≥ 0 g'(z)=\begin{cases} 0 & z<0 \\1 & z\geq 0 \end{cases} g′(z)={01z<0z≥0 |
| Leaky ReLU | g ( z ) = max ( 0.01 z , z ) g(z)=\max(0.01z,z) g(z)=max(0.01z,z) | g ′ ( z ) = { 0.01 z < 0 1 z ≥ 0 g'(z)=\begin{cases} 0.01 & z<0 \\1 & z\geq 0 \end{cases} g′(z)={0.011z<0z≥0 |
3.9* 神经网络的梯度下降法


3.10 (选修)直观理解反向传播


3.11 随机初始化
logistic回归可以将权重全部初始化为零,但神经网络则不行,这样会使梯度下降法完全失效。因此应该随机初始化权重(并且为比较小的随机值):
w_1 = np.random.randn((2, 2)) * 0.01
b_1 = np.zeros((2, 1))
week 4. 深层网络基础
4.1 - 4.2 深层神经网络
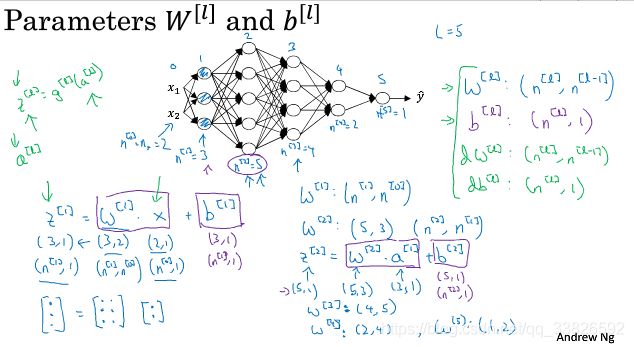
4.3 核对矩阵的维数
4.4 为什么使用深层表示
4.5 搭建深层神经网络块
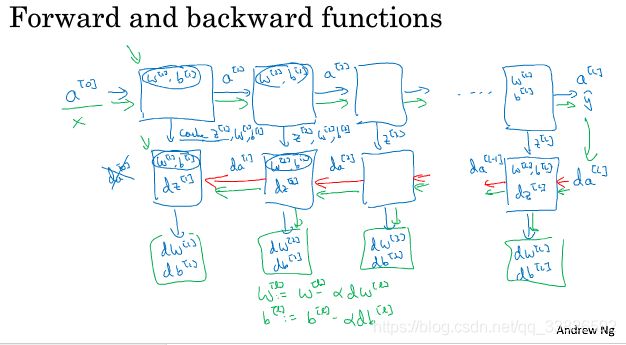
4.6 前向和反向传播

注:公式中 d W dW dW 计算有误,应为: d W [ L ] = 1 m d Z [ L ] A [ L − 1 ] T dW^{[L]} = \frac{1}{m}dZ^{[L]}A^{[L-1]T} dW[L]=m1dZ[L]A[L−1]T
4.7 参数VS超参数
链接: Neural Network Hyperparameters
Parameters: W [ 1 ] , b [ 1 ] , W [ 2 ] , b [ 2 ] , W [ 3 ] , b [ 3 ] , ⋯ W^{[1]},b^{[1]},W^{[2]},b^{[2]},W^{[3]},b^{[3]},\cdots W[1],b[1],W[2],b[2],W[3],b[3],⋯
Hyperparameters:
- learning rate α \alpha α
- iterations
- hidden layers L L L
- hidden units n [ 1 ] , n [ 2 ] , ⋯ n^{[1]},n^{[2]},\cdots n[1],n[2],⋯
- choice of activation function
其他超参数:
- momentum
- mini batch size
- 几种不同的正则化参数等
这些超参数某种程度上决定了最终得到的 W W W 和 b b b。
当开始一个新应用的时候,预先很难确切知道超参数最优值是多少,所以通常必须尝试很多不同的值,试试各种参数。
返回目录