Hive实战解析—汽车销售问题(代码+解析)
数据文件:https://pan.baidu.com/s/1bud5O36RtSm4dNQ17h-wuA
提取码:lq3a
1、创建表
根据数据文件我们可以写出建表语句如下
create table cars(
province string, --省份
month int, --月
city string, --市
county string, --区县
year int, --年
cartype string,--车辆型号
productor string,--制造商
brand string, --品牌
mold string,--车辆类型
owner string,--所有权
nature string, --使用性质
number int,--数量
ftype string,--发动机型号
outv int,--排量
power double, --功率
fuel string,--燃料种类
length int,--车长
width int,--车宽
height int,--车高
xlength int,--厢长
xwidth int,--厢宽
xheight int,--厢高
count int,--轴数
base int,--轴距
front int,--前轮距
norm string,--轮胎规格
tnumber int,--轮胎数
total int,--总质量
curb int,--整备质量
hcurb int,--核定载质量
passenger string,--核定载客
zhcurb int,--准牵引质量
business string,--底盘企业
dtype string,--底盘品牌
fmold string,--底盘型号
fbusiness string,--发动机企业
name string,--车辆名称
age int,--年龄
sex string --性别
)
row format delimited
fields terminated by '\t';
2、导入数据
这里的数据文件路径写你自己存放的路径
load data local inpath '/usr/local/hive/Test/cars.txt' into table cars;
(输入select * from cars limit 2;检测是否插入成功)
 成功录入。
成功录入。
3、查询分析
(记得每句查询语句后面都写;)
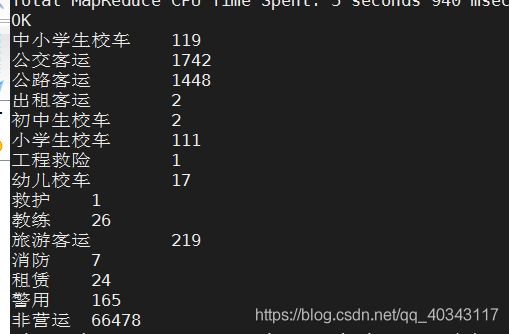
3.1-统计乘用车辆和商用车辆的数量(即非营运和营运车辆)
nature string, --使用性质
select nature,count(number) from cars where nature!='' group by nature;
解析:这里的count是计数函数,会统计使用性质的数量,后面我们限制使用性质这列不可以为空,这是一次简单的数据清洗,清洗掉垃圾数据,然后group by根据使用性质列不同的内容进行划分,并分别计数。
3.2-统计山西省2013年每个月的汽车销售数量的比例
month int,–月份
select count(*) from cars;总数量
select month from (select month,count(*) from cars group by month);每个月的数量
select month,round(mei/zong,2)as resl from (select month,count(*) as mei from cars where month is not null group by month)as mm,(select count(*) as zong from cars)as zz;
根据我们上面的划分,可以看出来这一道题被拆成了三步,要想求出每个月的比例,就先要知道总的数量和每个月的数量,然后进行拼接使用,求出比例。
在最后一步的整合中,我们用到了round函数,它的作用是将()里的数字四舍五入,后面的2意思是保留两位小数,而mei/zong是我们根据自己的理解将求出总数和每个月数量的语句作为一个新的变量来使用,也就是后面用到的“as”。

3.3-统计买车的男女比例
sex String,性别
select sex,count(*) from cars;总人数
select sex,count(*) from cars where sex is not null and sex !='' group by sex;男女
select sex,round(nv/zong,2)as resl from (select sex,count(*) as nv from cars where sex is not null and sex !='' group by sex)as nnvv,(select sex,count(*) as zong from cars)as zz;
这里的语句和上面大致相同,一样理解就可以。

3.4-统计车的所有权、型号和类型
mold string,–车辆类型
owner string,–所有权
cartype string,–车辆型号
select owner,cartype,mold,count(*) from cars group by owner,cartype,mold;
这句话也很好理解,就是选择三个你需要的列,输出他们的内容,并groupby去重。

3.5-统计不同类型车在每个月的总销售量
mold string,–车辆类型
month int, --月
select mold,month,count(*) from cars group by mold,month;
通过类型和月份输出,并通过count计数求出每个月的总销量

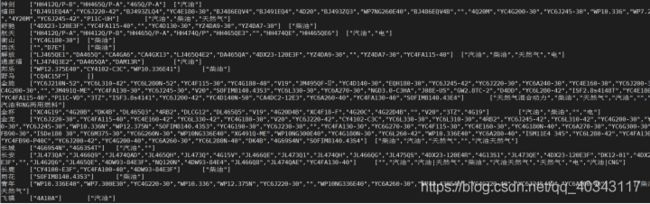
3.6-通过不同品牌车销售情况,来统计发动机型号和燃料种类
brand string, --品牌
ftype string,–发动机型号
fuel string,–燃料种类
collect_set()跟java里的set一样,里面存放的内容不会重复,可以实现简单的去重功能,collect_list就是list,里面的内容可以重复
select brand,collect_set(ftype),collect_set(fuel) from cars where brand is not null and brand != '' group by brand;
这里用到了collect_set去重,后面坐的是简单的数据清洗。
更新:想出一种新方法,可以更直观的看出数据的问题
select brand,collect_set(concat(ftype,fuel)) from cars where brand is not null and brand != ''and ftype is not null and ftype != ‘’ group by brand;
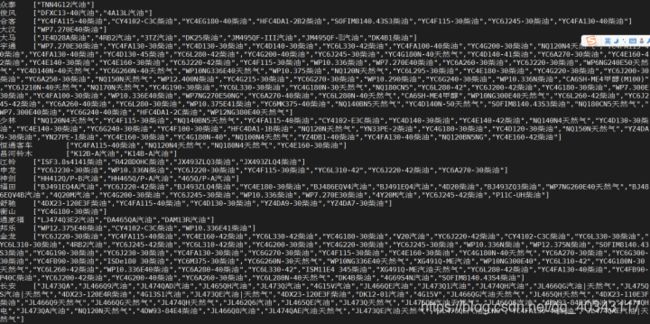
这里使用了concat函数,将字符串拼接之后放入set集合,这样数据更清晰,因为一但然后种类过多,与型号对应的话用上面的方法太难了,根本不是我们想要的结果,这里拼接好之后,我们就可以每个型号后面跟着他的燃油种类,观看更方便只管。
3.7-统计五菱每一个月的销售量
brand string, --品牌
month int, --月
select brand,month,count(*) from cars where brand='五菱' and month is not null group by brand,month;
