手把手带你打造自己的UI样式库(第一章)
这一章里主要是介绍一下页面结构基础,CSS 选择器,页面渲染机制,屏幕适配方案,CSS书写规范。
页面结构基础
盒模型
在浏览器中,每一个 DOM 节点渲染后,都会在屏幕上占用一个方形的区域,这个方形的区域就被称为盒子,我们把这种渲染方式叫盒模型。在盒模型中,我们主要介绍盒模型的主要属性、两种盒模型和边距折叠这三个内容:
一、盒模型主要属性

上面的三幅画,其实就是 HTML 中的三个盒子。对盒子大小和位置能产生影响的一共有四类属性,他们分别是:
- 宽度(width)和高度(height),这两个属性分别决定了一个盒子的宽度和高度,在标准盒模型中,这个宽高指定的就是最里层内容区的宽度和高度,对应画框中最里面带色彩的部分。
- 内边距(padding),当内容区和边框需要离开一定的间距,避免布局太过拥挤时,就可以用内边距来指定他们隔开的距离。在画框中就对应着内容区和边框中间夹着的那部分白色的区域。
- 边框(border),边框比较好理解,就是每幅画的外框。
- 外边距(margin),外边距是用来限制盒子与盒子中间的距离的,在上图中,三幅画边框与边框中间空出来的距离,就由外边距来指定。
把上面的画框抽象一下,每个盒子的结构就是下图所示:
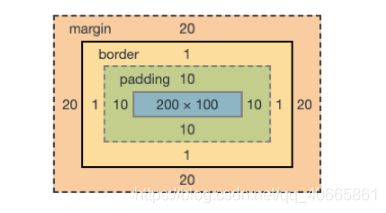
二、两种盒模型
在盒模型的属性除了标准盒模型外,还有在IE浏览器中使用的怪异盒模型。使用了 box-sizing:content-box;属性的就是标准模式,用了 box-sizing:border-box;属性的就是怪异模式。
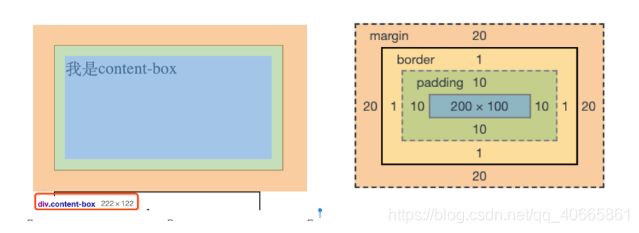
如果我们给盒子都设置成 200px 的宽度,100px 的高度,10px 的 padding 和 1px 的 border。
- 标准盒模型,标准盒模型这个标准是由 W3C 组织制定的,现在除了低版本IE以外,基本所有浏览器都遵循这个标准。标准盒模型中,width 和 height 属性所指定的宽高就是实际内容区的大小,而盒子实际大小是:
横向空间:width + padding宽度 + border宽度
纵向空间:height + padding宽度 + border宽度
可以看出来这个盒子的总宽度是 222px,也就是 200px 的 width,加上两边各 10px 的 padding,再加上两边各 1px 的边框,实际占用屏幕的宽度就是
200px + 10px2 + 1px2 = 222px。
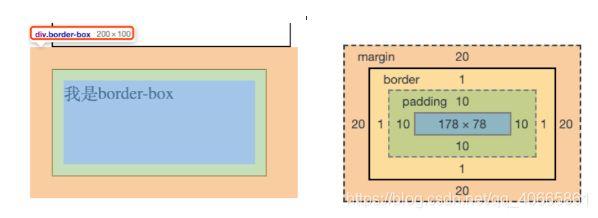
- 怪异盒模型,怪异盒模型是微软在 IE6、7、8 中使用的一种盒模型,所以也把怪异盒模型叫做 IE盒模型。在怪异模式下,width 和 height 做指定的宽高就是盒子的实际宽高,而它内容区部分的大小是在 width 或 height 指定尺寸的基础上,再减去 border 和 padding 所占的宽度。
在怪异盒模型中,我们设置的宽度也是 200px,它的盒子占用的横向空间就是 200px,但是内容区的宽度变成了 178px,这就是用它的宽度减去了两边 padding 和两边 border 的结果。
标准盒模型是有缺陷的,在标准模式下,我们设置盒子的宽高并不是它实际所占空间,所以在布局的时候,就要再把盒子的 border 和 padding 计算一下来给这个盒子分配空间。但是在用 px 这种绝对单位指定盒子宽高的时候还能算一下应该把盒子设置成多大,但如果是用百分比指定盒子宽高的时候,就没办法算了。另外 border 只支持绝对宽度,而 px 和百分比混在一起做运算是比较困难的。比如一行四个盒子,每个盒子有 1px 的边框,这时候按着标准盒模型给每个盒子25%的宽度,这四个盒子就会折行,不能放在一行。
这个时候就体现出怪异模型的好处了,假如一行四个盒子平均分配,在怪异模式中只需要每个盒子宽度 25%,然后 border 和 padding 随便设置,浏览器会自己去算内容区应该有多大的。W3C 应该也是意识到了这个问题,但标准模式用了这么多年,肯定是回不去了,也不能自己打脸说这些年我错了。所以在 CSS3 中做了补救,就是加上了上面使用过的 box-sizing 属性。
三、外边距折叠
最后说一个特殊的概念,就是外边距折叠。我们在前面讨论的都是内容区、padding 和 border 间的关系,在这我们来说一下 margin。margin 的意思就是距别的框之间的距离,这很好理解。但是如果两个盒子都设置了 margin,在排列这两个盒子的时候并不会把两个 margin 值的和作为两个盒子的间距。比如上下排列的盒子A和盒子B,盒子A的下边距是10px,盒子 B 的上边距是 20px,那么在渲染时候,它俩之间的距离将会是 20px。就像A说我 10 米之内寸草不生;B说我20米内片甲不留。那把这俩盒子中间隔上个20 米,它俩就都是安全的了,而用不着隔开 30米。盒子间距的实际值其实就是取两个盒子间margin值较大的那个。
文档流
说完盒子模型,就可以说文档流了。所谓文档流,就是DOM节点排版布局过程中,元素会自动从左往右,从上往下的流式排列。在一行里,节点是按着从左到右排列,当这一行内容排满的时候,就再单起一行排余下的内容,再排满就再新开一行。这里面有几个地方要注意:
- 在正常布局下,块级元素会自己占用一行,有几个块级元素就会有多少行。而行内元素才会从左到右的排列。
- 如果某元素用到了绝对定位或固定定位(absolute和fixed),那这个元素就会脱离文档流,它前后的元素会忽略它的位置。而这个脱离文档流的元素会按着指定的位置重新定位,如果没指定位置,则会按着脱离文档流之前的位置进行定位。
- 如果某元素使用了浮动属性(float),那这个元素也会脱离文档流,浮动元素后面如果是块级元素的话,就会忽略它的存在。但它和绝对定位不同的是,浮动元素虽然也会脱离文档流,但会在文本的排布中占有位置,浮动元素后面的文本会环绕着它进行排布。从下面的图可以看出来,两个红色的块是标准的文档流,已经没黄色的浮动的盒子什么事了,但是第二个红色块中的文本却受到了黄色块的影响。

页面层级
刚说了文档流在排列的时候,有元素脱离文档流的情况,这时候不同的元素就会出现层叠的情况。或者在标准文档流中,通过设置负值的 margin,也可能会导致元素互相遮盖。从这种遮盖关系来看,就知道 HTML 其实是一个三维的空间,有平面的 x,y 位置,也有 z 轴上的层叠关系。
在默认的情况下,即不指定层级的时候,所有元素是按下面的层级排列的:
- HTML 在渲染的时候最先渲染的是标准文档流,所以标准文档流中的内容会被排在最下一层,标准文档流中如果还有层级,那就是后出现的会挡住先出现的。
- float 元素在标准文档流之后渲染,所以 float 会在标准文档流的上一层。
- 绝对定位的元素最后渲染,所以默认情况下绝对定位元素会排在最上层。
如果对默认的层叠关系不满意,我们就可以用 z-index 数值手动指定各个元素的层级关系。但这里要注意,z-index 只对已经有定位的元素生效(position:relative/absolute/fixed),所以当写样式的时候遇到 z-index 没有达到你预期效果的时候,考虑一下这种情况。
在使用 z-index 的时候,我们最好对整个项目的层级关系有个提前的设计,不要随便用。当我们的页面需要分成多个层级的时候,可以对每个层级设置一个 z-index 使用的范围。比如一个页面主要分为内容层、导航层和蒙版提示层这三层,那么就可以限制内容层的 z-index 值从 100 到 200 之间;导航层要覆盖住内容层,z-index 可以用 200 到 300 这个范围的值;蒙版提示层要盖住一切,z-index 可以用 300 到400 这个范围的值。这样每一层的层级关系就是明确的,不会互相影响。
CSS选择器
ID 选择器
ID 选择器是用 “#” 号加 ID 名称 xxx 来表示,用来选择 HTML 中 id=“xxx” 的 DOM 元素。
Tips:
1、ID 选择器只能对一个元素生效,同一个页面里不允许出现两个 ID 相同的元素。
2、理论上 ID 选择器是效率最高的选择器。但是由于它只能选一个元素,特异性太高,在实际开发中也很少在 CSS 里使用 ID 选择器。
3、也正是因为 ID 选择器特异性高,所以在 JS 里使用 ID 选择器的比较常见。
类选择器
类选择器是用 “.” 加上 class 名称来表示,用来选择 HTML 中 class=“xxx” 的 DOM 元素。
Tips:
1、类选择器的效率也是不错的,和 ID 选择器并不会有太大的差异。所以在写 CSS 的时候,比较推荐用类选择器。
2、类选择器会选择到所有类名相同的 DOM 元素,没有数量限制。
3、类选择器应该是样式开发中应用最多的选择器。
通配选择器
通配选择器使用星号来选择到页面里所有元素。用法如下:
*{
margin: 0;
padding: 0;
}
上面这个样式就是把所有元素的内外边距都归零。由于通配选择器要把样式覆盖到所有的元素上,可想而知它的效率并不会高,所以在实际开发中一般不建议使用通配选择器。
标签选择器
标签选择器的作用是选中 HTML 中某一种类的标签,它直接使用 HTML 中的标签名作为选择器的名称。比如我们需要把页面里所有大标题的字号都调成 20px,就可以用标签选择器来实现:
h1{
font-size: 20px;
}
Tips: 标签选择器通常用来重置某些标签的样式,标签选择器的效率也不是很高,但要好过通配选择器。
属性选择器
属性选择器比较好理解,就是通过 DOM 的属性来选择该 DOM 节点。属性选择器是用中括号 “[]” 包裹.
属性选择器有如下几种形式:
- [attr],用来选择带有 attr 属性的元素,如刚提到的 a [href]。
- [attr=xxx],用来选择有 attr 属性且属性值等于 xxx 的元素,如选择所有文本类型的输入框,可以用 input [type=text]。
- [attr~=xxx],这个选择器中间用了~=,选择属性值中包含 xxx 的元素,但一定是逗号分隔的多个值中有一个能和 xxx 相等才行。
- [attr|=xxx],这个选择器是用来选择属性值为 xxx 或 xxx- 开头的元素,比较常用的场景是选择某一类的属性。
- [attr^=xxx],这个选择器会匹配以 xxx 开头的元素,实际上就是用正则去匹配属性值,只要是以 xxx 开头都可以。
- [attr$=xxx],这个选择器和上一个相似,它是用正则匹配的方式来选择属性值以 xxx 结尾的元素。
- [attr*=xxx],最后一个,这个是用正则匹配的方式来选择属性值中包含 xxx 字符的所有元素。这个选择器的规则算是最宽泛的,只要 xxx 是元素属性值的子字符串,这个选择器就会生效。
Tips:
- 属性选择器要做文本的匹配,所以效率也不会高。
- 在使用属性选择器时,尽量要给它设置上生效的范围,如果只用了个 [href] 相当于要在所有元素里找带 href 的元素,效率会很低。如果用 a [href] 会好的多,如果用 .link [href] 就更好了。这种组合方式我们在下一节讲解。
- 属性选择器很灵活,如果能使用 CSS 代替 JS 解决一些需求,可以不用太纠结性能的问题,用 JS 实现也一样要耗费资源的。
后代选择器
后代选择器的语法是用空格分隔的多个选择器组合,它的作用是在 A 选择器的后代元素中找到 B 选择器所指的元素。它的语法形式就是:“选择器 A 选择器 B”
Tips:后代选择器通常用来限制选择器生效的范围,防止因为选择器使用不当或者对元素命名出现重复造成的样式冲突。
子元素选择器
子元素选择器和后代选择器类似,也是为选择器限定范围。不同的是子元素选择器只找子元素,而不会把所有的后代都找一遍。它的语法是 “选择器 A> 选择器 B”
Tips:子元素选择器的作用和后代选择器相似,也是用来限制选择器生效的范围。它和后代选择器不同的是:
- 子元素选择器只匹配子元素,不会匹配后代元素。在有确定的父子关系时,尽量使用子元素选择器,效率会比后代选择器高。
- 使用子元素选择器还可以避免对非直接后代的样式影响,在只想给子元素设置样式时会比后代选择器安全。
兄弟选择器
在 CSS 中,还有一种选择器是用来选取同级元素的,叫做兄弟选择器。兄弟选择器有两种,一种是相邻兄弟选择器,另外一种是通用兄弟选择器。
一、相邻兄弟选择器
相邻兄弟选择器是用来选取某个元素紧邻的兄弟元素,它的语法是 “选择器 A + 选择器 B”,表示找到与 A 元素相邻的 B 元素。其实就是对选择器 B 加上 “紧邻着选择器 A” 的限制。
Tips:相邻兄弟选择器通常有两类用处:
- 用于自动调整占位,比如后面在布局的时候,有 header 和没 header 情况下内容区的高度会不同,就可以使用相邻兄弟选择器来控制内容区的高度。
- 相邻兄弟选择器的第二种用法是用来控制相同元素中间的间隔,比如在 List 组件开发时,每个 li 元素之间要加上分割线的需求就会通过相邻兄弟选择器来实现。
二、通用兄弟选择器
通用兄弟选择器和相邻兄弟选择器很相似,它的语法是 “选择器 A ~ 选择器 B”,也是用选择器 A 做限制,选择器 B 是最终匹配的目标。不同的是通用兄弟选择器会匹配选择器 A 指定元素后面的所有符合选择器 B 规则的元素。
Tips:
兄弟选择器(包括相邻兄弟选择器和通用兄弟选择器)中都是只能向后选择,如果需要向前选择,就只能给前面的元素指定上 class,再用类选择器来实现了。这里为什么不供向前寻找的方式,我们留个悬念,后面在讲渲染原理的时候再来分析。
交集选择器
交集选择器是为了找两个或多个选择器的交集,用法就是把两个选择器放在一起,形式如 “选择器 A 选择器 B”,中间不需要加空格或者其他符号。交集选择器最主要的作用是在限定范围内标识特殊的样式。
并集选择器
并集选择器是为了合并类似的样式,可以把选择器不同但样式相同的 CSS 语法块做合并。并集选择器就是用逗号分割多个选择器,形式如 “选择器 A, 选择器 B”,表示该样式对选择器 A 和选择器 B 所选择的元素都生效。
伪类选择器
在页面中,有时候同一个元素在不同动作下有不同的样式。比如链接在没有点击的时候有个样式,在鼠标放上去有另外的样式,还有在点击完成以后又会又一个样式。这几种情况下这个链接的标签并没有变化,有变化的只是它的状态,这时候就可以里用伪类来实现这个需求。在浏览器中,伪类的出现是为了向某些选择器添加特殊的效果或限制。伪类是在正常的选择器后面加上伪类名称,中间用冒号(:)隔开。
伪类主要有两方面的用处,一方面是标记一些特殊的状态;另外还有一类伪类是有筛选的功能。
一、标记状态的伪类:
可以标记元素状态的伪类有如下几种:
- :link,选取未访问过的超链接元素。如果我们注意过搜索引擎的结果的话,它里面的链接只要点过的就会变色,从而标记哪个链接是访问过的。:link 这个属性就是用来标识没访问过的链接。
- :visited,选取访问过的超链接元素。和第一条相反,:visited 是用来标记哪个链接是已经访问过的,防止重复点击。
- :hover,选取鼠标悬停的元素。,这个伪类经常用在 PC 端,当鼠标放在一个元素上时,可以用 :hover 来控制鼠标悬停的样式。因为在移动端里没有鼠标的概念,所以移动端里很少用这个伪类。
- :active,选取点中的元素。这个伪类的作用在刚才提到过了,当我们希望按钮有操作反馈的时候,可以用它来标记操作反馈的样式。当然这个伪类也是可以通用的,并不是只能用在按钮上。
- :focus,选取获得焦点的元素。这个伪类用来标识获得焦点的元素,比如搜索框在聚焦的时候有个比较明显的边框,方便用户知道当前在可输入的状态。
二、筛选功能的伪类:
有些伪类也可以有筛选的功能,可以根据元素的特点或者索引来给特定的元素加上样式。常用的有筛选功能的伪类如下:
- :empty,选取没有子元素的元素。比如选择空的 span,就可以用 span:empty 选择器来选择。这里要注意元素内有空格的话也不能算空,不会被这个伪类选中。
- :checked,选取勾选状态的 input 元素, 只对 radio 和 checkbox 生效。
- :disabled,选取禁用的表单元素。
- :first-child,选取当前选择器下第一个元素。
- :last-child,和 first-child 相反,选取当前选择器下最后一个元素。
- :nth-child(an+b),选取指定位置的元素。这个伪类是有参数的,参数可以支持 an+b 的形式,这里 a 和 b 都是可变的,n 从0起。使用这个伪类可以做到选择第几个,或者选择序号符合 an+b 的所有元素。比如使用 li:nth-child(2n+1),就可以选中 li 元素中序号是2的整数倍加1的所有元素,也就是第1、3、5、7、9、2n+1个 li 元素。
- :nth-last-child(an+b) ,这个伪类和 nth-child 相似,只不过在计数的时候,这个伪类是从后往前计数。
- :only-child,选取唯一子元素。如果一个元素的父元素只有它一个子元素,这个伪类就会生效。如果一个元素还有兄弟元素,这个伪类就不会对它生效。
- :only-of-type,选取唯一的某个类型的元素。如果一个元素的父元素里只有它一个当前类型的元素,这个伪类就会生效。这个伪类允许父元素里有其他元素,只要不和自己一样就可以。
这个项目中会用到具有筛选功能的“:nth-child(an+b)”选择器,我们通过使用这个伪类按着网格排布的规律选择出需要加边框的元素。
伪元素选择器
伪元素选择器是用于向某些元素设置特殊效果。伪元素选择器选中的并不是真实的 DOM 元素,所以叫伪元素选择器。伪元素选择器常用的也就下面 5 个:
- ::first-line,为某个元素的第一行文字使用样式。
- ::first-letter,为某个元素中的文字的首字母或第一个字使用样式。
- ::before,在某个元素之前插入一些内容。
- ::after,在某个元素之后插入一些内容。
- ::selection,对光标选中的元素添加样式。
Tips:
- 伪元素选择器构造的元素是虚拟的,所以不能用 JS 去操作它。
- 如果同时使用了 before 和 first-letter 两个伪类,第一个字是要从 before 里的内容开始算起的,如果 before里面的内容是一个非文本元素,那 first-letter 也会作用在这个非文本元素上,但是不一定能生效。
- first-line 和 first-letter 不适用于内联元素,在内联元素中这两个选择器都会失效。
- 在 CSS3 中,规定了伪类用一个冒号(:)表示,伪元素用两个冒号表示(::)。但除了 selection,其余四个伪元素选择器已经在 CSS2 中存在且和伪类用的是一样的单冒号表示的。为了向下兼容,现在的浏览器中伪元素选择器用单冒号和双冒号都可以。在没有兼容问题的情况下,还是建议大家按着新的 CSS3 标准来开发。
CSS 选择器相关的文档在W3C网站:https://www.w3.org/TR/selectors/#selectors 上进行查看
页面渲染机制
页面的加载和渲染全过程
当我们在浏览器里输入一个 URL 后,最终会呈现一个完整的网页。这中间会经历如下的过程:
- HTML 的加载
输入 URL 后,最先拿到的是 HTML 文件。HTML是一个网页的基础,所以要在最开始的时候下载它。HTML下载完成以后就会开始对它进行解析。 - 其他静态资源下载
HTML 在解析的过程中,如果发现 HTML 文本里面夹杂的一些外部的资源链接,比如 CSS、JS 和图片等时,会立即启用别的线程下载这些静态资源。这里有个特殊的是 JS 文件,当遇到 JS 文件的时候,HTML 的解析会停下来,等 JS 文件下载结束并且执行完,HTML 的解析工作再接着来。这样做是因为 JS 里可能会出现修改已经完成的解析结果,有白白浪费资源的风险,所以 HTML 解析器干脆等 JS 折腾完了再干。 - DOM 树构建
在 HTML 解析的同时,解析器会把解析完的HTML转化成DOM 对象,再进一步构建 DOM 树。 - CSSOM 树构建
当 CSS 下载完,CSS 解析器就开始对 CSS 进行解析,把 CSS 解析成 CSS 对象,然后把这些 CSS 对象组装起来,构建出一棵 CSSOM 树。 - 渲染树构建
DOM 树和 CSSOM 树都构建完成以后,浏览器会根据这两棵树构建出一棵渲染树。 - 布局计算
渲染树构建完成以后,所有元素的位置关系和需要应用的样式就确定了。这时候浏览器会计算出所有元素的大小和绝对位置。 - 渲染
布局计算完成以后,浏览器就可以在页面上渲染元素了。比如从 (x1, y1) 到(x2, y2)的正方形区域渲染成蓝色。经过渲染引擎的处理后,整个页面就显示在了屏幕上。
DOM 树的构建
页面中的每一个 HTML 标签,都会被浏览器解析成一个对象,我们称它为文档对象(Document Object)。HTML 的本质是一个嵌套结构,在解析的时候会把每个文档对象用一个树形结构组织起来,所有的文档对象都会挂在一个叫做 Document 的东西上,这种组织方式就是 HTML 最基础的结构–文档对象模型(DOM),这棵树里面的每个文档对象就叫做 DOM 节点。
在 HTML 加载的过程中,DOM 树就在开始构建了。构建的过程是先把 HTML 里每个标签都解析成 DOM 节点(每个标签的属性、值和上下文关系等都在这个文档对象里),然后使用深度遍历的方法把这些对象构造成一棵树。
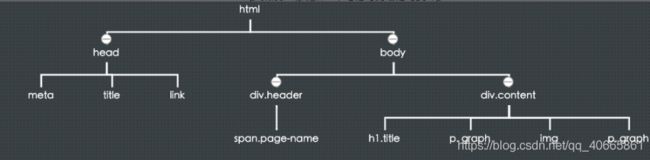
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<link rel="stylesheet" href="./index.css">
</head>
<body>
<div class="header">
<span class="page-name">文章详情页</span>
</div>
<div class="content">
<h1 class="title">文章标题</h1>
<div class="article">
<p class="graph">吃葡萄不吐葡萄皮</p>
<img src="./test.jpg" alt="文章插图">
<p class="graph">不吃葡萄倒吐葡萄皮</p>
</div>
</div>
</body>
</html>
在构建 DOM 树的时候,就是从最外层 HTML 节点开始,按深度优先的方式构建。之所以用深度优先,是因为 HTML在加载的时候是自上而下的,最先加载的是根节点,然后是根节点的第一个子节点,再然后是head的第一个子节点…head构建完成后再去构建 body 部分的内容,以此类推。使用深度优先的方式构建这棵树就和文档的加载顺序吻合了。
CSSOM 树的构建
在浏览器构建 DOM 树的同时,如果样式也加载完成了,那么 CSSOM 树也在同步地构建。CSS 树和 DOM 类似,它的树形结构记录着所有样式的信息。
body{
font-size: 16px;
}
// 去掉所有p元素的内外边距
p{
margin: 0;
padding: 0;
}
// 页面头部行高50px,文本垂直居中,隐藏
.header{
height: 50px;
line-height: 50px;
display: none;
text-align: center;
}
.header .page-name{
font-size: 20px;
}
// 文本区域左右两边留10px空白
.content{
padding: 0 10px;
}
.contetn .title{
font-seize: 20px;
}
// 内容区行高30px
.content .graph{
line-height: 30px;
}
// 文章中的图片用作块级元素,水平居中
.content img{
display: block;
margin: 0 auto;
}
我们就以这一组样式为例,这样一组样式中有公用的样式 p 和 body,有标题栏 .header 部分的样式,还有内容区 .content 部分的样式。这样通过解析器的构造,可以得到类似下面这样的一棵 CSSOM 树:
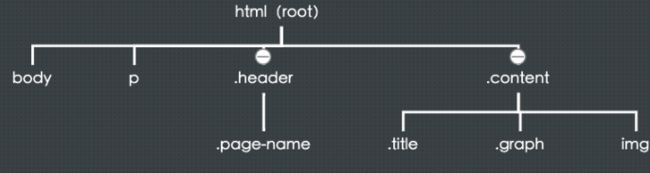
Tips:
1、 这棵树是一个示意图,并不是浏览器里构造 CSSOM 树的真实的数据结构,而且各种浏览器内核实现 CSSOM 树的方式也不全都相同。这部分内容可以参考 Google Web Fundamentals ,它把 CSSOM 树描述成自上而下建立的结构,类似这样:
这里也是按着这个文档里 CSSOM 的模型来示意的,不同的是把 HTML 节点作为了根节点。这是因为考虑到给 HTML 标签设置样式的时候同样会生效,所以 HTML 标签应该也存在于 CSSOM 树中。
2、CSSOM 树和 DOM 树是独立的两个数据结构,它们没有一一对应关系。DOM 树描述的是 HTML 标签的层级关系,CSSOM 树描述的是选择器之间的层级关系。
3、在 CSS 中存在样式的继承机制,有些属性在父节点设置后,在其后代节点都会具备这个样式。比如我们在 HTML 上设置一个 “font-size:20px;”,那么页面里基本所有的标签都可以继承到这个属性了。当然不是所有标签和属性都可以有继承特性的,比如 border 这种属性就不是可继承的。如果 border 可继承了,那么在一个父元素里设置上以后,所有子元素都会有个边框,这显然是不合理的。所以在大部分情况下,通过这种推理,就能知道哪些样式是可以继承的,而哪些不行。
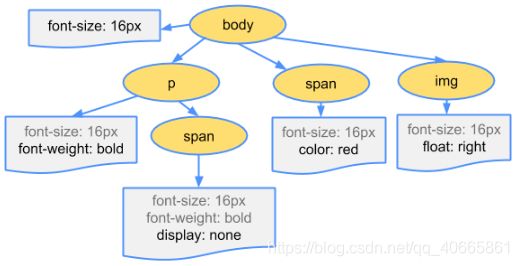
渲染树(Render Tree)的构建
在 DOM 树和 CSSOM 树都渲染完成以后,就会进入渲染树的构建工作。渲染树就是对 DOM 树和 CSSOM 树的结合,得到一个可以知道每个节点会应用什么样式的数据结构。这个结合的过程大体上是遍历整个 DOM 树,然后在 CSSOM 树里查询到匹配的样式。但在不同浏览器里这个过程也不太一样,在 Chrome 里会在每个节点上使用 attach() 方法,把 CSSOM 树的节点挂在 DOM 树上作为渲染树。然而在 Firefox 里,会单独构造一个新的结构,用来连接 DOM 树和 CSSOM 树的映射关系。它们内部的实现方式有所不同,但它们构造出来的渲染树是有很多共同点的。渲染树会有以下的特点:
1. 渲染树的根是 HTML 节点。
在 Google Web Fundamentals 这个文档中,渲染树的根节点是 body,但实际上 HTML 节点上的样式也是可以显示在页面上的,所以渲染树也应该是由 HTML 节点开始,但是 head 标签里的内容和显示没有关系,所以渲染树中可以没有 head 标签的部分。
2. 渲染树和 DOM 树 的结构并不完全一致。
渲染树里会把所有不可见的元素忽略掉,所以如果是 DOM 树中的节点有 “display: none;” 属性的节点以及它的子节点,最终都不会出现在渲染树中。但是具有 “visibility: hidden;” 样式的元素会出现在渲染树中,因为具有这个样式的元素是需要占位的,只不过不需要显示出来。
3. 样式优先级关系。
同一个 DOM 节点可能会匹配到多个 CSSOM 节点,而最终的表现由哪个 CSS 规则来确定,就是样式优先级的问题了。当一个 DOM 元素受到多条样式控制的时候,样式的优先级顺序应该是
内联样式 > ID选择器 > 类选择器 > 标签选择器 > 通用选择器 > 继承样式 > 浏览器默认样式
在有相同类型选择器的时候,还有一套计算方法,给不同的选择器都赋了一个权重值。当考察优先级的时候,直接用公式计算整条选择器的权重作为该样式的优先级。比如:
- 内联样式的权重是 1000。
- ID 选择器里样式的权重是 100。
- 类选择器、属性选择器和伪类选择器里样式的权重是 10。
- 标签选择器里样式的权重是 1。
- 通用选择器直接忽略。
那么在计算的时候,假设一个选择器里有 a 个权重值是 100的、b 个权重值是 10 的和 c 个权重值是1的选择器。那么这个选择器的权重值就 a100 + b10 + c。
Tips:
这个计算公式的形式就是这样,但有几点要注意:
1、这个计算模型仅供理解样式优先级关系,不能代表浏览器里真实的计算方法。
2、权重值的计算不能越级,比如选择器 A 只有 1 个 ID 选择器,权重就是 100;选择器 B 用了 20 个类选择器,权重值是 200。这个时候如果两个选择器对应的样式作用在同一个 DOM 节点上,那么还是选择器A会生效,因为它的选择器级别更高。
3、如果两个选择器 A 和 B 是同级别选择器,并且最终计算的权重值也相同,那么这两个选择器谁在后面谁优先级高。
参考上面渲染树的特点,由之前的 DOM 树和 CSSOM 树就可以构建出来一棵如下图的渲染树:
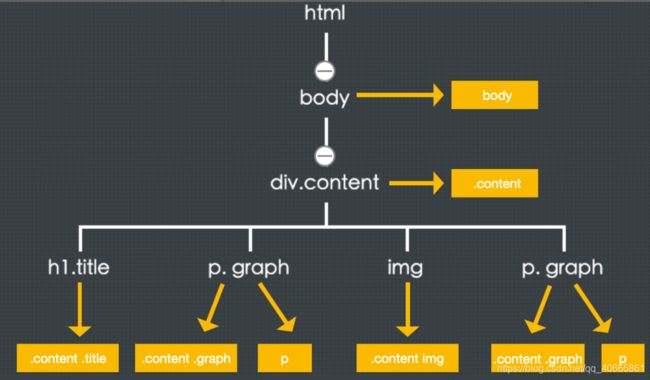
这棵渲染树中的节点是和 DOM 树中的节点对应的,而黄色框部分的内容就是从 CSSOM 树中查找出来的。从上图里可以看出来,这棵渲染树中去掉了 head 标签里的内容,也去掉了有 “display:none;” 样式的 .header 元素及其子元素。而渲染树里面的 p.graph 元素会同时对应两条样式。这就是一棵由 DOM 树和 CSSOM 树结合而来的渲染树。
Tips:
1、渲染树的构建过程中,会遍历 DOM 树中的可见节点,然后在 CSSOM 树中查找每个节点匹配的样式,最后通过组合这些可见节点以及和它们相匹配的样式就可以构建出一棵渲染树(带有“visibility: hidden;”属性的元素不可见,但会在页面中占位,所以会出现在渲染树中)。这里在查找的时候,出于效率的考虑,会从 CSSOM 树的叶子节点开始查找,对应在 CSS 选择器上也就是从选择器的最右侧向左查找。这就是在 2-4 讲解后代选择器时提到使用“.page .article p”会有效率问题的原因,这个选择器中会最先在 CSSOM 的所有叶子节点里查找 p 标签,这种标签类的选择器会很多且没有索引,会造成查找效率低下。不建议使用标签选择器和通配选择器的原因也是这个。
2、在 2-4 讲解兄弟选择器的时候,说过兄弟选择器为什么只能向后寻找兄弟元素。这是因为在生成渲染树的时候会遍历 DOM 节点来生成渲染树的节点,当遇到兄弟选择器的时候,它前面的兄弟元素在渲染树上的节点已经生成完毕,而它后面的兄弟节点还没有生成。这时候如果再回头去改前面兄弟节点的那就麻烦了,整个遍历的规则都要变化,而后面兄弟节点在生成的时候把兄弟选择器的影响加进去就可以。所以这就是为什么兄弟选择器只能向后寻找兄弟元素,而没提供向前寻找的方式。
布局(Layout)
经过上面的步骤,生成了一棵渲染树,这棵树就是我们展示页面的关键。通过计算渲染树上每个节点的样式,就能得出来每个元素所占空间的大小和位置。当有了所有元素的大小和位置后,就可以在浏览器的页面区域里去绘制元素的边框了。这个过程就是布局,英文中会用 Layout 这个词来描述。
绘制(Paint)
经过布局,每个元素的位置和大小就有了,经过最后绘制这一步,就可以把样式可视化的展现在屏幕上了。在绘制的过程中,浏览器会调用图形处理器,逐层逐块的把所有计算好位置和样式的元素都绘制出来。
当绘制工作结束,我们的页面就终于展示在浏览器上了。
重排(Reflow)与重绘(Repaint)
渲染树是动态构建的,DOM 节点和 CSS 节点的改动都可能会造成渲染树的重建。渲染树的改动就会造成重排或者重绘.
1、重排。
当我们在 DOM 树中新增、删除了元素,或者是改变了某些元素的大小、位置、布局方式等,在这个时候渲染树里这个有改动的节点和它会影响的节点,都要重新计算。在改动发生时,要重新经历 DOM 的改动、 CSSOM 树的构建、渲染树的构建、布局和绘制整个流程,这个过程就叫做“重排”,也有的叫做“回流”。
以刚才代码中隐藏的 .header 元素为例,假如我们通过 JS 把它的 “display:none;” 属性去掉,那么它就要显示在屏幕中。这种情况下会经历下面的过程
- DOM 树没有变化。
- CSSOM 树中这个样式节点里的 display 属性没有了。
- 渲染树中的变化就比较大了,因为之前 “display:none;” 的元素没有出现在渲染树中,所以这个时候渲染树就要再重新结合 DOM 树和 CSSOM 树,把 .header 这个元素和它的子元素都加到渲染树中来。
- 布局的过程也会有不小的花销,需要给新加进来的 .header 元素找到位置,然后再把后面影响到的所有元素的大小和位置都重新计算一遍。这样得到一个新的布局值。
- 最后就是按着新的布局,把 .header 和受它影响的元素都重新绘制一遍,这个页面的改动就生效了。
2、重绘
重绘是当我们改变元素的字体颜色、背景色等外观元素的时候,并不会改变它的大小和位置,也不会影响到其他元素的布局,这个时候就没有必要再重新构建渲染树了。浏览器会直接对元素的样式重新绘制,这个过程就叫做“重绘”。
我们还以上面的代码为例,假如我们想对 .content 元素加一个 “color: black;” 的样式。这个时候就会经历以下的过程:
- DOM 树没有变化。
- CSSOM 树中 .content 对应的节点加入一条 “color: black;” 的样式。
- Color 属性的改变不会造成渲染树结构的变化,所以会在现有的渲染树中找出 .content 元素,给它加上 “color: black;” 的样式。
- 因为存在样式继承机制,所以浏览器还会找到 .content 元素的子元素,如果有可以继承的节点,那么也要给这些节点加上 “color: black;” 的样式,这个例子中就会在 h1.title、p.graph 元素上都加入 “color: black;” 的样式。
- 不涉及位置变动,布局过程直接忽略。
- 对 .content 元素及其子元素占用的块重新绘制。
相对来说重排操作的消耗会比较大,所以在操作中尽量少的造成页面的重排。
Tips:
为了减少重排,可以通过几种方式优化:
1、不要逐项的更改样式,可以把需要改动的样式收集到一块,用一次操作改变。
2、可以使用 class 的变动代替样式的改变,也能达到第1条的效果。
3、不要循环操作 DOM,循环的结果也要缓存起来,最后用一次操作来完成。
4、需要频繁改动的元素(比如动画)尽量使用绝对定位,脱离文档流的元素会减少对后面元素的影响。
5、在条件允许的情况下尽量使用 CSS3 动画,它可以调用 GPU 执行渲染。
CSS屏幕适配方案
为什么需要适配
现在市面上的设备尺寸没有统一的标准,考虑到设备的用途不同,将来也不会统一。所以我们前端开发人员就要通过屏幕适配,保证我们开发的页面在绝大多数设备上都可以正常显示。这里说的绝大部分而不是全部设备,是因为确实存在个别偏差比较大的设备,如果这部分用户量很少且适配代价会很大,那么忽略这一小部分的设备也是可以的。适配的最终目的,就是为了让设计稿在大部分的移动设备上看起来有一致的展示效果。
计量单位
在讲适配之前,我们要先介绍一下和设备有关的计量单位。知道这些计量单位以及它们之间的换算关系后,才能更好的理解后面要讲的屏幕适配方案。
一、物理像素
现在的设备基本上用的都是液晶屏,这种屏幕的显示原理就是在一块屏幕区域上规则排布很多个发光二极管,系统通过控制这些发光点的颜色和亮度来达到显示的作用。在一块屏幕区域上,每一个发光点,就是我们说的一个物理像素。一些屏幕厂商标识的分辨率指的就是这个物理像素的多少,比如华为 P30 手机标的屏幕像素是 1080×2340,就表示这块屏幕上每行有 1080 个物理像素点,每列上有 2340 个物理像素点。
Tips:
1、物理像素点是屏幕的自身属性,设备一出厂这个数值就是固定的了。
2、物理像素只是设备的属性,一般和开发者没什么关系,我们的代码也不会直接去操作物理像素。
二、逻辑像素 px
我们在写样式的时候,用的最多的应该就是 px 这个单位,这个 px 就是逻辑像素。现在的设备宽度最小的有 320 个物理像素,最大的能到一两千,所以设备在显示的时候如果直接使用物理像素来显示,那显示效果间的差异是非常大的。比如一个宽 320 像素的按钮,在宽 320 物理像素的屏幕上会占满正个屏幕,而在宽 1242 物理像素的屏幕上,这个按钮只能占差不多四分之一的宽度,这个差距实在太大,并且不容易抹平。
所以,这些设备厂商为了解决这个问题,提出了逻辑像素的概念。逻辑像素的出现就是要尽量抹平不同物理像素设备间的显示差异。还以刚才的例子来说,320 物理像素宽的设备上,我们让 1 逻辑像素 = 1 物理像素,那整个宽度还是能容下 320px 的内容;而对于 1242 宽度的设备,我们让它 1 逻辑像素 = 3 物理像素,这样相当于这块屏幕可以放下 414px 的内容。这时候再定义一个 320像素宽的按钮,在低分辨率上是占满整个宽度,而在高清屏上也能占四分之三左右的宽度,这种显示效果就已经很相近了。
之所以屏幕的逻辑像素没有统一成一种,一是因为屏幕的物理尺寸不一样,二是因为大的屏幕就是要多显示一点东西,不能完全迁就最低配置的屏幕。厂商可以通过控制逻辑像素和物理像素间的换算系数,来保证同样 px 的元素在不同屏幕上显示出来的大小尽量相似。
Tips:
高分辨率屏幕上会把多个物理像素当成 1 个逻辑像素来用,但不会和低清屏幕上一样,把 1 个逻辑像素里的多个物理像素显示成同样的颜色。所以高分辨率屏幕虽然和低分辨率屏幕的逻辑像素差不多,但在显示细节和清晰度上还是有区别的,这就是为什么高清屏的显示效果会更细腻。
三、设计像素
设计像素是指 UI 设计师做设计稿时使用的像素值,通常情况下是按着设备的物理像素来确定设计稿尺寸的。
因为设备虽然逻辑像素差不多少,但同样 1px 的内容,有的设备用 1 个物理像素点显示,而有的用 9 个物理像素点来显示。如果设计稿使用的分辨率够大,那么高分辨率的屏幕里每 px 里的 9 个物理像素可以显示不同的颜色,而低分辨率屏幕里只能把图片里相近的颜色做合并,显示在一个物理像素上。所以用高清的设计稿,最终做出来的显示效果会更细腻。在公司里,设计像素一般用到 1080 的宽度也就差不多了。
四、相对像素 em 和 rem
我们刚才说的 px 单位,它是一种绝对像素,给一个元素多少 px,那么这个元素的宽就定死了。而在 CSS 里还有一种计量方式,就是相对像素。相对像素在响应式开发的时候会显得更灵活。相对像素的单位有 em 和 rem 两种:
- 相对像素 em。em 这个单位是相对于父元素的 font-size 字号值,实际就是父元素 font-size 的几倍。这个字号可以是 CSS 指定的,也可以是从父元素的父元素继承来的,如果前两个都没有,就会使用默认值(一般是16px)。假如父元素指定了 “font-size:20px;” ,子元素使用了 “width: 8em” ,那么子元素的实际宽度就是 160px。
我们在使用 em 单位的时候,如果 HTML 层级太深,这个相对关系就容易乱,并且其中一个节点改动字号的话,里面的子元素的 em 值都要重新调整,会造成不便。 - 相对像素 rem。rem 和 em 很相似,只不过它是相对于根节点,也就是 HTML 节点的 font-size 属性指定的 px 值。页面里所有用 rem 作为长度单位的元素,就都以 HTML 为准,这样就不用使用 em 那种比较麻烦的换算了,并且当页面里的元素改变字号时,不会对其他元素造成影响。
Tips:
em 是一个很早就出现的单位,IE6 都可以兼容。但是 rem 是 CSS3 的属性,使用的时候要注意它的兼容性问题。目前 rem 通常应用在移动端的 WEB 开发上。
屏幕适配方案
在做屏幕适配的时候,通常是选择一个大小适中的设备作为基准尺寸,然后再对其他尺寸的设备做适配。比较常见的适配方法有下面几种:
一、百分比方式适配
用百分比做适配的方式是比较原始的一种适配方式。我们通过给元素设置一个百分比的值,让这个元素自动调整它的大小或位置等。这种方式出现的最早,也是在使用的时候最方便的。Bootstrap 框架在很多地方就采用了这种方案。
百分比适配有如下优点:
- 简单便捷,不用关心元素的绝对宽度。
- 基本没有兼容性问题。
但是这种适配方式缺点也是很明显的:
- 使用百分比时候,很容易不是整数,比如设计稿是一行里三个元素等分距离,如果用百分比,那每个的宽度就是 33.33333%。这样百分比是很长的小数,还要自己计算百分比的值,最严重的是经过百分比的计算后有可能最后整行宽度会留有空白。
- 百分比的值是相对于父元素来计算的。子元素宽度的百分比是相对父元素宽度,子元素的高度的百分比是相对于父元素的高度,子元素的内外边距都是相对父元素的宽度,这些属性是相对谁的容易弄混。
- 当同一行里同时存在定宽元素和自适应的元素时,使用百分比就不太利于分配空间。
- 如果父子元素都脱离了文档流,那么它父元素的宽度就可能没有了,这时候子元素用百分比就会失效。
通过用百分比的方式适配的话,在一些情景下是非常方便的,比如一行内等距放 4 个元素,就可以每个元素 25% 的宽度,一条语句就可以搞定,但考虑到百分比适配的缺点,并不推荐所有地方都强制使用百分比进行适配。我们的项目中,用到百分比适配比较多的是需要撑开整个屏幕的情况,如头部标题栏、导航和全屏宽的按钮等设置宽度的时候,就可以直接给元素“width: 100%;”。
二、多套样式分段适配
第二种适配方案就是制作多套样式,然后根据屏幕宽度来选择合适的那套样式。这种适配方式一般是在 HTML 或 body 上添加一些 class 来控制。
京东的 PC 端页面,当浏览器宽度大于 1190px 时,就会在 HTML 标签上加上 o2_wide 的 class,这时候页面的主要内容区也是定宽 1190px 的一个框子。当浏览器小于 1190px时,就会把 o2_wide 变成 o2_mini,这时候主要显示区的宽度就变成了 990px。京东实际上是实现了两种宽度的页面,然后通过 JS 判断页面宽度来选择应用哪一套。
淘宝的 PC 端会做的更精细一点,会把适配方案分成 990px、1024px、1190px、1279px、1365px、1440px 这些档,对每一种宽度都做了一套样式。然后也是通过 JS 控制 body 上的 class 来控制生效的样式。
上面两个例子都是使用 JS 来控制 DOM 元素上的 class 来实现的,在 CSS3 中还有一种控制方式叫媒体查询。媒体查询可以直接用 CSS 根据浏览器页面宽度判断使用哪套样式方案。原理和上面的一样,只不过用媒体查询代替了上面的 JS 逻辑。
这种适配方案有如下的优点:
- 更灵活,比如可以借助根节点上的 class 来控制更多的内容。比如在宽屏幕上指定一行显示 4 个元素(每个宽 25%),如果在窄屏幕上可以让一行显示 5 个(每个宽 20%)。
- 页面宽度是固定的几档,测试的时候比较方便。
- 使用 JS 控制 class 的方式一般不会出现兼容性问题,通常应用在有兼容性要求的 PC 端页面。
但这种方式的不足也比较明显:
- 需要制作多套设计稿,也需要多套样式代码,工作量比较大。
- 要维护多套样式,有改动的时候比较麻烦。
- 不能在所有设备下都撑满全屏,不适合移动端。
这种适配方案在适配时一般都是设计一套基准宽度的样式,其他宽度下的样式用覆盖的方式来控制。
三、Rem 方式适配
最后就是要说 Rem 方式的适配了。在做屏幕适配的时候,通过控制 HTML 的 font-size 属性就可以了。
第一步,限定基准尺寸屏幕下的 HTML 字号。我通常会给 HTML 节点设置上 20px 的字体,这样做 px 到 rem 的转换时比较容易。
第二步,在其他尺寸屏幕上,修改 HTML 字号值。在 rem 适配中,因为只需要控制 HTML 字号就可以达到屏幕适配的目的。而在变动这个字号的时候可以像百分比适配那样做连续的变动,直接按着屏幕宽度和标准尺寸的比例关系修改字号即可;也可以用分段适配的方式,在某一个宽度范围内用哪一种字号。对字号的控制还是比较灵活的。
Rem 适配的优点:
- Rem 的参考值只有一个,就是 HTML 字体大小,所以不会像百分比适配那样要明确参考谁。
- Rem 使用的范围比较广,元素的高度宽度、border 宽度、字号大小、间距和偏移量等都可以用 rem 做单位
- Rem 适配的时候不需要做多套样式,可以直接按比例改变 HTML字体的大小。
Rem 适配的缺点:
- Rem 是 CSS3 的属性,只有比较新的浏览器上可以使用,一般都是用在移动端。目前大厂的 H5 页面,基本都在使用 Rem 方式做屏幕适配了。
- Rem 最后换算出来的值还是 px,所以对于按比例分配空间这种需求是没法满足的,需要和其他适配方式混合使用。
四、弹性布局适配
最后说一下弹性布局,这也是 CSS3 里出现的一种适配方式。弹性布局融合了百分比布局和固定宽度布局的优点,并且用起来更加简单。弹性布局下盒模型可以不用指定宽度,直接让盒子把可利用空间填满,这样既不用去计算盒子的宽度,也不用担心固定宽度元素和需要适配的元素在同一行显示的问题了。
弹性布局的优点有:
- 可以弹性地利用页面空间,且不需要计算宽度比例。
- 每行元素个数变化时,不用重新调整元素的宽度。
- 弹性布局中的高级属性能带来更多的功能,比如可以指定元素的排列方式和排列顺序等,这些功能用传统的 CSS 是不太好实现的。
而弹性布局最重要的缺点就是兼容性问题,在移动端有些弹性布局的属性都还没有得到完全的支持,在使用时一定要做详细的测试。这个项目中的标题栏、底部导航、网格等组件中,都使用了弹性布局。
CSS规范
文件引用规范
先说加载的规范,这个规范主要是为了提高页面加载速度或者是首屏的速度。
- CSS 文件或样式在 head 标签中引用。页面的渲染需要 CSS,所以尽量早的让 CSS 文件加载出来。
- JS 文件要放在 body 标签尾部。页面里加载和运行 JS 都会阻塞页面的渲染过程,所以把 JS 放在尾部可以加快首屏显示的速度,但对整个页面完成加载的时间没什么影响。
- 使用压缩后的文件。线上使用的静态文件,尽量都是压缩好的,CSS 使用 .min.css 形式,JS 使用 .min.js 形式,这样可以减少文件的体积,从而减少下载的时间。
- 减少 import 方式引用 css 文件。import 方式引入的 CSS 文件要等原 CSS 文件加载并解析后才会去请求,会拖慢 CSS 文件的加载速度。
选择器的书写规范
CSS 选择器在使用的时候尽量遵从以下规范:
一、选择器命名规范
- 选择器都用小写字母。
- 选择器的命名要使用英语,这是编程的通用语言。
- 选择器的名字尽量简短,但要有实际意义,不能为了文件的体积而忽略代码的可读性。
- 逗号后要有空格,一般在选择器的逗号后面加一个空格,这样不至于看起来拥挤。
- 使用-分割,如果有需要多个单词的选择器,几个单词中间用-分隔,比如 page-wrap、btn-small 等。
二、选择器使用规范
- CSS 的属性中需要引号的地方使用单引号,HTML 中的属性使用双引号。
- CSS 选择器在使用的时候,要把样式限定在某个 HTML 区域里生效。这样可以防止不同区域的元素互相影响
选择器合并。有相同样式的多个选择器,使用分组选择器,可以减小文件的体积。 - 尽量不使用通配选择器或标签选择器。这两种选择器效率比较低,尽量使用类选择器来代替,只有在需要改变元素默认属性的时候再使用。
- 最右侧的选择器尽量精确。选择器中最后一位的选择器尽量使用类选择器这种比较精确的选择器,因为选择器的读取是由右至左,最右边的选择器会先去遍历,如果最后使用了标签选择器,那么查找样式的消耗就会增多。
- 选择器的嵌套不宜太长。选择器在读取的时候都是一层层的去查找的,所以使用太长的选择器也会增加查找的消耗。
- 在可以的情况下用子代选择器代替后代选择器。子代选择器只需要做一层的查找,而后代选择器需要一直查找到根节点,所以子代选择器的效率会更高一点。
- 使用样式继承。对于可以继承的样式,尽量在父节点加入样式,而不要给每一个子节点都加样式。
属性的书写规范
一、使用缩写
1、属性的缩写。CSS 中有些属性是可以合并的
margin: 10px 5px 0;
2、颜色的缩写。在使用十六进制颜色的时候,如果 rgb 三个颜色位置中,每两位的颜色值相同,可以把六位的颜色写成三位。
3、数字的缩写。在 CSS 中如果整数部分是 0 的小数,可以忽略小数点前面的 0;如果属性值是 0,则可以忽略属性值的单位。
二、属性顺序的规范
理论上,CSS 的属性是一条一条解析执行的。这种情况下,就要把能确定大小和位置的属性写在前面,把对布局没什么影响的属性写在后面,避免返工。一般说的使用顺序如下:
- 位置属性 (position, top, right, z-index, display, float等)
- 大小 (width, height, padding, margin)
- 文字系列 (font, line-height, letter-spacing, color- text-align等)
- 背景 (background, border等)
- 其他 (animation, transition等)
三、属性使用的规范
- 不大面积的使用 gif 图片。显示 gif 图片的消耗比较大,所以一个页面里不要大面积使用 gif 图片。
- 尽量不要对图片进行缩放,这也是一个高消耗的操作。
- 减少高消耗属性的使用 box-shadow/border-radius/filter/ 透明度 /:nth-child 等
- 动画里使用 3D 属性代替一般属性,如使用 transform、scale 等代替原始的 width、height、margin 等,因为这些 CSS3 的属性可以调用 GPU 进行渲染,会减少资源的消耗并提高动画的流畅度。
注释规范
在代码里还有比较特殊的一部分就是注释。这部分内容不参与代码的运行,只是为了提供给开发者看。我们对注释有如下要求:
一、文件头注释。
在文件头部加上注释是为了记录文件的创建者、创建时间、最后更改者和更改时间。这样在一个项目组里,如果遇到开发上的问题,可以直接根据文件头的注释找到这个文件所属人和操作时间。
二、普通注释。
在业务里也需要注释,这种注释我们用标准的注释圈起来就行,最好是在注释的文本两边留下个空格,这样不会显得拥挤。
CSS-Reset
在浏览器里每个元素都有默认的样式,也就是你不给它任何样式也是可以显示的。但问题是,不同的浏览器中默认样式是不一致的,并且这些样式也可能和我们的业务代码有冲突。因此我们在开发的时候就要把这些默认样式的差异抹平,用到的方式就是 CSS-Reset。
CSS-Reset 的做法其实就是自己写一组 CSS 样式,把浏览器的默认样式覆盖掉。这样即可以抹平浏览器的差异,还可以自己定义元素的默认样式。CSS-Reset 是一组公共的样式,所以在它里面使用标签选择器还是比较合适的(也有用通用选择器的,效率更低,不推荐)。
后续文章: 第二章.