第16课:RDD实战学习笔记
第16课:RDD实战
本期内容:
1. RDD实战
2. RDD的Transformation与Action
3. RDD执行手动绘图
RDD的操作:
1 Transformation:数据状态转换,即算子,是基于已有的RDD创建一个新的RDD
2 Action:触发作业。是最后取结果的操作。因为RDD是Lazy级别的,性能非常高,从后往前回溯。如foreach/reduce/saveAsTextFile,这些都可以保存结果到HDFS或给Driver。
3 Controller:性能、效率、容错的支持。即cache/persist/checkpoint

RDD.scala类中的map函数的源码如下:
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
可以看出map函数收受一个参数,这个参数本身是个函数f,传入类型为T,返回类型为U。map函数内部会产生一个MapParititionsRDD,对已有的map作用的RDD的每个元素自定义一个函数f来处理每一个元素,元素的类型就是T,返回的类型就是U,基于U类型的元素构成集合产生新的RDD。
RDD.scala类中的reduce函数的源码如下:
/**
* Reduces the elements of this RDD using the specified commutative and
* associative binary operator.
*/
def reduce(f: (T, T) => T): T = withScope {
val cleanF = sc.clean(f)
val reducePartition: Iterator[T] => Option[T] = iter => {
if (iter.hasNext) {
Some(iter.reduceLeft(cleanF))
} else {
None
}
}
var jobResult: Option[T] = None
val mergeResult = (index: Int, taskResult: Option[T]) => {
if (taskResult.isDefined) {
jobResult = jobResult match {
case Some(value) => Some(f(value, taskResult.get))
case None => taskResult
}
}
}
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}
reduce函数是对RDD中的所有元素进行聚合操作,得出最终结果返回给Driver。要符合结合律(commutative )和交换律(associative)。原因是reduce操作时并不知道哪个数据先到,所以必须满足交换律,另一方面,只有满足结合律才能进行reduce。
Transformation的特点就是Lazy,Lazy就是Spark应用程序中使用Transformation操作只是标记这个操作,而不会真正执行。只有在遇到Action或Checkpoint时才会真正执行操作,通过Lazy特性就可以对Spark应用程序进行优化。原因是一直延迟执行,Spark就可以看到很多步骤,看到的步骤越多,优化的空间越大。最简单的就是把所有的步骤合并。
Action会触发JOB。sc.runJob方法导致作业运行。
下面以统计文件中相同行的个数为例
package SparkRDDTest
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
//相同行出现的总次数
object TextLines {
def main (args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("TextLines")
conf.setMaster("local")
val sc = new SparkContext(conf)
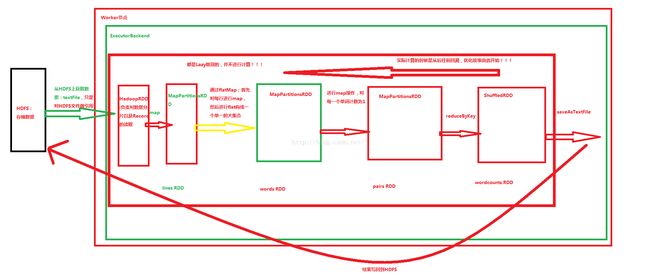
val lines = sc.textFile("D:\\DT-IMF\\tmp\\16-textLines.txt")//通过HadoopRDD及MapPartitionsRDD获取文件中每一行的内容本身 。
val lineCount = lines.map(line => (line,1))//每一行变成行的内容与1构成的Tuple
val textLines = lineCount.reduceByKey(_+_)
textLines.collect.foreach(pair => println(pair._1 + " : " + pair._2))
//collect是把结果收集起来变成数组。如果在集群中运行的话,没有collect,运行结果就会分布在各个节点上,无法看到全部内容。
}
}
运行Log及运行结果:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/03/21 00:38:28 INFO SparkContext: Running Spark version 1.6.0
16/03/21 00:38:36 INFO SecurityManager: Changing view acls to: think
16/03/21 00:38:36 INFO SecurityManager: Changing modify acls to: think
16/03/21 00:38:36 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(think); users with modify permissions: Set(think)
16/03/21 00:38:42 INFO Utils: Successfully started service 'sparkDriver' on port 52495.
16/03/21 00:38:44 INFO Slf4jLogger: Slf4jLogger started
16/03/21 00:38:44 INFO Remoting: Starting remoting
16/03/21 00:38:45 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:52515]
16/03/21 00:38:45 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 52515.
16/03/21 00:38:46 INFO SparkEnv: Registering MapOutputTracker
16/03/21 00:38:46 INFO SparkEnv: Registering BlockManagerMaster
16/03/21 00:38:46 INFO DiskBlockManager: Created local directory at C:\Users\think\AppData\Local\Temp\blockmgr-e7fd197a-de23-4211-86e9-5c00315cc4fe
16/03/21 00:38:46 INFO MemoryStore: MemoryStore started with capacity 1773.8 MB
16/03/21 00:38:47 INFO SparkEnv: Registering OutputCommitCoordinator
16/03/21 00:38:48 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/03/21 00:38:48 INFO SparkUI: Started SparkUI at http://192.168.56.1:4040
16/03/21 00:38:49 INFO Executor: Starting executor ID driver on host localhost
16/03/21 00:38:49 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 52531.
16/03/21 00:38:49 INFO NettyBlockTransferService: Server created on 52531
16/03/21 00:38:49 INFO BlockManagerMaster: Trying to register BlockManager
16/03/21 00:38:49 INFO BlockManagerMasterEndpoint: Registering block manager localhost:52531 with 1773.8 MB RAM, BlockManagerId(driver, localhost, 52531)
16/03/21 00:38:49 INFO BlockManagerMaster: Registered BlockManager
16/03/21 00:38:56 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 127.4 KB, free 127.4 KB)
16/03/21 00:38:57 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 141.3 KB)
16/03/21 00:38:57 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:52531 (size: 13.9 KB, free: 1773.7 MB)
16/03/21 00:38:57 INFO SparkContext: Created broadcast 0 from textFile at TextLines.scala:13
16/03/21 00:38:59 WARN : Your hostname, think-PC resolves to a loopback/non-reachable address: fe80:0:0:0:d401:a5b5:2103:6d13%eth8, but we couldn't find any external IP address!
16/03/21 00:39:01 INFO FileInputFormat: Total input paths to process : 1
16/03/21 00:39:02 INFO SparkContext: Starting job: collect at TextLines.scala:16
16/03/21 00:39:03 INFO DAGScheduler: Registering RDD 2 (map at TextLines.scala:14)
16/03/21 00:39:03 INFO DAGScheduler: Got job 0 (collect at TextLines.scala:16) with 1 output partitions
16/03/21 00:39:03 INFO DAGScheduler: Final stage: ResultStage 1 (collect at TextLines.scala:16)
16/03/21 00:39:03 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
16/03/21 00:39:03 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
16/03/21 00:39:03 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[2] at map at TextLines.scala:14), which has no missing parents
16/03/21 00:39:03 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.9 KB, free 145.2 KB)
16/03/21 00:39:03 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.2 KB, free 147.4 KB)
16/03/21 00:39:03 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:52531 (size: 2.2 KB, free: 1773.7 MB)
16/03/21 00:39:03 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
16/03/21 00:39:03 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[2] at map at TextLines.scala:14)
16/03/21 00:39:03 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
16/03/21 00:39:03 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2127 bytes)
16/03/21 00:39:03 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
16/03/21 00:39:04 INFO HadoopRDD: Input split: file:/D:/DT-IMF/tmp/16-textLines.txt:0+41
16/03/21 00:39:04 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
16/03/21 00:39:04 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
16/03/21 00:39:04 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
16/03/21 00:39:04 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
16/03/21 00:39:04 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
16/03/21 00:39:04 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver
16/03/21 00:39:05 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1225 ms on localhost (1/1)
16/03/21 00:39:05 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/03/21 00:39:05 INFO DAGScheduler: ShuffleMapStage 0 (map at TextLines.scala:14) finished in 1.355 s
16/03/21 00:39:05 INFO DAGScheduler: looking for newly runnable stages
16/03/21 00:39:05 INFO DAGScheduler: running: Set()
16/03/21 00:39:05 INFO DAGScheduler: waiting: Set(ResultStage 1)
16/03/21 00:39:05 INFO DAGScheduler: failed: Set()
16/03/21 00:39:05 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[3] at reduceByKey at TextLines.scala:15), which has no missing parents
16/03/21 00:39:05 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.6 KB, free 150.0 KB)
16/03/21 00:39:05 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1584.0 B, free 151.5 KB)
16/03/21 00:39:05 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:52531 (size: 1584.0 B, free: 1773.7 MB)
16/03/21 00:39:05 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006
16/03/21 00:39:05 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[3] at reduceByKey at TextLines.scala:15)
16/03/21 00:39:05 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
16/03/21 00:39:05 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, partition 0,NODE_LOCAL, 1894 bytes)
16/03/21 00:39:05 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
16/03/21 00:39:05 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
16/03/21 00:39:05 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 56 ms
16/03/21 00:39:05 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1377 bytes result sent to driver
16/03/21 00:39:05 INFO DAGScheduler: ResultStage 1 (collect at TextLines.scala:16) finished in 0.459 s
16/03/21 00:39:05 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 443 ms on localhost (1/1)
16/03/21 00:39:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/03/21 00:39:05 INFO DAGScheduler: Job 0 finished: collect at TextLines.scala:16, took 2.961711 s
spark : 3
hadoop : 1
flink : 1
mysql : 1
16/03/21 00:39:05 INFO SparkContext: Invoking stop() from shutdown hook
16/03/21 00:39:06 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
16/03/21 00:39:06 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/03/21 00:39:06 INFO MemoryStore: MemoryStore cleared
16/03/21 00:39:06 INFO BlockManager: BlockManager stopped
16/03/21 00:39:06 INFO BlockManagerMaster: BlockManagerMaster stopped
16/03/21 00:39:06 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/03/21 00:39:06 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
16/03/21 00:39:06 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
16/03/21 00:39:06 INFO SparkContext: Successfully stopped SparkContext
16/03/21 00:39:06 INFO ShutdownHookManager: Shutdown hook called
16/03/21 00:39:06 INFO ShutdownHookManager: Deleting directory C:\Users\think\AppData\Local\Temp\spark-7de87da4-c5dd-403f-97f4-25d7ad069317
collect是个Action,在源码中处于RDD.scala,
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
runJob会产生一个Array,包含程序运行的所有结果。
foreach就是对数组进行循环,数组内就是Tuple。因为reduceByKey时变成 了KV方式构成的Tuple。
foreach不能直接自动进行模式匹配。
collect是把集群中处理的数据的各个节点上的数据收集起来,汇总后变成最终结果。
foreach只是一个循环器而已,不能用模式匹配。
foreach的源码(位于IndexedSeqOptimized类中):
def foreach[U](f: A => U): Unit = {
var i = 0
val len = length
while (i < len) { f(this(i)); i += 1 }
}
从源码可以看出,foreach循环遍历每一个元素,把元素作为编写函数的输入参数。
collect后Array中只有一个元素,只不过这个元素是一个Tuple(Tuple里是KV)。从各节点把数据拿来后放在当前数组里(元组数组)。
collect的源码(位于RDD.scala类中)
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
concat的源码(位于Array.scala类中)
* @param xss the given arrays
* @return the array created from concatenating `xss`
*/
def concat[T: ClassTag](xss: Array[T]*): Array[T] = {
val b = newBuilder[T]
b.sizeHint(xss.map(_.size).sum)
for (xs <- xss) b ++= xs
b.result
}
Driver从各个节点抓到结果,通过Array的concat方法合并。
下面运行一下代码:
sc.textFile(“data”).flatMap(_.split(“ ”)).map(word => (word,1)).reduceByKey(_+_,1).saveAsTextFile(“result.txt”)
这里reduceByKey(_+_,1)除了指定reduce的算法外还指定了参数1,这个参数1其实是并行度,这导致运行时产生的结果是一个文件。
data目录下有88个文件,查看运行结果可以看到有89个任务,原因是reduce分片时传入了参数1,这就变成了一个任务。如果传入参数是2,那么就会有176个任务了。
查看Details for Job 0可以看到这个Job由两个Stage,Stage0中有textFile/flatMap/map,Stage1中有reduceByKey和saveAsTextFile。
Stage0中有88个任务,因为textFile有88个文件,每个文件小于128MB,所以还是把这88个文件作为一个处理单位。
saveAsTextFile只有一个分片,是因为我们指定了并行度为1。
点击stage0查看Details for stage0可以看到所有任务运行在4台worker上。

其中Worker3上运行了45个任务,而reduce任务也在Worker3上,这里就是通过读本地磁盘的方式获取数据。其他任务都运行在另外3台Worker上。
reduce任务之所以知道从哪里获取数据,是shuffle的管理方法。上一个Stage的输出会交给
MapOutputTracker。Driver会记录输出路径。下一个stage运行时会找Driver要上个Stage的输出路径。
如果希望输出只有一个文件,唯一的办法就是控制并行度。当然也可以控制前面的并行度也可以。因为并行度会遗传。
并行度和Shuffle没有关系,Shuffle是由RDD的依赖关系决定的。并行度关系到执行效率。
如果要把10万个并行度改为100个可以吗?
=> 一般不可以。因为如果把10万个并行度改为100个,那么每个任务就会耗费大量内存,在原有CPU Cores不变的情况下,容易出现OOM。
如果不指定Partitioner或并行度的参数时,就会直接传递到后面去。
★ 设置多少个并行度,就会有多少个Partition。
默认情况下,从磁盘上读取数据分片时,有多少个分片就会有多少并行度。这里有88个文件,每个文件都小于128MB,所以并行度为99。
下面画图讲解WordCount的执行过程: