【深度学习】深度神经网络Inception结构以及作用
Inception V1-V4总结:
Inception V1:
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,
一方面增加了网络的width,
另一方面增加了网络对尺度的适应性;
Inception V2:
一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯;
另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
Inception V3:
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),
这样的好处,
既可以加速计算(多余的计算能力可以用来加深网络),
又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,
还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
Inception V4:
v4研究了Inception模块结合Residual Connection能不能有改进?
发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,
同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能
GoogLeNet:

Inception-v3结构:

(图中框住的地方应为5层)

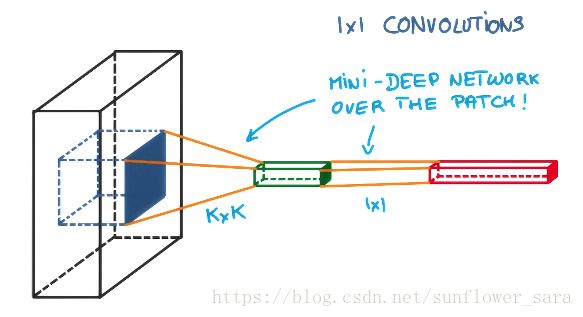
1*1 conv的作用:
简单说,是特征降维,是feature pooling,filter space的transform。这种跨特征层的级联结构,可以有助于不同特征层间的空间信息交互。论文中语:”This cascaded cross channel parameteric pooling structure allows complex and learnable interactions of cross channel information”。
这篇文章的解释:http://iamaaditya.github.io/2016/03/one-by-one-convolution/
全0填充,不改变图像的长宽,减小深度
可以在保持网络结构不变的情况下,减小网络参数的个数
pooling的作用:
减小参数,但是要保持长宽不变
缩小矩阵尺寸,减少全连接层的参数个数
加快计算,防止过拟合
如何将不同通道连接起来:
所有图像的长宽不变,深度不同,在深度维度将不同模块拼接起来。
和inception结构之前相比长宽不变,深度改变




youtube上有用的Inception介绍视频,强烈推荐:
http://ziyubiti.github.io/2016/11/13/googlenet-inception/
https://www.youtube.com/watch?v=1OCsi0krPgg
https://www.youtube.com/watch?v=cwBdAQXpDZM
在迁移学习过程中利用Inception-V3模型,获取模型各层的名称,请参考本博客的另一篇博文“Tensorflow中InceptionV3模型迁移学习获取tensor的name”:
https://mp.csdn.net/postedit/80686345
参考:
模型结构比较:
https://blog.csdn.net/u014114990/article/details/52583912
结构的解析请参照下面的文章链接:
1.深度神经网络Google Inception Net-V3结构图 :
https://www.jianshu.com/p/3bbf0675cfce
2.深度学习卷积神经网络——经典网络GoogLeNet(Inception V3)网络的搭建与实现:
https://blog.csdn.net/loveliuzz/article/details/79135583