HDFS-NFS
本文主要是自己在调研hdfs-nfs过程中的学习记录
NFS原理
NFS原理应用介绍:https://www.cnblogs.com/me80/p/7464125.html
HDFS的NFS
原生的HDFS是采用服务器本地磁盘实现,在数据读取上具有很好的本地化优势,但是本地实现方式存在容量使用率低,影响计算等,目前典型的HDFS实现方式主要包括:
1:专业存储方式,
2:HDFS连接器方式(HDFS连接器方式就是把NFS通过适配,转换成HDFS)
3:DFS客户端接口。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
NFS允许HDFS挂载到本地文件系统。
1:用户可以浏览HDFS文件系统通过本地的文件系统挂载HDFS提供的NFS功能
2:用户可以下载HDFS文件在本地文件系统。
3:用户可以直接上传文件从本地文件系统到hdfs
4:用户可以通过挂载点将数据直接流到HDFS。支持文件追加,但不支持随机写。
配置HDFS的NFS
在非安全模式下:
在非安全模式下,运行gateway 的用户是代理用户,而在安全模式下,Kerberos keytab中的用户是代理用户。假设代理用户是“nfsserver”,属于组“users-group1”和“users-group2”的用户使用NFS装载,然后在core-site.xml中使用。在NameNode的xml中,必须设置以下两个特性,只有NameNode需要在配置更改后重新启动(注意:用集群中的代理用户名替换字符串'nfsserver'):
在安全模式下:
对于kerberos化的hadoop集群,需要向hdfs-site.xml添加以下配置。用于网关的xml(注意:用代理用户名替换字符串“nfsserver”,并确保keytab中包含的用户也是相同的代理用户):
在AIX系统下:
AIX 系统下:常规的非AIX客户机不应该启用AIX兼容模式。AIX兼容模式实现的变通方法有效地禁用了保护措施,以确保通过NFS列出的目录内容返回一致的结果,并确保发送到NFS服务器的所有数据都已提交。(AIX系统介绍:https://blog.csdn.net/konglongaa/article/details/78814527)
其他配置属性:
强烈建议用户根据用例更新一些配置属性。可以在hdfs-site.xml中添加或更新所有下列配置属性。
1、设置如果客户端加载导出时允许访问时间更新。
请确保配置文件中没有禁用以下属性。只有NameNode需要在此属性更改后重新启动。在一些Unix系统中,用户可以通过使用“noatime”挂载导出来禁用访问时间更新。如果导出挂载了“noatime”,用户不需要更改以下属性,因此不需要重新启动namenode。
Setting a value of 0 disables access times for HDFS.
----------------------------------------------------------------改完配置文件需要重启namenode或者集群---------------------------------
2:用户设置随机写入的转储目录
用户需要更新文件转储目录。NFS客户端经常重新排序写操作。顺序写入可以以随机顺序到达NFS网关。此目录用于在向HDFS写入之前临时保存无序写入。对于每个文件,在累积到超过内存中的某个阈值(例如1MB)之后,会转储无序写入。需要确保目录有足够的空间。例如,如果应用程序上传了10个文件,每个文件都有100MB,建议这个目录有大约1GB的空间,以防出现最坏的情况——写重排hap
3、可以挂载的主机和权限
默认情况下,导出可以由任何客户机挂载。为了更好地控制访问,用户可以更新以下属性。值字符串包含机器名和访问权限,用空格字符分隔。机器名格式可以是单个主机、Java正则表达式或IPv4地址。访问权限使用rw或ro指定对导出的计算机的读/写或只读访问。如果没有提供访问权限,默认为只读。条目之间用“;”分隔。
4、设置JVM和log日志级别:
JVM和日志设置。您可以在hadoop op_nfs3_opts中导出JVM设置(例如,堆大小和GC日志)。在hadoop-env.sh中可以找到更多与NFS相关的设置。要获得NFS调试跟踪,您可以编辑log4j。属性文件以添加以下内容。注意,调试跟踪,特别是对于ONCRPC,可能非常冗长。
更改日志记录级别:
log4j.logger.org.apache.hadoop.hdfs.nfs=DEBUG
获取ONCRPC请求的详细信息:
log4j.logger.org.apache.hadoop.oncrpc=DEBUG
安装HDFS的NFS
启动NFS一共有三个守护进程,分别为 rpcbind(或者 portmap),mountd和nfsd,NFS网关进程同时具有nfsd和mountd。
利用Hadoop自带的包启动potmap
1:停止平台提供的nfs/rpcbind/portmap服务
service nfs stop service rpcbind stop
2:启动包含portmap的包(需要root权限):
hdfs portmap
OR
hadoop-daemon.sh start portmap
3:启动 mountd and nfsd进程.
此命令不需要root特权。在非安全模式下,NFS网关应该由本用户指南开头提到的代理用户启动。在安全模式下,任何用户都可以启动NFS网关,只要用户具有对“NFS .keytab.file”中定义的Kerberos keytab的读访问权。
hdfs nfs3
OR
hadoop-daemon.sh start nfs3
注意:如果hadoop-daemon.sh启动 nfs gateway的话,他的日志可以在hadoop日志里找到
4:停止 NFS gateway 服务
hadoop-daemon.sh stop nfs3
hadoop-daemon.sh stop portmap
利用Linux自己的pormap服务
您还可以选择放弃运行hadoop提供的portmap守护进程,如果将NFS网关作为根启动,则可以在所有操作系统上使用系统portmap守护进程。
这将允许HDFS NFS网关处理前面提到的错误,并且仍然使用系统portmap守护进程注册。要做到这一点,只需像通常那样启动NFS网关守护进程,但要确保作为“根”用户启动,并将“HADOOP_PRIVILEGED_NFS_USER”环境变量设置为非特权用户。
在这种模式下,NFS网关将以root身份启动,以执行其与系统portmap的初始注册,然后在其后和在NFS网关进程的生命周期的剩余时间内,将特权降回到hadoop op_privileged_nfs_user指定的用户。
注意,如果您选择了这条路线,您应该跳过上面的第1步和第2步。
验证NFS相关服务的有效性
1.执行以下命令以验证所有服务是否已启动和运行:
rpcinfo -p $nfs_server_ip
(如果没安装nfs-utils 先安装——安装nfs yum install nfs-utils)
应该会看到如下输出:

2、验证HDFS的namespace是否导出并可以挂载。
showmount -e $nfs_server_ip
应该会看到如下输出:
![]()
3、挂载export “/"
目前,NFS v3只使用TCP作为传输协议。不支持NLM,因此需要挂载选项“nolock”。建议使用硬挂载。这是因为,即使客户机将所有数据发送到NFS网关之后,当NFS客户机内核重新排序写操作时,NFS网关可能会花费一些额外的时间将数据传输到HDFS。
如果必须使用软挂载,用户应该给它一个相对较长的超时(至少不少于主机上的默认超时)。
用户可以挂载HDFS namespace,如下图所示:
mount -t nfs -o vers=3,proto=tcp,nolock,noacl $server:/ $mount_point (需要mount的目录要提前创建如 mkdir /hdfs)
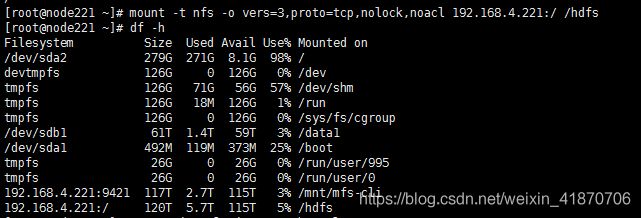
然后用户可以访问HDFS作为本地文件系统的一部分,除了硬链接和随机写还不支持。要优化大文件I/O的性能,可以在挂载期间增加NFS传输大小(rsize和wsize)。默认情况下,NFS网关支持1MB作为最大传输大小。对于更大的数据传输大小,需要更新“nfs.rtmax”和“nfs.rtmax"在hdfs-site.xml 。
总结:
在最后一步挂载的时候,mount.nfs mount system call failed报错,没有挂载成功,然后我在core-site.xml里添加了如下配置。
然后重启集群,第二遍挂载成功。
但是测试写盘速度,非常非常慢。