Python学习笔记14:爬取51job数据,并写入excel中
因为工作需要,有时候需要了解行业公司的岗位信息和要求。
以往都是通过人工查找的方式,去选取部分公司,并复制粘贴到 excel 中,作为一些材料的参考。
了解了 Python 后,这项工作肯定要让 Python 来做了。
本着“从小到大”编写程序功能的思路,我写了3个模块:
1、excel 操作模块:负责创建 excel 文档,以及把数据写入 excel 文档
2、单页面获取数据模块:负责获取页面中岗位名称,薪资,就业信息等数据,并返回数据 list
3、综合模块:遍历搜索的结果页,获取页码的网址,并获取每个网址中公司的工作信息网址。基于这些网址,挨个获取数据,并存入 excel 文件。
1. excel 操作模块代码:
excelOp.py 用到了 openpyxl 模块,利用它来操作 excel。
# -*- coding:utf-8 -*-
import openpyxl
from openpyxl.styles import Border,Side,PatternFill,Font,Alignment
# 头部内容数据
dataHeader = ["公司名称", "岗位名称", "经验要求", "月薪", "工作要求", "省市", "工作地点","网址"]
# 头部表格宽度数据
headerWidth = {
"A": 20,
"B": 20,
"C": 15,
"D": 20,
"E": 50,
"F": 15,
"G": 15,
"h": 20
}
# 头部字体数据
headerFont = Font('宋体', size=12, bold=True, italic=False, strike=False, color='000000')
# 表格边框样式
border = Border(left=Side(border_style='thin', color='000000'),
right=Side(border_style='thin', color='000000'),
top=Side(border_style='thin', color='000000'),
bottom=Side(border_style='thin', color='000000'))
# 表格头部颜色
headerFill = PatternFill(fill_type="solid", start_color='dddddd', end_color='dddddd')
# 表格对齐方式
headerAlign = Alignment(horizontal="center", vertical="center", wrap_text=False)
contentAlign = Alignment(horizontal="center", vertical="center", wrap_text=True)
def initExcel(excelName):
'''
初始化excel文件,生成表格头部
:param excelName: 生成 excel 文件的名字
:return:
'''
# 实例化
wb = openpyxl.Workbook()
# 创建一个表
# ws = wb.create_sheet("51job工作统计")
ws = wb.active # 激活默认表
ws.title = excelName # 更改默认表的名字
# 生成表格头部
for index, value in enumerate(dataHeader):
headerCell = ws.cell(row=1, column=index + 1)
headerCell.value = value
# 设置单元格样式:边框,填充色,字体,对齐方式
headerCell.border = border
headerCell.fill = headerFill
headerCell.font = headerFont
headerCell.alignment = headerAlign
# 控制表格头部宽度
ws.row_dimensions[1].height = 30
for item in headerWidth:
ws.column_dimensions[item].width = headerWidth[item]
wb.save( excelName+".xlsx")
def insertData(wb,dataList,rowNum):
'''
把输入插入到 excel 文件中
:param wb: excel对象
:param dataList: 数据
:param rowNum: 要插入的第几行。
:return:
'''
ws = wb[ wb.sheetnames[0] ] # 获取第一个sheet。excel 文件中就这么一个表
# 插入数据
for i,item in enumerate(dataList) :
c = ws.cell(row=rowNum, column=i+1, value=item)
# 设置单元格样式:边框,文字对齐方式
c.border = border
c.alignment = contentAlign2. 单页面获取数据模块
singlepage.py 主要利用 requests 模块,请求对应页面的相关内容。
再利用 BS4 模块或者 正则表达式,选出对应的内容。
# -*- coding:utf-8 -*-
import os,requests,re
import random
from urllib.parse import quote
from bs4 import BeautifulSoup # 解析 HTML 的模块 导入 BS ,版本 4。
import lxml # bs4的解析插件模块
def handlePageData(weburl,header):
'''
处理页面信息, 返回页面相关数据
:param weburl: 请求的网址
:param header: 请求的头信息,随机抽取的一个
:return : 返回页面相关数据 list
'''
tagURL = re.sub(r'\\',"",weburl)
req = requests.get(url=tagURL, headers=header)
req.encoding = req.apparent_encoding
webHTML = req.text
bs = BeautifulSoup(webHTML, "lxml")
# 公司名称
try:
companyName = bs.select(".tHjob .cname .catn")[0].get_text().strip()
except:
companyName = "某公司"
# 岗位名称
try:
jobTiltle = bs.select(".tHjob h1")[0].get_text().strip()
except:
jobTiltle = "暂无"
# 岗位待遇
try:
jobMoney = bs.select(".tHjob .cn strong")[0].get_text().strip()
except:
jobMoney = "面谈"
else:
jobMoney = re.findall('(.*?)/月', jobMoney, re.I | re.DOTALL)
if not jobMoney: # 如果 jobMoney 为空,说明没有找到。
jobMoney = "面谈"
else:
jobMoney = jobMoney[0]
# 岗位详细信息
try:
jobMsg = str(bs.select(".job_msg")[0]).strip()
except:
jobMsg = "暂无"
else:
reg = '(.*?)'
# 信息
jobMsg = re.findall(reg, jobMsg, re.I | re.DOTALL)[0].strip().split("
")
jobMsg = "\n".join(jobMsg)
jobMsg = BeautifulSoup(jobMsg, "lxml").get_text()
# 岗位经验和地址
try:
jobAddrInfo = bs.select("p.ltype")[0].get_text().strip()
except:
jobAddrInfo = "暂无"
# 岗位经验
jyReg = r'\|\xa0\xa0(.*?)经验'
try:
jobExp = re.findall(jyReg, jobAddrInfo, re.I | re.DOTALL)[0].strip()
except:
jobExp = "0"
else:
# 去掉年
jobExp = re.findall('(.*?)年', jobExp, re.I | re.DOTALL)
if not jobExp: # 如果 jobExp 为空,说明没有找到。值为“无需”经验
jobExp = "0"
else:
jobExp = jobExp[0]+"年"
# 公司地址
addReg = r'^(.*?)\xa0\xa0\|'
try:
jobAddr = re.findall(addReg, jobAddrInfo.strip(), re.I | re.DOTALL)[0]
except:
jobAddr = "暂无"
# 上班地址
comAddrReg = r'上班地址:(.*?)'
companyAddr = re.findall(comAddrReg, webHTML, re.I | re.DOTALL)
if not companyAddr:
companyAddr = "上班地址暂无"
else:
companyAddr = companyAddr[0]
# 返回页面相关数据
return [
companyName, # 公司名
jobTiltle, # 岗位名
jobExp, # 工作经验
jobMoney,
jobMsg,
jobAddr,
companyAddr,
tagURL # 网址
]
3. 整合主模块
请求搜索结果的第一页,通过翻页代码,找出所有的页面。
挨个把每个页面的相关公司页面记录下来,并依次遍历,搜索数据,最后存入 excel。
这里几个细节:
(1)数据是最后统一写入的。防止数据量大,写入excel数据操作过于频繁。
(2)请求的 headers 放入了一个 list 中,每次请求页面的时候,随机选择一个,简单的防止下网站的 反爬机制。
(3)要请求的岗位是手动输入,利用 urllib 转为 url 地址码后,再拼凑为请求的地址。
# -*- coding:utf-8 -*-
import os,requests,re
import random
from urllib.parse import quote
from bs4 import BeautifulSoup # 解析 HTML 的模块 导入 BS ,版本 4。
import lxml # bs4的解析插件模块
# excel 操作模块
import openpyxl
from openpyxl.styles import Border,Side,PatternFill,Font,Alignment
import singlepage, excelOp
# 设置headers 为了防止反扒,设置多个headers
# chrome,firefox,Edge
headers = [
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive'
},
{
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive'
},
{
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19041',
'Accept-Language': 'zh-CN',
'Connection': 'keep-alive'
}
]
inputTag = None # 搜索的工作职位
def getURL(inputTag,page=1):
"""
:param page: 页码
:return: 返回组合后的网址
"""
# 组合为目标地址
weburl = r"https://search.51job.com/list/060000,000000,0000,00,9,99,{tag},2,{page}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(
tag=quote(inputTag), page=page)
return weburl
def getWebHTML(weburl):
"""
获取指定页面的HTML
"""
req = requests.get( url=weburl,headers=random.choice(headers) )
req.encoding = req.apparent_encoding # 防止中文乱码
webHTML = req.text
print( "页面HTML获取成功!"+ weburl )
return webHTML
def getTotalPage(webHTML):
"""
获取翻页里的页面
"""
pageList = [] # 搜索出来的页面(数据来自页码)
reg = '"total_page":"(.*?)"'
totalPage = re.findall(reg, webHTML ,re.DOTALL|re.I)[0]
print("获取总的页码数:"+totalPage )
for i in range(1,int(totalPage)+1): # 把翻页中的页码,添加到 全局变量pageList 中
pageList.append( getURL(inputTag, i) )
# print(getURL(inputTag, i))
return pageList
def getAllCompanyPage( pageList ):
"""
:param pageList: 翻页里的页面 list
:return: 所有公司的招聘信息网址
"""
companyList = []
reg = '"job_href":"(.*?)"'
for pageItem in pageList:
pageHTML = getWebHTML(pageItem)
company = re.findall( reg, pageHTML , re.I)
companyList = companyList + company
print("搜索出相关公司:"+ str( len(companyList) ) + "个")
return companyList
def main():
"""
主函数
"""
global inputTag
inputTag = input("请输入要爬取的工作岗位:")
weburl = getURL(inputTag,1) # 获得目标地址。默认第一页
webHTML = getWebHTML(weburl) # 获取HTML
pageList = getTotalPage(webHTML) # 获取翻页里的页面
companyList = getAllCompanyPage( pageList ) # 所有公司的招聘信息网址
# 处理公司的单独页面,获取相关信息,并保存在 excel 文件中。
# 初始化表格
excelOp.initExcel(inputTag)
wb = openpyxl.load_workbook(inputTag+".xlsx")
# 处理所有公司页面信息
for i,item in enumerate(companyList):
# 获取每个页面的数据信息
# print( item )
singleInfo = singlepage.handlePageData(item, random.choice(headers) )
# 把这些数据插入到excel 表格中
excelOp.insertData(wb,singleInfo, i+2)
print(singleInfo[0]," 的数据获取成功")
wb.save(inputTag+".xlsx")
os.rename(inputTag+".xlsx", inputTag+"_"+str(len(companyList))+".xlsx")
if __name__ == '__main__':
main()
小结
虽然实现了功能,解放了手工操作,方便了工作。但是个人觉得代码还是写的比较粗糙,感觉还需要改进。
中途也遇到了几个坑,这里记录下
(1)循环 list
for-in 循环,只能得到 list 的元素,要得到索引,应该:
for i,item in enumerate(companyList):
print(i,item) # 索引,数据项
(2)有可能数据获取失败
有时候面临页面中找不到数据,一定要用 try 语句,给出容错方案。
try:
jobTiltle = bs.select(".tHjob h1")[0].get_text().strip()
except:
jobTiltle = "暂无" # 没有获取到数据
else:
.... # 正常获取数据的处理
Python 的道路还很长,要继续努力~!
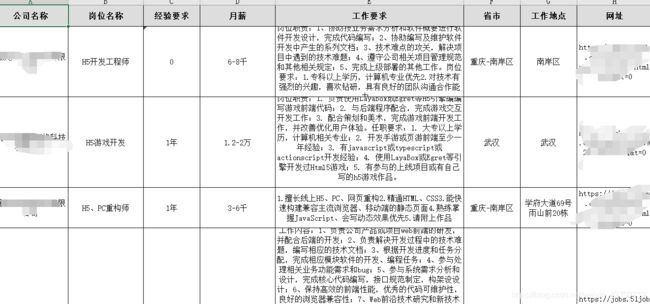
附上结果的图: