分布式追踪不是银弹 | 正确使用分布式追踪和 APM 系统


2010-2020,十年间,应用系统的服务化和容器化程度越来越高,云原生技术也得到了更为广泛的运用,应用系统对于扩容和管理的需求逐步地提升,虽然大家也在反省微服务的拆分粒度,但是走向分布式的趋势,依然是不变的。在这样的背景下,服务的依赖越来越复杂,如何监控服务的性能、诊断性能故障的需求也越来越急迫,再加上传统日志手段不能很好的满足分布式系统的问题诊断场景,所以分布式追踪和基于分布式追踪的APM,也越来越受到重视。
2010 Google Dapper
分布式追踪这个概念,始于2010年Google的Dapper论文。
Dapper论文链接:https://research.google/pubs/pub36356/
2012年,Twitter开源了Zipkin,同年,Naver开源了Pinpoint。2015年SkyWalking做为个人项目开源,2017年加入Apache孵化器,2019年毕业成为顶级项目。对于Dapper论文,希望大家清楚,Dapper系统从来没有被真正使用在Google搜索引擎和其他核心业务上,而是作为实验性和研究性课题提出和实践的。Google内部有针对Dapper论文思路的后续、其他改进和实践。所以Dapper论文中的介绍,更多的是启蒙和入门,而非真正的技术指导。
下面两张图是Dapper论文中描述的用序号来表示分布式调用关系的示例。Span Id和Parent Span Id在描述上下游应用的调用关系。

1、为什么SkyWalking和传统分布式追踪系统不同?
下面三张图是SkyWalking两种展现trace模型的方式,SkyWalking UI中一共有三种展现trace的典型视图,分别运用于不同的场景。后面我们会更详细的介绍。
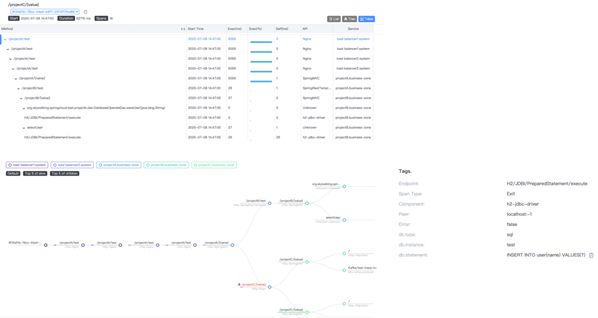
(1)RPCTracing
在分布式追踪过程中,为了保证上下文的传递,需要在HTTP头中加入header。如果大家熟悉zipkin,会发现这里的Header远比Zipkin的b3协议要复杂。SkyWalking使用更复杂的头协议,提供更为强大的探针感性能力和后端分析能力,以及SkyWalking特有的分布式拓扑分析方法STAM也依赖于更复杂的header设计(论文可参见:https://wu-sheng.github.io/STAM/)。

(2)MQ Tracing
在MQ的追踪场景中,也使用了类似的技术手段,需要加入header。不同的是,在消费端,因为MQ可以一次消费多条消息,可以构建一个segment reference一对多的关系。

分布式追踪的过程中的头信息的加入,是保证上下文传播,以及形成trace的关键步骤。
分布式追踪的两面性
我们回到利用Trace来定位问题,下面是我们常见的几种可以通过trace快速定位的典型场景。
发生程序错误,可能是RPC的错误码,或者异常堆栈等。Trace可以定位并显示调用流程。

发现慢调用,方便问题边界的定义。

Access Overload,虽然每个节点都执行很快,但是子调用过多,造成整体业务执行缓慢。这种典型场景一般对应高频的数据库和缓存的访问上。

分布式调用深度太深,是SkyWalking提供Tree视图的主要原因。当横向宽度展现出的深度太大时,应用性能会因为跨越层级太深,特别是RPC的次数太多,造成性能缓慢。

Trace在定位能力上展现了强大的实力,同时性能消耗也是实实在在的。即使SkyWalking提供了业界最好的性能,但在单进程内,20个span还是有明显的性能消耗。如果用户持续的增加span数量,势必对整个系统造成更大且不可承受的压力。后面我们也会提到,如何使用更合理的方法,而非盲目的增加span数量。

那么分布式追踪的典型优点和缺点有哪些呢?
优点
有效的移除分布式造成的信息缺失,如RPC故障、路由以及熔断情况、分布式访问参数
重新加强日志的能力,trace和log可以集成使用
缺点
探针的额外负载
后端数据分析和存储的资源消耗
数据失效周期造成的数据量问题
2、如何才能正确的定位问题
那么trace是否只是一个有上下文的日志呢?如何才能准确的定位问题呢?
我们首先要了解监控数据处理上,要经过明细数据、排序、聚合、以及可视化这几个阶段。
拓扑图的价值
那么在APM提供的数据中,最受大家喜欢的一定是拓扑图。

拓扑图帮助团队理解系统的实际部署情况,发现理论架构和实际架构之间的异同。让架构师的架构设计不再停留在文档中。同时,公司各级领导团队可以通过拓扑图,更直观地理解分布式系统的高复杂性。同时拓扑图也为后续的指标查看提供了重要的下钻点,只要有了拓扑图,才更容易找到上下游服务的关系。
监控的起点,metrics和告警
拓扑图虽然信息丰富,但是过多的点和线,使得运维团队不能快速发现问题。所以监控的起点,实际是指标数据和告警。SkyWalking提供服务、实例、Endpint,数据库、服务管理、实例关系和Endpoint关系等多个维度的指标,以及基于这些指标的告警规则配置。通过合理的设置SLO,避免无效告警和告警风暴,使得运维团队能够真正被告警信息驱动。而不应该基于trace这样的明细数据,或者简单的使用出错来触发告警。
下钻检查 – 实例 or Endpoint
同时,发现服务告警问题后,可以从实例和Endpoint两个维度查看,是一个服务下的不同实例性能不一致,还是个别的服务(endpoint)性能出现故障,从而来定义系统的异常范围。
下钻检查 – 分布式依赖维度
而有一些错误是发生在特定的依赖关系之间的,那么拓扑的服务关系指标,可以展现有关系的服务间,实际上两个服务间的客户端和服务端性能检测情况,来判断是提供方性能问题、网络问题、还是客户端问题等。

下钻检查 – 实例级别依赖故障(限流、网络)
更深入的,我们可以通过实例关系性能,发现进程间的点对点性能问题。

业务服务上下游依赖
如果性能问题出现在特定业务流、业务方法中,我们还可以通过业务服务(endpoint)的上下游依赖,来发现endpoint之间的依赖关系,以及调用频次、性能指标等等。

Apdex评分体系,也应该被更广泛的应用。Apdex的计算模型,不针对简单的错误率或者响应时间,而是把使用方的感受做为衡量标准。针对满意的响应时间给出阈值,并使用如下的公式,可以计算出实际的Apdex得分。

通过Apdex可以标识出服务、服务关系的健康程度,为后续的服务降级、限流、扩容,提供重要的指导意见。更详细的资料可以参考SkyWalking的官方Blog,会有更详细的介绍。
http://skywalking.apache.org/blog/2020-07-26-apdex-and-skywalking.html
3、那么如果上述方法都失效了呢?
我们可以使用基于线程快照的方法,由于上述的所有手段,也许还未定位到实际的方法缓慢的原因,但是范围是清晰的,如所属的服务、Endpoint、执行的不合理时长(如P95时长),那么我们可以设置性能剖析,专门针对这样的请求进行性能剖析。
性能剖析是针对连续时间dump出的线程方法栈,如果出现相同的元素(包括栈深和父级节点都相同),则估算次方法执行时间,为两次dump的间隔时间。
非APM提供的剖析工具,往往进行全局剖析,而性能消耗巨大,SkyWalking和数据指标以及trace相结合,只在必要时,小范围、小并发地进行性能剖析,所以消费小且可控。适用于生产环境。在功能刚刚提供出来时,社区用户就反馈成功在线上定位出问题。
此方法对偶发性的慢方法,以及锁问题的探查,是最有帮助的。
最后,SkyWalking设计有针对多语言,多场景的开源项目,欢迎大家使用和参与项目贡献。
本文整理自吴晟直播内容
吴晟,Apache软件基金会会员,Apache SkyWalking的创始人,项目VP,也是Apache ShardingSphere的联合创始人和PMC成员。同时,做为Apache 孵化器PMC和Apache APISIX PMC的成员,以及Apache ECharts(incubating)和DolphinScheduler(incubating)孵化器导师。以及阿里云MVP,微软MVP,腾讯云TVP。著有《Apache SkyWalking实战》。

点击链接了解详情并购买

更多精彩回顾
书讯 |华章计算机拍了拍你,并送来了8月书单(下)
书讯 | 华章计算机拍了拍你,并送来了8月书单(上)
上新 | 首本深入讲解Linux内核观测技术BPF的书上市!
书单 | 《天才引导的历程》| 西安交通大学送给准大一新生的礼物
干货 | 机器人干活,我坐一边喝茶——聊聊最近爆火的RPA
收藏 | 揭秘阿里巴巴的客群画像
 点击阅读全文购买
点击阅读全文购买