Annotation Processor: 自定义注解处理器,不再写烦人的模板代码
注解处理在 Java 1.5 的时候就已经发布了,虽然它很老了,但是却是最强大的 API 之一。下面我们会先讨论注解处理,代码自动生成以及使用到这些技术的开源库。
什么是注解
实际上,我们应该都知道什么是注解。我们经常使用到的:@Override,@Singleton,@StringRes 等等,这些就是注解。
注解是一种可以添加到Java源代码的语法元数据。 我们可以注释类,接口,方法,变量,参数等。 可以从源文件中读取Java注解。 Java注解也可以嵌入和读取编译器生成的类文件。 Java VM可以在运行时保留注解,并通过反射进行读取。
比如:
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.FIELD)
public @interface BindView {
int value();
}
创建一个注解需要两部分信息: Retention 和 Target 。
RetentionPolicy 指定了注解应该保留到程序生命周期的什么时候。举个例子:注解可以保留到程序的编译时期或者运行时期。
ElementTypes 指定了注解应该作用于程序的哪一个部分。有3个取值:
- SOURCE —— 编译时期,不会储存
- CLASS —— 储存在 class 文件中,但是不会保留到运行时期
- RUNTIME —— 储存在 class 文件中,运行时期可以访问(通过反射)
拿 BindView 注解来说,RetentionPolicy.SOURCE 表示注解只需要在编译时期保存,之后就不需要了。ElementType.FIELD 表示该注解只能修饰字段。
注解处理器介绍
编译时期
Annotation Processor 实际上是 javac 编译器的一部分,所以注解处理时发生在编译时期,这有许多好处,其中之一就是“在编译其实发生错误比运行时期发生错误要好的多”。
无反射
Java 的反射 API 会在运行时抛出许多错误,这实在是有点蛋疼。但是 Annotation Processor 就不一样了,它会直接给我们一个程序的语义结构,我们使用这个语义结构就可以分析注解所处的上下文场景,然后做处理。
生成样板代码
Annotation Processor 最大的用处就是用来生成样板代码了,比如著名的 ButterKnife 等开源库。
注意:注解处理器只能生成新的文件,无法更改已经存在的文件。
注解处理器是如何工作的
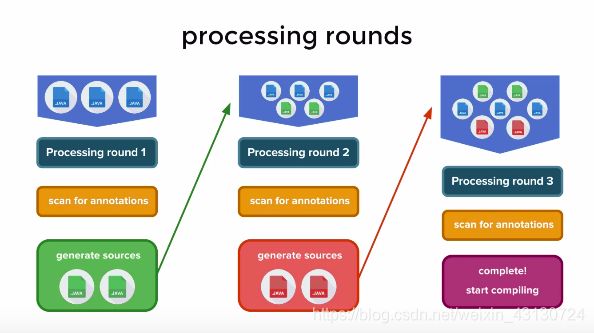
注解处理会执行很多轮。编译器首先会读取java源文件,然后查看文件中是否有使用注解,如果有使用,则调用其对应的注释处理器,这个注解处理器(可能会)生成新的带有注解的java源文件。这些新注解将再次调用其相应的注释处理器,然后再次生成更多的java源文件。就这样一直循环,直到没有新的文件生成。
注册注解处理器
java 编译器需要知道所有的注解处理器,所以如果我们想要自定义一个处理器,我们必须要让 java 编译器知道我们创建了一个。
有两种方法来注册一个处理器:
-
老方法:
创建一个目录:
<your-annotation-processor-module>/src/main/resources/META-INF/services然后在services文件夹里面,创建一个名字叫做
javax.annotation.processing.Processor的文件。在这个文件中声明你的处理器的权限定名:<your-package>.YourProcessor -
新方法:
使用谷歌的 AutoService 库。
package foo.bar; import javax.annotation.processing.Processor; @AutoService(Processor.class) final class MyProcessor implements Processor { // … }注意在 gradle 文件中引入依赖。
创建一个注解处理器
首先,我们需要继承一个父类:
public class Processor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
// initialize helper/utility classes...
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnvironment) {
// do processing...
return true;
}
@Override
public Set<String> getSupportedAnnotationTypes() {
//
}
@Override
public SourceVersion getSupportedSourceVersion() {
//
}
}
init() 提供帮助和工具类,如:Filer(生成文件),Messager(用于记录错误,警告等),Elements(用于操作程序元素的工具方法),类型(用于操作类型的工具方法)等。 我们可以使用processingEnvironment 这个变量来获取这些类。
process() 这个方法就是所有处理器处理注解的地方。这里你可以获取到被注解修饰的元素的所有信息。然后你就可以生成新的文件了。
getSupportedAnnotationTypes() 这里返回自定义的注解就好了。它的返回值是 process() 方法的第一个参数。
getSupportedSourceVersion() 返回最新的 java 版本就好了。
新建两个module
一个用于创建注解,一个用于创建注解处理器。
为啥需要新建两个module呢?
因为 processor 需要 annatation 的引用,所以 annotation 需要提出来作为一个 module。
那么可不可以将所有代码都放到 app 里面呢?是可以的,但是由于我们不需要 processor 的代码,只需要它在编译的时候处理我们的代码然后生成新的文件就好了,更不就不需要将 processor 的代码打包到 apk 里面,所以新建 module 是最好的选择。

piri-pricessor 的 build.gradle 需要配置一下:
implementation project(':piri-annatation')
app 的 build.gradle 需要配置一下:
implementation project(':piri-annatation')
annotationProcessor project(':piri-processor')
创建注解
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.TYPE)
public @interface NewIntent {
}
ElementType.TYPE 表示这个注解可以修饰 类,接口,枚举 等等。
创建注解处理器
自定义的注解处理器需要继承至一个指定的父类(AbstractProcessor):
public class NewIntentProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnv) {}
@Override
public Set<String> getSupportedAnnotationTypes() {}
@Override
public SourceVersion getSupportedSourceVersion() {}
}
开始处理注解
首先找到所有的被指定注解修饰元素
for (Element element : roundEnvironment.getElementsAnnotatedWith(NewIntent.class)) {
if (element.getKind() != ElementKind.CLASS) {
messager.printMessage(Diagnostic.Kind.ERROR, "Can be applied to class.");
return true;
}
TypeElement typeElement = (TypeElement) element;
activitiesWithPackage.put(
typeElement.getSimpleName().toString(),
elements.getPackageOf(typeElement).getQualifiedName().toString());
}
我们利用 roundEnvironment.getElementsAnnotatedWith() 这个方法就可以找出所以被指定注解修饰的元素,这个方法返回了一个集合,集合类型是 Element,Element 是所有元素的一个父接口。
然后我们判断一下,注解是否被正确使用了,因为我们在创建注解的时候就指定了该注解只能修饰类,接口,枚举…
如果注解被错误使用了,我们可以使用 message 打印错误信息,反之,被正确使用了,那么我们就可以将它强制转换为 TypeElement。关于这个 TypeElement ,它是 Element 的一个子接口。它通常可以用于类和方法参数。还有一些其他类型的元素:
package com.example; // PackageElement
public class Foo { // TypeElement
private int a; // VariableElement
private Foo other; // VariableElement
public Foo () {} // ExecuteableElement
public void setA ( // ExecuteableElement
int newA // TypeElement
) {}
}
之所以要强制转换成 TypeElement,是因为转换之后,我们可以获取到更多的信息。
生成代码
TypeSpec.Builder navigatorClass = TypeSpec
.classBuilder("Navigator")
.addModifiers(Modifier.PUBLIC, Modifier.FINAL);
for (Map.Entry<String, String> element : activitiesWithPackage.entrySet()) {
String activityName = element.getKey();
String packageName = element.getValue();
ClassName activityClass = ClassName.get(packageName, activityName);
MethodSpec intentMethod = MethodSpec
.methodBuilder(METHOD_PREFIX + activityName)
.addModifiers(Modifier.PUBLIC, Modifier.STATIC)
.returns(classIntent)
.addParameter(classContext, "context")
.addStatement("return new $T($L, $L)", classIntent, "context", activityClass + ".class")
.build();
navigatorClass.addMethod(intentMethod);
}
这个是 JavaPoet 的使用方法,就不多说了,可以查看 文档 。
最后,将代码写入文件
JavaFile.builder("com.annotationsample", navigatorClass.build())
.build()
.writeTo(filer);
生成的文件大概内容如下:
public final class Navigator {
public static Intent startMainActivity(Context context) {
return new Intent(context, com.annotationsample.MainActivity.class);
}
}
然后,我们就可以在代码中使用生成的代码了:
@NewIntent
public class MainActivity extends AppCompatActivity {}
----------------------------------------------------------------------------------------
public class SplashActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_splash);
Navigator.startMainActivity(this); //generated class, method
}
}
实例工程
AnnotationProcessorDemo
遇到的坑:
- 新建module的时候要选择 java module,否则找不到 AbstractProcessor 类
- 我的 AS 一直保持着最新的 gradle 版本,在我写示例项目的时候,是引用的 gradle 版本是
https\://services.gradle.org/distributions/gradle-5.1.1-all.zip,于是我就踩了一个深坑,那就是发现 processor 工程打包除了问题,导致 app 项目引用了无法生成文件。找了一个下午的问题最后发现是 gradle 版本的问题,改成https\://services.gradle.org/distributions/gradle-4.6-all.zip就好了。我特么想骂人。
上面的版本问题,已经找到答案,添加一行代码即可:
annotationProcessor 'com.google.auto.service:auto-service:1.0-rc5'
我当时看别人的博客的时候,就很奇怪,为啥不用加 annotationProcessor。
倒推一下 ButterKnife 是怎么做的
首先我们先来回忆一下我们是怎么使用 ButterKnife 的。
给控件加上注解:
@BindView(R.id.title)
TextView title;
在 Activity 的 setContentView 后,添加代码:
ButterKnife.bind(this);
经过这两步,title 就会被自动赋值,然后我们就可以使用了。
这里我们可以猜想一下,ButterKnife 的注解处理器做了什么。
第一步,肯定也是先要获取到被注解修饰的元素。然后接下来该做什么呢?我们转换一下思维,如果我们没有使用 ButterKnife 的话,我们会做什么——我们会在 setContentView 方法后面写一个 initView 方法,然后给变量赋值。这个时候你就应该反应过来了,ButterKnife.bind(this); 这句代码就做了类似的功能。那么它是如何实现的呢?
我们从这行代码中可以看出,ButterKnife 会持有当前 Activity 的引用,那么我们可不可以利用这个引用,拿到 title 呢?答案是可以的,因为 title 不是私有的,所以我们只需要生成一个类,将这个类放入当前 Activity 所在的 package 中即可。
由于注解的参数就是这个控件的 id,所以我们也可以找到这个控件,调用 findViewById,将这个值赋值给 title。大概是这样:
自动生成的代码 xxx
activity.title = Utils.findViewById(root, id);
这样就完成了赋值。当然实际不可能这么简单,还有很多细节需要处理,这里只是一个倒推,具体的细节还请执行查阅源代码。
后记
文章中已经说过,Annotaion Processor 只能生成新的文件,无法对已有的文件进行修改。如果我们有这方便的需求,那么应该怎么做呢?比如,我们想给某些类(比如Activity 或者 Fragement )添加 log,手动添加的话,就很蛋疼了,这个时候,如果可以批量处理的话就会轻松很多。那么有什么可以办到呢,就是 Transform API 了,下一篇就写这个东西。