矩阵论笔记:雅可比矩阵(Jacobian)和海森矩阵(Hessian)
| 雅可比矩阵(Jacobian)和海森矩阵(Hessian) |
文章目录
- 一、 Jacobian
- 二、雅可比矩阵
- 2.1、雅可比行列式
- 三、 海森Hessian矩阵
- 3.1、海森矩阵的正定与函数凹凸性的关系
- 3.2、海森矩阵在牛顿法中的应用
- 3.2.1、 泰勒公式
- 3.2.2、 求解方程
- 3.2.3、 最优化
一、 Jacobian
在向量分析中, 雅可比矩阵是一阶偏导数以一定方式排列成的矩阵, 其行列式称为雅可比行列式. 还有, 在代数几何中, 代数曲线的雅可比量表示雅可比簇:伴随该曲线的一个代数群, 曲线可以嵌入其中. 它们全部都以数学家卡尔·雅可比(Carl Jacob, 1804年10月4日-1851年2月18日)命名;英文雅可比量”Jacobian”可以发音为[ja ˈko bi ən]或者[ʤə ˈko bi ən].
二、雅可比矩阵
雅可比矩阵的重要性在于它体现了一个可微方程与给出点的最优线性逼近. 因此, 雅可比矩阵类似于多元函数的导数.
假设: F : R n → R m F : R_{n} \rightarrow R_{m} F:Rn→Rm:是一个从欧式 n n n 维空间转换到欧式 m m m 维空间的函数.这个函数由 m m m个实函数组成: y 1 ( x 1 , … , x n ) , … , y m ( x 1 , … , x n ) \mathrm{y_{1}}(\mathrm{x_{1}} , \ldots, \mathrm{x_{n}}), \ldots, \mathrm{y_{m}}(\mathrm{x_{1}} , \ldots, \mathrm{x_{n}}) y1(x1,…,xn),…,ym(x1,…,xn);这些函数的偏导数(如果存在)可以组成一个 m m m行 n n n列的矩阵, 这就是所谓的雅可比矩阵:
[ ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ] \left[ \begin{array}{ccc}{\frac{\partial y_{1}}{\partial x_{1}}} & {\cdots} & {\frac{\partial y_{1}}{\partial x_{n}}} \\\\ {\vdots} & {\ddots} & {\vdots} \\\\ {\frac{\partial y_{m}}{\partial x_{1}}} & {\cdots} & {\frac{\partial y_{m}}{\partial x_{n}}}\end{array}\right] ⎣⎢⎢⎢⎢⎢⎡∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎦⎥⎥⎥⎥⎥⎤
此矩阵表示为: J F ( x 1 , … , x n ) J_{F}\left(x_{1}, \ldots, x_{n}\right) JF(x1,…,xn)或者 ∂ ( y 1 , … , y m ) ∂ ( x 1 , … , x n ) \frac{\partial\left(y_{1}, \ldots, y_{m}\right)}{\partial\left(x_{1}, \ldots, x_{n}\right)} ∂(x1,…,xn)∂(y1,…,ym)
这个矩阵的第 i i i行是由梯度函数的转置 y i ( i = 1 , … , m ) yi(i=1,…,m) yi(i=1,…,m)表示的.
如果 p p p是 R n R_{n} Rn中的一点, F F F在 p p p点可微分, 那么在这一点的导数由 J F ( p ) J_{F}(\mathbf{p}) JF(p)给出(这是求该点导数最简便的方法). 在此情况下, 由 F ( p ) F(\mathbf{p}) F(p)描述的线性算子即接近点 p p p的 F F F的最优线性逼近, x x x逼近于 p p p:
F ( x ) ≈ F ( p ) + J F ( p ) ⋅ ( x − p ) F(\mathbf{x}) \approx F(\mathbf{p})+J_{F}(\mathbf{p}) \cdot(\mathbf{x}-\mathbf{p}) F(x)≈F(p)+JF(p)⋅(x−p)
2.1、雅可比行列式
如果 m = n m = n m=n, 那么 F F F是从 n n n维空间到 n n n维空间的函数, 且它的雅可比矩阵是一个方块矩阵. 于是我们可以取它的行列式, 称为雅可比行列式。
在某个给定点的雅可比行列式提供了 在接近该点时的表现的重要信息.
- 例如, 如果连续可微函数 F F F在 p p p点的雅可比行列式不是零, 那么它在该点附近具有反函数. 这称为反函数定理.
- 更进一步, 如果 p p p点的雅可比行列式是正数, 则 F F F在 p p p点的取向不变;
- 如果是负数, 则 F F F的取向相反. 而从雅可比行列式的绝对值, 就可以知道函数 F F F在 p p p点的缩放因子;
这就是为什么它出现在换元积分法中.
- 1.举例理解:对于取向问题可以这么理解, 例如一个物体在平面上匀速运动, 如果施加一个正方向的力F, 即取向相同, 则加速运动, 类比于速度的导数加速度为正;如果施加一个反方向的力F, 即取向相反, 则减速运动, 类比于速度的导数加速度为负.
三、 海森Hessian矩阵
在数学中, 海森矩阵(Hessian matrix或Hessian)是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵, 此函数如下:
f ( x 1 , x 2 … , x n ) f\left(x_{1}, x_{2} \ldots, x_{n}\right) f(x1,x2…,xn)
如果 f f f的所有二阶导数都存在, 那么 f f f的海森矩阵即:
H ( f ) i j ( x ) = D i D j f ( x ) H(f)_{i j}(x)=D_{i} D_{j} f(x) H(f)ij(x)=DiDjf(x)
其中 x = ( x 1 , x 2 … , x n ) x=\left(x_{1}, x_{2} \dots, x_{n}\right) x=(x1,x2…,xn), 即 H ( f ) H(f) H(f)为:
[ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] \left[ \begin{array}{cccc}{\frac{\partial^{2} f}{\partial x_{1}^{2}}} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{n}}} \\ \\{\frac{\partial^{2} f}{\partial x_{2} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{2}^{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{2} \partial x_{n}}} \\\\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\\\ {\frac{\partial^{2} f}{\partial x_{n} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{n} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{n}^{2}}}\end{array}\right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
(也有人把海森定义为以上矩阵的行列式)海森矩阵被应用于牛顿法解决的大规模优化问题.)
3.1、海森矩阵的正定与函数凹凸性的关系
Hessian矩阵的正定性在判断优化算法可行性时非常有用,简单地说,海森矩阵正定,则:
- 函数的二阶偏导数恒大于0
- 函数的变化率(斜率)即一阶导数始终处于递增状态
- 函数为凸
因此,在诸如牛顿法等梯度方法中,使用黑塞矩阵的正定性可以非常便捷的判断函数是否有凸性,也就是是否可收敛到局部/全局的最优解
注意:正定性的判定方法有很多重,其中最方便也是常用的一种为:
- 若所有特征值均不小于零,则称为半正定。
- 若所有特征值均大于零,则称为正定。详细的判断方法可以参考我的博客:奇异值分解SVD
- 多元函数Hessian矩阵半正定就相当于一元函数二阶导非负;多元函数为凸函数的充要条件为其二阶Hessian矩阵半正定
3.2、海森矩阵在牛顿法中的应用
一般来说, 牛顿法主要应用在两个方面,
- 1, 求方程的根;
- 2, 最优化;
3.2.1、 泰勒公式
泰勒公式是将一个在 x = x 0 x=x_{0} x=x0处具有n阶导数的函数 f ( x ) f(x) f(x)利用关于 ( x − x 0 ) (x-x_{0}) (x−x0)的 n n n次多项式来逼近函数的方法。
- 若函数 f ( x ) f(x) f(x)在包含 x 0 x_{0} x0的某个闭区间 [ a , b ] [a,b] [a,b]上具有 n n n阶导数,且在开区间 ( a , b ) (a,b) (a,b)上具有 ( n + 1 ) (n+1) (n+1)阶导数,则对闭区间 [ a , b ] [a,b] [a,b]上任意一点 x x x,成立下式:
f ( x ) = f ( x 0 ) 0 ! + f ′ ( x 0 ) 1 ! ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + … + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + R n ( x ) f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+R_{n}(x) f(x)=0!f(x0)+1!f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+…+n!f(n)(x0)(x−x0)n+Rn(x) - 其中: f ( n ) ( x ) f^{(n)}(x) f(n)(x):表示 f ( x ) f(x) f(x)的 n n n阶导数;等号后的多项式称为函数 f ( x ) f(x) f(x)在 x 0 x_{0} x0处的泰勒展开式,剩余的 R n ( x ) R_{n}(x) Rn(x)是泰勒公式的余项,是 ( x − x 0 ) n \left(x-x_{0}\right)^{n} (x−x0)n的高阶无穷小。
- 1、佩亚诺(Peano)余项(普遍): R n ( x ) = o [ ( x ; − x 0 ) n ] R_{n}(x)=\mathrm{o}\left[\left(x ;-x_{0}\right)^{n}\right] Rn(x)=o[(x;−x0)n]
- 2、拉格朗日(Lagrange)余项: R n ( x ) = f ( n + 1 ) [ x 0 + θ ( x − x 0 ) ] ( x − x 0 ) n + 1 ( n + 1 ) ! R_{n}(x)=f^{(n+1)}\left[x_{0}+\theta\left(x-x_{0}\right)\right] \frac{\left(x-x_{0}\right)^{n+1}}{(n+1) !} Rn(x)=f(n+1)[x0+θ(x−x0)](n+1)!(x−x0)n+1
3.2.2、 求解方程
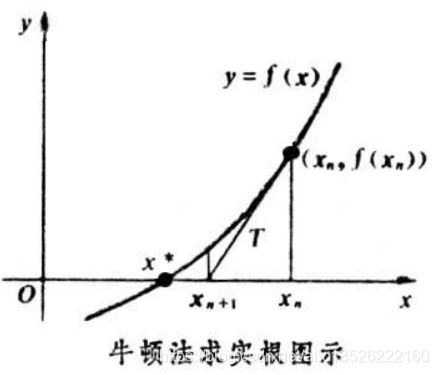
并不是所有的方程都有求根公式, 或者求根公式很复杂, 导致求解困难. 利用牛顿法, 可以迭代求解.
原理是利用泰勒公式, 在 x 0 x_{0} x0处展开, 且展开到一阶, 如下:
f ( x ) = f ( x 0 ) + ( x − x 0 ) f ′ ( x 0 ) f(x)=f\left(x_{0}\right)+\left(x-x_{0}\right) f^{\prime}\left(x_{0}\right) f(x)=f(x0)+(x−x0)f′(x0)
- 求解方程 f ( x ) = 0 f(x)=0 f(x)=0, 即: f ( x 0 ) + ( x – x 0 ) f ′ ( x 0 ) = 0 f(x_{0})+(x–x_{0})f′(x_{0})=0 f(x0)+(x–x0)f′(x0)=0, 求解: x = x 1 = x 0 – f ( x 0 ) / f ′ ( x 0 ) x=x_{1}=x_{0}–f(x_{0})/f′(x_{0}) x=x1=x0–f(x0)/f′(x0), 因为这是利用泰勒公式的一阶展开, f ( x ) = f ( x 0 ) + ( x – x 0 ) f ′ ( x 0 ) f(x)=f(x0)+(x–x0)f′(x0) f(x)=f(x0)+(x–x0)f′(x0)处并不是完全相等, 而是近似相等;
- 这里求得的 x 1 x_{1} x1并不能让 f ( x ) = 0 f(x)=0 f(x)=0, 只能说 f ( x 1 ) f(x_{1}) f(x1)的值比 f ( x 0 ) f(x_{0}) f(x0)更接近 f ( x ) = 0 f(x)=0 f(x)=0, 于是乎, 迭代求解的想法就很自然了, 可以进而推出 x n + 1 = x n – f ( x n ) / f ′ ( x n ) x_{n}+1=x_{n}–f(x_{n})/f′(x_{n}) xn+1=xn–f(xn)/f′(xn), 通过迭代, 这个式子必然在 f ( x ∗ ) = 0 f\left(x^{*}\right)=0 f(x∗)=0 的时候收敛. 整个过程如下图:
3.2.3、 最优化
在最优化的问题中, 线性最优化至少可以使用单纯形法(或称不动点算法)求解, 但对于非线性优化问题, 牛顿法提供了一种求解的办法. 假设任务是优化一个目标函数 f f f, 求函数 f f f的极大极小问题, 可以转化为求解函数f的导数 f ′ = 0 f′=0 f′=0的问题, 这样求可以把优化问题看成方程求解问题( f ′ = 0 f′=0 f′=0). 剩下的问题就和第一部分提到的牛顿法求解很相似了.
这次为了求解 f ′ = 0 f′=0 f′=0的根, 首先把 f ( x ) f(x) f(x)在探索点 x n x_{n} xn处泰勒展开, 展开到2阶形式进行近似:
f ( x ) = f ( x n ) + f ′ ( x n ) ( x − x n ) + f ′ ′ ( x n ) 2 ( x − x n ) 2 f(x)=f\left(x_{n}\right)+f^{\prime}\left(x_{n}\right)\left(x-x_{n}\right)+\frac{f^{\prime \prime}\left(x_{n}\right)}{2}\left(x-x_{n}\right)^{2} f(x)=f(xn)+f′(xn)(x−xn)+2f′′(xn)(x−xn)2
然后用 f ( x ) f(x) f(x)的最小点做为新的探索点 x n + 1 x_{n}+1 xn+1,据此,令:
f ′ ( x ) = f ′ ( x n ) + f ′ ′ ( x n ) ( x − x n ) = 0 f^{\prime}(x)=f^{\prime}\left(x_{n}\right)+f^{\prime \prime}\left(x_{n}\right)\left(x-x_{n}\right)=0 f′(x)=f′(xn)+f′′(xn)(x−xn)=0
求得出迭代公式:
x n + 1 = x n − f ′ ( x n ) f ′ ( x n ) , n = 0 , 1 , … x_{n+1}=x_{n}-\frac{f^{\prime}\left(x_{n}\right)}{f^{\prime}\left(x_{n}\right)}, n=0,1, \ldots xn+1=xn−f′(xn)f′(xn),n=0,1,…
一般认为牛顿法可以利用到曲线本身的信息, 比梯度下降法更容易收敛(迭代更少次数), 如下图是一个最小化一个目标方程的例子, 红色曲线是利用牛顿法迭代求解, 绿色曲线是利用梯度下降法求解.

在上面讨论的是2维情况, 高维情况的牛顿迭代公式是:
x n + 1 = x n − [ H f ( x n ) ] − 1 ∇ f ( x n ) , n ≥ 0 x_{n+1}=x_{n}-\left[H f\left(x_{n}\right)\right]^{-1} \nabla f\left(x_{n}\right), n \geq 0 xn+1=xn−[Hf(xn)]−1∇f(xn),n≥0
其中H是hessian矩阵, 定义见上. 高维情况依然可以用牛顿迭代求解, 但是问题是Hessian矩阵引入的复杂性, 使得牛顿迭代求解的难度大大增加, 但是已经有了解决这个问题的办法就是Quasi-Newton method, 不再直接计算hessian矩阵, 而是每一步的时候使用梯度向量更新hessian矩阵的近似.
参考了以下作者,这里表示感谢!
- jacoxu
- 刺客五六柒
- 番茄发烧了