Spark提交任务详解、宽窄依赖、算子
Spark任务提交、算子、RDD宽窄依赖、stage
一、任务提交
Standalone提交
在有压缩包的任意一个节点都可以提交无需配置
Standalone-client
1.命令
将jar包导入spark的examples文件夹中,进入spark/bin,执行命令:
./spark-submit --master spark://node1:7077 --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
./spark-submit --master spark://node1:7077 --deploy mode client --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
2.原理流程图

3.特点与不足
a 该模式中每个spark application都有自己的独立Driver,如果在客户端提交n个application就产生n个Driver,容易造成客户端网卡流量激增问题
b 在客户端可以看到task的执行过程和结果
c 该模式适用于测试环境
Standalone-cluster
1.命令
./spark-submit --master spark://node1:7077 --deploy mode cluster --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
2.原理流程图
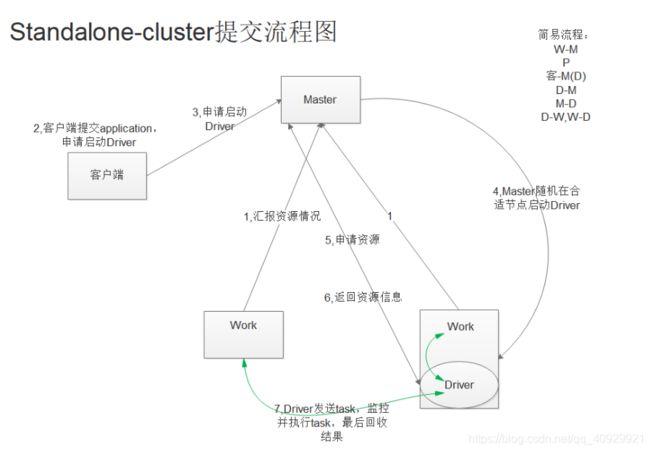
3.特点
a 在客户端提交多个application时,Driver随机在Work节点启动,客户端不会产生网卡流量激增问题,将这种问题分散到集群中
b 客户端看不到task执行过程和结果,WebUI中的FinishDriver可以查看正确执行过程和错误
c 适用于生产环境
Yarn提交
需要配置hadoop/etc/yarn-site.xml,添加
yarn.nodemanager.vmem-check-enabled falseYarn-client
1.命令
将jar包导入spark的examples文件夹中,进入spark/bin,执行命令:
./spark-submit --master yarn --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
./spark-submit --master yarn-client --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
./spark-submit --master yarn --deploy-mode client --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
2.原理流程图
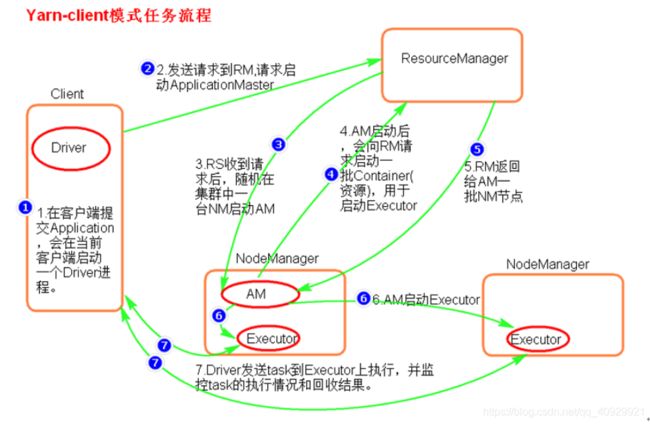
3.特点
a 该模式中客户端提交n个application就产生n个Driver,容易造成客户端网卡流量激增问题
b 在客户端可以看到task的执行过程和结果
c 该模式适用于测试环境
Yarn-cluster
1.命令
将jar包导入spark的examples文件夹中,进入spark/bin,执行命令:
./spark-submit --master yarn-cluster --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
./spark-submit --master yarn --deploy-mode cluster --class 项目包名.obj名 …/examples/jars/jar包名 分配partition数量
2.原理流程图

3.特点
a 当有多个application提交时,每个application的Driver(AM)是分散到集群中的NM中启动的,因此不会出现客户端网卡流量激增问题,将这种问题分散到集群中
b 在客户端看不到执行过程和结果,在yarn8088端口的finished可以查看
c 该模式适用于生产环境
二、RDD宽窄依赖
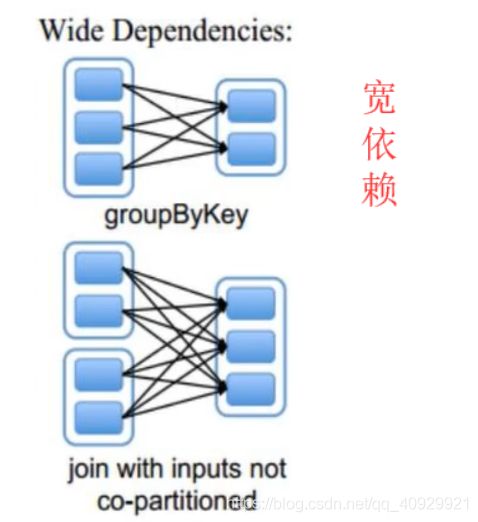
针对于多个RDD来讲,判断宽窄依赖要看父RDD的流出路径
只要有一个宽依赖,则该依赖就是宽依赖
宽依赖
父RDD与子RDD的partition之间是 1 :1
父RDD与子RDD的partition之间是 n :1
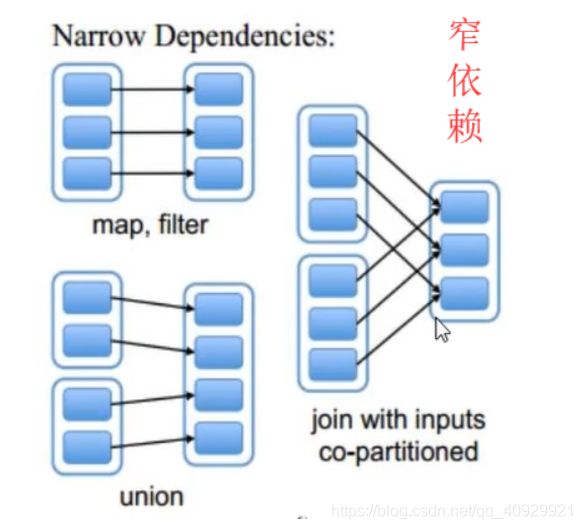
窄依赖
父RDD与子RDD的partition之间是 n :1
三、算子
此代码按照顺序进行排列,使用RDD数据就在上边一个
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("date2")
val sc = new SparkContext(conf)
sc.setLogLevel("Error")
。。。
。。。
}
}
join-合并
不相同的元素不打印
val nameRDD: RDD[(String, Int)] = sc.parallelize(List[(String,Int)](("zhangsan",18),("lisi",20),("wangwu",22),("maliu",24)))
val soreRDD: RDD[(String, Int)] = sc.parallelize(List[(String,Int)](("zhangsan",100),("lisi",200),("wangwu",300),("tianqi",400)))
//jion
val result: RDD[(String, (Int, Int))] = nameRDD.join(soreRDD)
result.foreach(println)
leftOuterJoin-偏左合并
leftOuterJoin 以左为主,左边的全都打印,没有的显示None
左边少,右边多的元素,不打印
遍历元素可以取元组下表
val result: RDD[(String, (Int, Option[Int]))] = nameRDD.leftOuterJoin(soreRDD)
result.foreach(one=>{
val name = one._1
val age = one._2._1
val sore = one._2._2.getOrElse("666")
println(s"name = $name, age=$age, sore = $sore")
})
rightOuterJoin-偏右合并
用法等同于leftOuterJoin
fullOuterJoin-全合并,None补空
左右两边都打印,没有的元素用None表示
val result: RDD[(String, (Option[Int], Option[Int]))] = nameRDD.fullOuterJoin(soreRDD)
result.foreach(println)
getNumPartitions-分区数
// //打印分区数
val p1 = nameRDD.getNumPartitions
val p2 = soreRDD.getNumPartitions
println(p1,p2)
//join数据后,新的RDD分区数与诸多父RDD的最大分区数保持一致
val result: RDD[(String, (Int, Int))] = nameRDD.join(soreRDD)
println(result.getNumPartitions)
union-单纯合并
本质上数据的合并,打印的是两个RDD的数据,分区数=诸多父类分区数的和
val result: RDD[(String, Int)] = nameRDD.union(soreRDD)
val partitions: Int = result.getNumPartitions
result.foreach(println)
println(partitions)
intersection-取交集
val rdd1: RDD[Int] = sc.parallelize(List[(Int)](1,2,3))
val rdd2: RDD[Int] = sc.parallelize(List[(Int)](2,3,6))
//intersection取交集
val result: RDD[Int] = rdd1.intersection(rdd2)
subtract-取差集
val rdd1: RDD[Int] = sc.parallelize(List[(Int)](1,2,3))
val rdd2: RDD[Int] = sc.parallelize(List[(Int)](2,3,6))
//subtract取差集
val result: RDD[Int] = rdd1.subtract(rdd2)
result.foreach(println)
map 和 partition
//N次执行加载N次
val rdd: RDD[String] = sc.parallelize(List[(String)]("hello1","hello2","hello3","hello4","hello5","hello6"),2)
//建立6次连接-map
rdd.map(one=>{
println("创建数据库连接...")
println(s"加载数据 $one")
println("创建数据库连接...")
one+ "!!!"
}).count()
//建立6次连接-foreach 不需要返回数据
rdd.foreach(one=>{
println("创建数据库连接...")
println(s"加载数据 $one")
println("创建数据库连接...")
})
mapPartitions 和 foreachPartition
执行N次,加载分区次数
//建立2次连接-map,上面分区数=2 业务需要对数据再进行处理使用mapPartition
val unit: RDD[String] = rdd.mapPartitions(iter => {
val list = new ListBuffer[String]
println("建立数据库连接。。。")
while (iter.hasNext) {
val str: String = iter.next()
println(s"插入数据 $str")
list.+=(str)
}
println("关闭数据库连接。。。")
list.iterator
})
unit.count()
// 建立2次连接-map,上面分区数=2 不需要返回数据 当业务插入数据库结束情况下考虑使用
rdd.foreachPartition(iter => {
val list = new ListBuffer[String]
println("建立数据库连接。。。")
while (iter.hasNext) {
val str: String = iter.next()
println(s"插入数据 $str")
}
println("关闭数据库连接。。。")
})
distinct-去重
val rdd: RDD[String] = sc.parallelize(List[(String)]("a","b","a","c","d","d"))
rdd.map(one=>{(one,1)}).reduceByKey((v1,v2)=>{v1+v2}).map(one=>{one._1}).foreach(println)
val unit: RDD[String] = rdd.distinct()
unit.foreach(print)
cogroup-合并
val nameRDD: RDD[(String, Int)] = sc.parallelize(List[(String,Int)](("zhangsan",18),("zhangsan",180),("zhangsan",180),("lisi",20),("wangwu",22),("maliu",24)),3)
val soreRDD: RDD[(String, Int)] = sc.parallelize(List[(String,Int)](("zhangsan",100),("lisi",200),("wangwu",300),("tianqi",400),("tianqi",40000)),4)
val unit: RDD[(String, (Iterable[Int], Iterable[Int]))] = nameRDD.cogroup(soreRDD)
unit.foreach(println)
println(unit.getNumPartitions)