Spark源码解读(6)——Shuffle过程
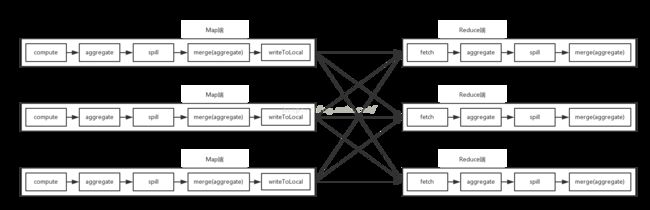
Shuffle应该说是Spark Core中较为复杂的部分,本文主要从一个最简单的WordCount例子出发分析Spark的Shuffle过程:
1,概述
sc.parallelize(1 to 1000).map(i=>(i%5,1)).reduceByKey(_+_).collect()计算过程中会分成两个Stage,如下图所示:
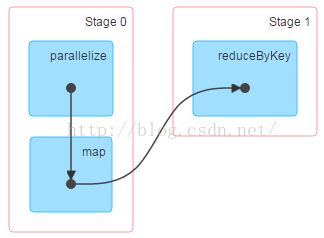
每个Stage由多个Task组成,同一Stage的各Task并行执行互不影响,但是后一个(Stage 1)需要等待前一个(Stage 0)执行结束才能开始执行,更为详细的执行过程如下图。
在Stage 0 和Stage 1之间存在数据交换,Stage 0 的Task无法确定其所产生的结果最终需要传递给Stage 1的哪个Task,因此数据需要按照一定的规则(Partitioner)重新打乱,这个过程称为Shuffle
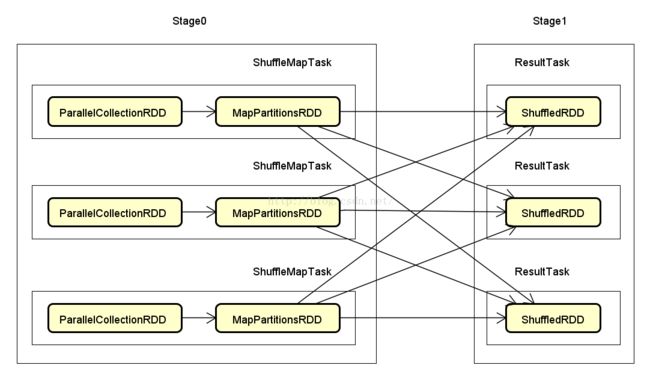
同一个Stage内Task的数量由Partition数量决定,对于ParallelCollectionRDD由默认并行度决定,如果设置了spark.default.parallelism则以该参数为准,否则当前Application总可用核心数(小于2时取值2):
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
} override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}ReduceByKey()过程如果没有指定partition的数量,则使用defaultPartitioner
这里如果父RDD有Partitioner则沿用父RDD的Partitioner,这里父RDD是map()操作得到的MapPartitionsRDD,Partitioner为None,因此这里Partitioner取默认的HashPartitioner
这里如果设置了spark.default.parallelism则分区数量由这个参数决定,否则由上一个RDD的partition数量决定,这里最终会由ParallelCollectionRDd的Partition数量决定
所以,对着各个转换Stage 1的Partition数量和Stage 0相同
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
} def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined && r.partitioner.get.numPartitions > 0) {
return r.partitioner.get
}
if (rdd.context.conf.contains("spark.default.parallelism")) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}2,详细的分析Shuffle过程
1)在分析Shuffle过程之前首先梳理一下Job的执行过程:
首先是Action触发Job的提交:SparkContext.runJob();
随后,调用DAGScheduler.runJob(),在这里完成了RDD到TaskSet的转换:
a)DAGScheduler最先进行Stage的划分,划分的依据是RDD的Dependency,没遇到一个ShuffleDependency就会划分出一个新的Stage,并递归提交父Stage:
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}b)而后确定Stage内每个Task的本地化倾向,并把结果传递给Stage:
/**
* Recursive implementation for getPreferredLocs.
*
* This method is thread-safe because it only accesses DAGScheduler state through thread-safe
* methods (getCacheLocs()); please be careful when modifying this method, because any new
* DAGScheduler state accessed by it may require additional synchronization.
*/
private def getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation] = {
// If the partition has already been visited, no need to re-visit.
// This avoids exponential path exploration. SPARK-695
if (!visited.add((rdd, partition))) {
// Nil has already been returned for previously visited partitions.
return Nil
}
// If the partition is cached, return the cache locations
val cached = getCacheLocs(rdd)(partition)
if (cached.nonEmpty) {
return cached
}
// If the RDD has some placement preferences (as is the case for input RDDs), get those
val rddPrefs = rdd.preferredLocations(rdd.partitions(partition)).toList
if (rddPrefs.nonEmpty) {
return rddPrefs.map(TaskLocation(_))
}
// If the RDD has narrow dependencies, pick the first partition of the first narrow dependency
// that has any placement preferences. Ideally we would choose based on transfer sizes,
// but this will do for now.
rdd.dependencies.foreach {
case n: NarrowDependency[_] =>
for (inPart <- n.getParents(partition)) {
val locs = getPreferredLocsInternal(n.rdd, inPart, visited)
if (locs != Nil) {
return locs
}
}
case _ =>
}
Nil
} stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
case stage: ResultStage =>
closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes) val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.internalAccumulators)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, stage.internalAccumulators)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
} taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))TaskScheduler将 Task加到队列之后就触发CoarseGrainedSchedulerBachend进行资源调度和LaunchTask操作:
加入队列:
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) backend.reviveOffers() // Make fake resource offers on all executors
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}TaskSet队列通过getSortedTaskSetQueue()来获取:
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}/**
* An interface for sort algorithm
* FIFO: FIFO algorithm between TaskSetManagers
* FS: FS algorithm between Pools, and FIFO or FS within Pools
*/
private[spark] trait SchedulingAlgorithm {
def comparator(s1: Schedulable, s2: Schedulable): Boolean
}
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
if (res < 0) {
true
} else {
false
}
}
}
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare: Int = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
} for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
} // Process local is expected to be used ONLY within TaskSetManager for now.
val PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY = Value executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))) case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}上面的WordCount Job执行的时候会分成ShuffleMapTask和ResultTask两个Task,首先执行ShuffleMapTask
ShuffleMapTask的执行大致可以分为这么几个部分:
a)从broadcast读取RDD和Dependency
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader) /**
* Value of the broadcast object on executors. This is reconstructed by [[readBroadcastBlock]],
* which builds this value by reading blocks from the driver and/or other executors.
*
* On the driver, if the value is required, it is read lazily from the block manager.
*/
@transient private lazy val _value: T = readBroadcastBlock()b)获取RDD的依赖数据、计算并存储在本地磁盘
这里首先获取Writer,而后调用Writer的write()方法:
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) // Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass) /** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}Writer的选择取决于ShuffleHandler的类型:
/**
* Register a shuffle with the manager and obtain a handle for it to pass to tasks.
*/
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
} def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
false
} else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
} /**
* Helper method for determining whether a shuffle should use an optimized serialized shuffle
* path or whether it should fall back to the original path that operates on deserialized objects.
*/
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
val serializer = Serializer.getSerializer(dependency.serializer)
if (!serializer.supportsRelocationOfSerializedObjects) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${serializer.getClass.getName}, does not support object relocation")
false
} else if (dependency.aggregator.isDefined) {
log.debug(
s"Can't use serialized shuffle for shuffle $shufId because an aggregator is defined")
false
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}Writer为:SortShuffleWriter
下面,继续看write()方法:
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} sorter.insertAll(records) val partitionLengths = sorter.writePartitionedFile(blockId, tmp) def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
} val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
} map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true) override def changeValue(key: K, updateFunc: (Boolean, V) => V): V = {
val newValue = super.changeValue(key, updateFunc)
super.afterUpdate()
newValue
} /**
* Set the value for key to updateFunc(hadValue, oldValue), where oldValue will be the old value
* for key, if any, or null otherwise. Returns the newly updated value.
*/
def changeValue(key: K, updateFunc: (Boolean, V) => V): V = {
assert(!destroyed, destructionMessage)
val k = key.asInstanceOf[AnyRef]
if (k.eq(null)) {
if (!haveNullValue) {
incrementSize()
}
nullValue = updateFunc(haveNullValue, nullValue)
haveNullValue = true
return nullValue
}
var pos = rehash(k.hashCode) & mask
var i = 1
while (true) {
val curKey = data(2 * pos)
if (k.eq(curKey) || k.equals(curKey)) {
val newValue = updateFunc(true, data(2 * pos + 1).asInstanceOf[V])
data(2 * pos + 1) = newValue.asInstanceOf[AnyRef]
return newValue
} else if (curKey.eq(null)) {
val newValue = updateFunc(false, null.asInstanceOf[V])
data(2 * pos) = k
data(2 * pos + 1) = newValue.asInstanceOf[AnyRef]
incrementSize()
return newValue
} else {
val delta = i
pos = (pos + delta) & mask
i += 1
}
}
null.asInstanceOf[V] // Never reached but needed to keep compiler happy
} /** Increase table size by 1, rehashing if necessary */
private def incrementSize() {
curSize += 1
if (curSize > growThreshold) {
growTable()
}
} /** Double the table's size and re-hash everything */
protected def growTable() {
// capacity < MAXIMUM_CAPACITY (2 ^ 29) so capacity * 2 won't overflow
val newCapacity = capacity * 2
require(newCapacity <= MAXIMUM_CAPACITY, s"Can't contain more than ${growThreshold} elements")
val newData = new Array[AnyRef](2 * newCapacity)
val newMask = newCapacity - 1
// Insert all our old values into the new array. Note that because our old keys are
// unique, there's no need to check for equality here when we insert.
var oldPos = 0
while (oldPos < capacity) {
if (!data(2 * oldPos).eq(null)) {
val key = data(2 * oldPos)
val value = data(2 * oldPos + 1)
var newPos = rehash(key.hashCode) & newMask
var i = 1
var keepGoing = true
while (keepGoing) {
val curKey = newData(2 * newPos)
if (curKey.eq(null)) {
newData(2 * newPos) = key
newData(2 * newPos + 1) = value
keepGoing = false
} else {
val delta = i
newPos = (newPos + delta) & newMask
i += 1
}
}
}
oldPos += 1
}
data = newData
capacity = newCapacity
mask = newMask
growThreshold = (LOAD_FACTOR * newCapacity).toInt
}在完成update操作之后会调用afterUpdate操作对数据的大小进行采样:
/**
* Callback to be invoked after every update.
*/
protected def afterUpdate(): Unit = {
numUpdates += 1
if (nextSampleNum == numUpdates) {
takeSample()
}
} nextSampleNum = math.ceil(numUpdates * SAMPLE_GROWTH_RATE).toLong下面直接看核心代码:
/**
* Get or compute the ClassInfo for a given class.
*/
private def getClassInfo(cls: Class[_]): ClassInfo = {
// Check whether we've already cached a ClassInfo for this class
val info = classInfos.get(cls)
if (info != null) {
return info
}
val parent = getClassInfo(cls.getSuperclass)
var shellSize = parent.shellSize
var pointerFields = parent.pointerFields
val sizeCount = Array.fill(fieldSizes.max + 1)(0)
// iterate through the fields of this class and gather information.
for (field <- cls.getDeclaredFields) {
if (!Modifier.isStatic(field.getModifiers)) {
val fieldClass = field.getType
if (fieldClass.isPrimitive) {
sizeCount(primitiveSize(fieldClass)) += 1
} else {
field.setAccessible(true) // Enable future get()'s on this field
sizeCount(pointerSize) += 1
pointerFields = field :: pointerFields
}
}
}
// Based on the simulated field layout code in Aleksey Shipilev's report:
// http://cr.openjdk.java.net/~shade/papers/2013-shipilev-fieldlayout-latest.pdf
// The code is in Figure 9.
// The simplified idea of field layout consists of 4 parts (see more details in the report):
//
// 1. field alignment: HotSpot lays out the fields aligned by their size.
// 2. object alignment: HotSpot rounds instance size up to 8 bytes
// 3. consistent fields layouts throughout the hierarchy: This means we should layout
// superclass first. And we can use superclass's shellSize as a starting point to layout the
// other fields in this class.
// 4. class alignment: HotSpot rounds field blocks up to to HeapOopSize not 4 bytes, confirmed
// with Aleksey. see https://bugs.openjdk.java.net/browse/CODETOOLS-7901322
//
// The real world field layout is much more complicated. There are three kinds of fields
// order in Java 8. And we don't consider the @contended annotation introduced by Java 8.
// see the HotSpot classloader code, layout_fields method for more details.
// hg.openjdk.java.net/jdk8/jdk8/hotspot/file/tip/src/share/vm/classfile/classFileParser.cpp
var alignedSize = shellSize
for (size <- fieldSizes if sizeCount(size) > 0) {
val count = sizeCount(size).toLong
// If there are internal gaps, smaller field can fit in.
alignedSize = math.max(alignedSize, alignSizeUp(shellSize, size) + size * count)
shellSize += size * count
}
// Should choose a larger size to be new shellSize and clearly alignedSize >= shellSize, and
// round up the instance filed blocks
shellSize = alignSizeUp(alignedSize, pointerSize)
// Create and cache a new ClassInfo
val newInfo = new ClassInfo(shellSize, pointerFields)
classInfos.put(cls, newInfo)
newInfo
} private def primitiveSize(cls: Class[_]): Int = {
if (cls == classOf[Byte]) {
BYTE_SIZE
} else if (cls == classOf[Boolean]) {
BOOLEAN_SIZE
} else if (cls == classOf[Char]) {
CHAR_SIZE
} else if (cls == classOf[Short]) {
SHORT_SIZE
} else if (cls == classOf[Int]) {
INT_SIZE
} else if (cls == classOf[Long]) {
LONG_SIZE
} else if (cls == classOf[Float]) {
FLOAT_SIZE
} else if (cls == classOf[Double]) {
DOUBLE_SIZE
} else {
throw new IllegalArgumentException(
"Non-primitive class " + cls + " passed to primitiveSize()")
}
}这里实际上是通过将引用放入一个queue中,而后在从中取出依次判断的方式实现的:
for (field <- classInfo.pointerFields) {
state.enqueue(field.get(obj))
} while (!state.isFinished) {
visitSingleObject(state.dequeue(), state)
}为了减少重复计算,这里对ClassInfo进行了缓存,这里使用了WeakReference防止出现Class已经被使用者释放却依然被classInfos引用的问题:
// A cache of ClassInfo objects for each class
// We use weakKeys to allow GC of dynamically created classes
private val classInfos = new MapMaker().weakKeys().makeMap[Class[_], ClassInfo]()当然这里还涉及到内存对齐的问题,上述计算内存占用方法中也多次调用alignSizeUp()方法,因为我对JVM内存对齐方式不太了解,就不再分析这里具体的对齐逻辑和原因了
/**
* Compute aligned size. The alignSize must be 2^n, otherwise the result will be wrong.
* When alignSize = 2^n, alignSize - 1 = 2^n - 1. The binary representation of (alignSize - 1)
* will only have n trailing 1s(0b00...001..1). ~(alignSize - 1) will be 0b11..110..0. Hence,
* (size + alignSize - 1) & ~(alignSize - 1) will set the last n bits to zeros, which leads to
* multiple of alignSize.
*/
private def alignSizeUp(size: Long, alignSize: Int): Long =
(size + alignSize - 1) & ~(alignSize - 1) /**
* Spill the current in-memory collection to disk if needed.
*
* @param usingMap whether we're using a map or buffer as our current in-memory collection
*/
private def maybeSpillCollection(usingMap: Boolean): Unit = {
var estimatedSize = 0L
if (usingMap) {
estimatedSize = map.estimateSize()
if (maybeSpill(map, estimatedSize)) {
map = new PartitionedAppendOnlyMap[K, C]
}
} else {
estimatedSize = buffer.estimateSize()
if (maybeSpill(buffer, estimatedSize)) {
buffer = new PartitionedPairBuffer[K, C]
}
}
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
} shouldSpill = currentMemory >= myMemoryThreshold shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold val it = collection.destructiveSortedWritablePartitionedIterator(comparator) /**
* A comparator for (Int, K) pairs that orders them both by their partition ID and a key ordering.
*/
def partitionKeyComparator[K](keyComparator: Comparator[K]): Comparator[(Int, K)] = {
new Comparator[(Int, K)] {
override def compare(a: (Int, K), b: (Int, K)): Int = {
val partitionDiff = a._1 - b._1
if (partitionDiff != 0) {
partitionDiff
} else {
keyComparator.compare(a._2, b._2)
}
}
}
} // A comparator for keys K that orders them within a partition to allow aggregation or sorting.
// Can be a partial ordering by hash code if a total ordering is not provided through by the
// user. (A partial ordering means that equal keys have comparator.compare(k, k) = 0, but some
// non-equal keys also have this, so we need to do a later pass to find truly equal keys).
// Note that we ignore this if no aggregator and no ordering are given.
private val keyComparator: Comparator[K] = ordering.getOrElse(new Comparator[K] {
override def compare(a: K, b: K): Int = {
val h1 = if (a == null) 0 else a.hashCode()
val h2 = if (b == null) 0 else b.hashCode()
if (h1 < h2) -1 else if (h1 == h2) 0 else 1
}
})分析完了
sorter.insertAll(records)之后,下面继续分析
val partitionLengths = sorter.writePartitionedFile(blockId, tmp) /**
* Return an iterator over all the data written to this object, aggregated by our aggregator.
*/
def iterator: Iterator[Product2[K, C]] = partitionedIterator.flatMap(pair => pair._2)
/**
* Write all the data added into this ExternalSorter into a file in the disk store. This is
* called by the SortShuffleWriter.
*
* @param blockId block ID to write to. The index file will be blockId.name + ".index".
* @return array of lengths, in bytes, of each partition of the file (used by map output tracker)
*/
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
if (spills.isEmpty) {
// Case where we only have in-memory data
val collection = if (aggregator.isDefined) map else buffer
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics.shuffleWriteMetrics.get)
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
writer.commitAndClose()
val segment = writer.fileSegment()
lengths(partitionId) = segment.length
}
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics.shuffleWriteMetrics.get)
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
writer.commitAndClose()
val segment = writer.fileSegment()
lengths(id) = segment.length
}
}
}
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.internalMetricsToAccumulators(
InternalAccumulator.PEAK_EXECUTION_MEMORY).add(peakMemoryUsedBytes)
lengths
} /**
* Merge a sequence of sorted files, giving an iterator over partitions and then over elements
* inside each partition. This can be used to either write out a new file or return data to
* the user.
*
* Returns an iterator over all the data written to this object, grouped by partition. For each
* partition we then have an iterator over its contents, and these are expected to be accessed
* in order (you can't "skip ahead" to one partition without reading the previous one).
* Guaranteed to return a key-value pair for each partition, in order of partition ID.
*/
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)])
: Iterator[(Int, Iterator[Product2[K, C]])] = {
val readers = spills.map(new SpillReader(_))
val inMemBuffered = inMemory.buffered
(0 until numPartitions).iterator.map { p =>
val inMemIterator = new IteratorForPartition(p, inMemBuffered)
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)
if (aggregator.isDefined) {
// Perform partial aggregation across partitions
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))
} else if (ordering.isDefined) {
// No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey);
// sort the elements without trying to merge them
(p, mergeSort(iterators, ordering.get))
} else {
(p, iterators.iterator.flatten)
}
}
} /**
* Merge-sort a sequence of (K, C) iterators using a given a comparator for the keys.
*/
private def mergeSort(iterators: Seq[Iterator[Product2[K, C]]], comparator: Comparator[K])
: Iterator[Product2[K, C]] =
{
val bufferedIters = iterators.filter(_.hasNext).map(_.buffered)
type Iter = BufferedIterator[Product2[K, C]]
val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {
// Use the reverse of comparator.compare because PriorityQueue dequeues the max
override def compare(x: Iter, y: Iter): Int = -comparator.compare(x.head._1, y.head._1)
})
heap.enqueue(bufferedIters: _*) // Will contain only the iterators with hasNext = true
new Iterator[Product2[K, C]] {
override def hasNext: Boolean = !heap.isEmpty
override def next(): Product2[K, C] = {
if (!hasNext) {
throw new NoSuchElementException
}
val firstBuf = heap.dequeue()
val firstPair = firstBuf.next()
if (firstBuf.hasNext) {
heap.enqueue(firstBuf)
}
firstPair
}
}
} shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp) execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}处理过程主要在BlockStoreShuffleReader的read()方法进行:
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024)
// Wrap the streams for compression based on configuration
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
blockManager.wrapForCompression(blockId, inputStream)
}
val ser = Serializer.getSerializer(dep.serializer)
val serializerInstance = ser.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map(record => {
readMetrics.incRecordsRead(1)
record
}),
context.taskMetrics().updateShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.internalMetricsToAccumulators(
InternalAccumulator.PEAK_EXECUTION_MEMORY).add(sorter.peakMemoryUsedBytes)
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
} mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition) val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId)) private[this] def splitLocalRemoteBlocks(): ArrayBuffer[FetchRequest] = {
// Make remote requests at most maxBytesInFlight / 5 in length; the reason to keep them
// smaller than maxBytesInFlight is to allow multiple, parallel fetches from up to 5
// nodes, rather than blocking on reading output from one node.
val targetRequestSize = math.max(maxBytesInFlight / 5, 1L)
logDebug("maxBytesInFlight: " + maxBytesInFlight + ", targetRequestSize: " + targetRequestSize)
// Split local and remote blocks. Remote blocks are further split into FetchRequests of size
// at most maxBytesInFlight in order to limit the amount of data in flight.
val remoteRequests = new ArrayBuffer[FetchRequest]
// Tracks total number of blocks (including zero sized blocks)
var totalBlocks = 0
for ((address, blockInfos) <- blocksByAddress) {
totalBlocks += blockInfos.size
if (address.executorId == blockManager.blockManagerId.executorId) {
// Filter out zero-sized blocks
localBlocks ++= blockInfos.filter(_._2 != 0).map(_._1)
numBlocksToFetch += localBlocks.size
} else {
val iterator = blockInfos.iterator
var curRequestSize = 0L
var curBlocks = new ArrayBuffer[(BlockId, Long)]
while (iterator.hasNext) {
val (blockId, size) = iterator.next()
// Skip empty blocks
if (size > 0) {
curBlocks += ((blockId, size))
remoteBlocks += blockId
numBlocksToFetch += 1
curRequestSize += size
} else if (size < 0) {
throw new BlockException(blockId, "Negative block size " + size)
}
if (curRequestSize >= targetRequestSize) {
// Add this FetchRequest
remoteRequests += new FetchRequest(address, curBlocks)
curBlocks = new ArrayBuffer[(BlockId, Long)]
logDebug(s"Creating fetch request of $curRequestSize at $address")
curRequestSize = 0
}
}
// Add in the final request
if (curBlocks.nonEmpty) {
remoteRequests += new FetchRequest(address, curBlocks)
}
}
}
logInfo(s"Getting $numBlocksToFetch non-empty blocks out of $totalBlocks blocks")
remoteRequests
} results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf))正处于Fetching状态的Block总大有一个限制,默认为48M
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024) dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context) def combineCombinersByKey(
iter: Iterator[_ <: Product2[K, C]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, C, C](identity, mergeCombiners, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
} combiners.insertAll(iter) /**
* Insert the given iterator of keys and values into the map.
*
* When the underlying map needs to grow, check if the global pool of shuffle memory has
* enough room for this to happen. If so, allocate the memory required to grow the map;
* otherwise, spill the in-memory map to disk.
*
* The shuffle memory usage of the first trackMemoryThreshold entries is not tracked.
*/
def insertAll(entries: Iterator[Product2[K, V]]): Unit = {
if (currentMap == null) {
throw new IllegalStateException(
"Cannot insert new elements into a map after calling iterator")
}
// An update function for the map that we reuse across entries to avoid allocating
// a new closure each time
var curEntry: Product2[K, V] = null
val update: (Boolean, C) => C = (hadVal, oldVal) => {
if (hadVal) mergeValue(oldVal, curEntry._2) else createCombiner(curEntry._2)
}
while (entries.hasNext) {
curEntry = entries.next()
val estimatedSize = currentMap.estimateSize()
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
if (maybeSpill(currentMap, estimatedSize)) {
currentMap = new SizeTrackingAppendOnlyMap[K, C]
}
currentMap.changeValue(curEntry._1, update)
addElementsRead()
}
} curEntry = entries.next()在完成insertAll()操作之后对外暴露一个新的Iterator,这个Iterator提供的Element是经过聚合操作之后的数据,刚才提到在聚合的时候如果内存不够用则会spill到本地磁盘,如果发生这种情况这里就必须提供ExternalIterator:
/**
* Return a destructive iterator that merges the in-memory map with the spilled maps.
* If no spill has occurred, simply return the in-memory map's iterator.
*/
override def iterator: Iterator[(K, C)] = {
if (currentMap == null) {
throw new IllegalStateException(
"ExternalAppendOnlyMap.iterator is destructive and should only be called once.")
}
if (spilledMaps.isEmpty) {
CompletionIterator[(K, C), Iterator[(K, C)]](currentMap.iterator, freeCurrentMap())
} else {
new ExternalIterator()
}
} /**
* Select a key with the minimum hash, then combine all values with the same key from all
* input streams.
*/
override def next(): (K, C) = {
if (mergeHeap.length == 0) {
throw new NoSuchElementException
}
// Select a key from the StreamBuffer that holds the lowest key hash
val minBuffer = mergeHeap.dequeue()
val minPairs = minBuffer.pairs
val minHash = minBuffer.minKeyHash
val minPair = removeFromBuffer(minPairs, 0)
val minKey = minPair._1
var minCombiner = minPair._2
assert(hashKey(minPair) == minHash)
// For all other streams that may have this key (i.e. have the same minimum key hash),
// merge in the corresponding value (if any) from that stream
val mergedBuffers = ArrayBuffer[StreamBuffer](minBuffer)
while (mergeHeap.length > 0 && mergeHeap.head.minKeyHash == minHash) {
val newBuffer = mergeHeap.dequeue()
minCombiner = mergeIfKeyExists(minKey, minCombiner, newBuffer)
mergedBuffers += newBuffer
}
// Repopulate each visited stream buffer and add it back to the queue if it is non-empty
mergedBuffers.foreach { buffer =>
if (buffer.isEmpty) {
readNextHashCode(buffer.iterator, buffer.pairs)
}
if (!buffer.isEmpty) {
mergeHeap.enqueue(buffer)
}
}
(minKey, minCombiner)
}