前端寒假计划
1、HTML
1.1块级元素的特点:
- 独占一行
- 支持所有样式
- 不设置宽度时宽度为父元素宽度
- 换行符不解析
- 可以容纳内联元素和其他块元素
常见的块元素有:div、ul、ol、li、h1~h6、p、table、address、form、center、dl、dt、dd、menu、hr、
内联元素的特点:
- 可以在一行显示
- 不支持宽高,上下margin和padding等样式会有问题
- 宽度由内容撑开
- 换行符会被解析成空格
常见的内联元素有:span、a、input、img、textarea、abbr、b、br、big、i、sub、sup、strong、select
内联块元素的特点:
- 内联块元素同时具备块级元素和内联元素的特点
空元素:
内嵌元素:
img-----在html文档里面嵌入图像;
a元素里使用img-----创建基于图形的超链接;
将img或object与map和area结合使用------创建客户端分区响应图;
audio、video、source/track----不通过插件嵌入音频和视频(html5)
iframe----嵌入另一张html文档;
emnbed或object-----通过插件嵌入内容;
使用object元素,用他的name属性定义浏览器上下文的名称----创建浏览 上下文;
canvas-----在html文档里嵌入图形(html5)
常见的元素的特点属性:
href:用于a标签里的链接方式或链接css文件;并行加载
src:用于链接js文件或图片;不是并行加载
alt:用来指定替换文字,只能用在img、area和input元素中,用于网页中图片无法正常显示时给用户提供文字说明使其了解 图像信息 alt是替代图像作用而不是提供额外说明文字
title:作为属性时用来为元素提供额外的说明信息;作为标签时里面写入网页标题,主要是文字说明
1.1.2、页面导入样式时,使用link和@import有什么区别?
答案解析:
1)link属于XHTML标签,而@import是css提供的;
2)页面被加载时,link会同时被加载,而@import引用的css会等到页面被加载完再加载;
3)@import只在IE5以上才能识别,而link是XHTML标签,无兼容问题;
4)link方式的样式的权重高于@import的权重。
1.2.1.html语义化:
what:根据内容的结构化,选择合适的语义化标签,便于开发者阅读和代码美观
why:
- 为了在没有css的情况下,页面也可以很好的体现内容结构代码结构
- 有利于用户体验
- 有利于搜索引擎根据标签的语义确定上下文和权重问题
- 便于团队开发和维护,语义化更具有可读性
1.2.2、SEO的原理:
SEO一共包括三个过程:网页搜索、预处理信息、建立索引。 细化分为:爬行—抓取—处理抓取信息—建立索引—呈现排名
一、爬行
爬行的目的:建立待抓取列表
爬虫:谷歌爬虫(ddos)百度爬虫(spider)
1.发现:
对于一个网站来说,分为被动等待和主动引爬虫
被动等待:设置好Robots.txt文件,放在服务器等待爬虫自己过来爬取
主动引爬虫:写带有链接的软文花钱放在高质量高权重的网站中、利用权重高的博客、在质量高的论坛里发外链
2.内容:
争取权重高的位置放
Banner不如幻灯片,幻灯片不如文字,文字优先,图片写alt属性
二、抓取
网页本身需要符合W3C标准,编码建议使用“utf-8”,“title”尽量靠前,我们想让爬虫进入到某个页面就看到我们的主旨内容,内容尽量原创
正文:关键词出现的次数要合适,位置要靠前
“h1标签”:唯一性,整个页面最重要,含关键字,尽量靠前
“h2标签”:可以添加其他属性
“alt属性”:只能用于“img”,意在告诉蜘蛛图片的解释
“title属性”:为链接添加描述性文字,可为用户提供更清楚表达的意思
“锚文本”:锚文本得有相关的关键词,且面面相关
三、处理抓取结果
爬虫抓取后压缩成数据包返回数据库
相关性:因为百度算法语境分析+语义分析的原因,所以网站不要出现不相关的内容出现,否则搜索引擎也会撇掉你的网站权威性(网络拼比,信任度等)
**注:**不权威造成的影响:同一篇文章,由于信任度高低,有可能自己被转载发布的文章自己的反倒在别人网站后面
去重:一个链接不能有多个页面、同一个关键词不能指向不同链接、同一页面下不要出现不同链接相同的关键词
四、建立索引
搜索引擎的索引是反向建立的 (一个关键词对应许多文件[网站/网页])
什么是爬虫?
爬虫一般指网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或脚本
如何去写一个爬虫?
1.3!DOCTYPE的作用:
Doctype是document type的简写,声明叫做文件类型定义(DTD),声明的作用是为了告诉浏览器该文件的类型,让浏览器解析器知道用哪个规范来解析文档,!Doctype必须放在HTML文档的第一行,它不是一个HTML标签。
严格模式和混杂模式的区别以及如何触发两种模式
严格模式:又称为标准模式,是指浏览器按照W3C标准解析代码
混杂模式:又称怪异模式或兼容模式,是指浏览器用自己的方式解析代码
区别:浏览器解析时到底使用严格模式还是混杂模式,与网页中的DTD相关
1.如果文档包含严格的DOCTYPE,那么它一般以严格模式呈现。(严格DTD——严格模式)
2.包含URL的过渡DTD的DOCTYPE,也以严格模式呈现,但有过渡DTD而没有URL(统一资源标识符,就是声明最后的地址)会导致页面以混杂模式呈现。(有URL的过渡DTD——严格模式;没有URL的过渡DTD——混杂模式)
3.DOCTYPE不存在或形式不正确会导致文档以混杂模式呈现。(DTD不存在或者格式不正确——混杂模式)
4.HTML5没有DTD,因此也就没有严格模式与混杂模式的区别,HTML5有相对宽松得语法,实现时,已经尽可能大的实现了向后兼容。(HTML没有严格与混杂之分)
H5只需要写一个的原因:
HTML5不基于SGML,因此不需要对DTD进行引用,但是需要DOCTYPE来规范浏览器的行为(让浏览器按照他们应该的方式来运行)HTML4.01基于SGML,所以需要对DTD进行引用,才能告知浏览器文档所使用的文档类型。
1.4.DOM:
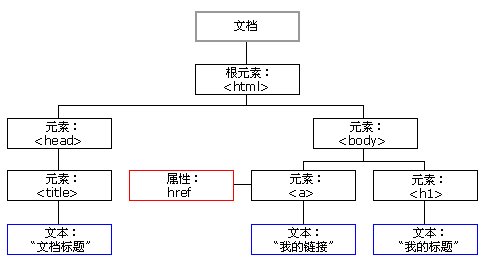
什么是DOM?
DOM是Document Object Model(文档对象模型)的缩写,是W3C的标准,它定义了访问HTML和XML文档的标准:“W3C文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。”
W3C DOM标准被分为3个不同的部分:
- 核心 DOM - 针对任何结构化文档的标准模型
- XML DOM - 针对XML文档的标准模型
- HTML DOM - 针对 HTML 文档的标准模型
什么是HTML DOM?
HTML DOM 是:
- HTML 的标准对象模型
- HTML 的标准编程接口
- W3C 标准
HTML DOM定义了所有HTML元素的对象和属性,以及访问它们的方法。
换言之,HTML DOM是关于如何获取、修改、添加或删除HTML元素的标准
如何去优化DOM结构?
把DOM和Javascript各自想象成一个岛屿,它们之间用收费桥梁连接因此要避免去操作DOM,还要减少去访问DOM的次数。
document.getElementsById(‘btn’).onclick
1.4.2、IE事件模型
IE的事件模型没有捕获阶段的,先执行元素的监听函数,然后事件的目标元素上升一直到document。只有IE浏览器能使用。
捕获:
标准: addEventListener(事件名称,事件函数,是否捕获) true捕获,事件名称没on,顺序执行,this指向对象
IE: attachEvent(事件名称,事件函数) 没有捕获,事件名称有on,事件是倒序执行,this指向window
解除绑定:
标准: removeEventListener (事件名称,事件函数,是否捕获)
IE: detachEvent (事件名称,事件函数 );
1.4.3、DOM2级事件模型:
现代浏览器(IE9以下不算)都遵 循了这个规范。
W3C制定的事件模型中,一次事件的发生包含三个过程:
a、事件捕获阶段。事件被从document一直向下传播到目标元素,在这过程中依次检查经过的节点是否注册了该事件的监听函数,若有就执行。
b、事件处理阶段。事件到达目标元素,执行目标元素的事件处理函数.
c、事件冒泡阶段。事件从目标元素上升一直到达document,同样依次检查经过的节点是否注册 了该事件的监听函数,有则执行。
注意:所有的事件类型都会经历事件捕获阶段,但是只有部分事件会经历事件冒泡阶段,例如 submit事件就不会被冒泡。为了最大程度兼容各种浏览器,一般都是将事件处理函程序添加到事件流的冒泡阶段。
1、事件委托
利用冒泡事件,把一个元素响应事件(click、keydown......)的函数委托到另一个元素,比如ul里面有很多li,给li添加点击事件,可以委托给ul
委托的优点
1. 减少内存消耗
2. 动态绑定事件:因为事件是绑定在父层的。
2、阻止冒泡:
event是事件对象,但是只有IE支持,var oEvent=ev||event,不能反过来,因为var oEvent=ev||event中的||是遇真返回,返回第一个Boolean类型为true的值
在IE中执行var oEvent = ev || event;时,ev为undefined,即为false,而event为true。所以返回的是它所支持的event。在其他浏览器中,第一个ev为true,直接返回,不用理会后面的event。
而反过来写,var oEvent = event || ev;
IE下不会报错,直接返回第一个为true的event
但在其他浏览器中,event没有被定义,直接报错。
ev.cancelBubble = true阻止冒泡,只支持IE浏览器
event.stopPropagation( )阻止冒泡,W3C标准
evevt.preventDefault() :取消事件的默认行为,比如点击a标签默认跳转链接,点击button默认提交
event.target存着发生事件的目标元素
currentTarget:事件处理程序当前正在处理的事件的那个元素
1.4.4、DOM常见操作:
DOM操作(文档对象模型,标准化组织W3C)DOM学习
1、DOM创建
document.createElement(‘div1’)
document.createTextNode(‘div2’)
2、DOM查询
// 返回当前文档中第一个类名为 "myclass" 的元素
document.querySelector(‘.myclass’)
// 返回一个文档中所有的class为"note"
document.querySelectorAll(‘div.note’)
3、获取元素
var A = document.getElementById('x');
var A = document.getElementsByClassName('x');
var A = document.getElementsByTagName('x');
兼容的获取第一个子元素节点方法:
var first=ele.firstElementChild||ele.children[0];
3、DOM添加、删除、替换、插入、克隆
a.appendChild(e);// 添加子元素
a.removeChild(e);// 删除子元素
ele.replaceChild(el1, el2);// 替换子元素
parentElement.insertBefore(newElement, referenceElement);// 插入子元素
//克隆元素
ele.cloneNode(true) //该参数指示被复制的节点是否包括原节点的所有属性和子节点
4、属性操作
// 获取一个{name, value}的数组
var attrs = el.attributes;
// 获取、设置属性
var c = el.getAttribute('class');
el.setAttribute('class', 'highlight');
// 判断、移除属性
el.hasAttribute('class');
el.removeAttribute('class');
// 是否有属性设置
el.hasAttributes();
比如对于这样一个HTML元素:
· innerHTML:内部HTML,content
;
· outerHTML:外部HTML,
· innerText:内部文本,content;
· outerText:内部文本,content;

上述四个属性不仅可以读取,还可以赋值。outerText和innerText的区别在于outerText赋值时会把标签一起赋值掉,另外xxText赋值时HTML特殊字符会被转义。
jQuery的.html()会调用.innerHTML来操作,但同时也会catch异常,然后用.empty(), .append()来重新操作。 这是因为IE8中有些元素(比如input等)的.innerHTML是只读的
1.5标签嵌套规则及HTML转义
标签嵌套:1. 块元素可以嵌套块元素、也可以嵌套内联元素;
2. 特殊块元素只能嵌套内联元素(p h dt定义列表);
3. 块元素不可以放在p中;
4. li可以嵌套div。
HTML转义:一些字符在html中具有特殊含义,比如‘<’标签,所以要插入字符实体。
字符实体分为三种:1.&一个和号
2.一个实体名称
3.一个实体编号以及分号
1.6HTML5canvas svg localstorage sessionstorage session postMessage
2、CSS
1.清除浮动:
1.overflow:hidden;
2.clear:both;3. .clearfix:before,.clearfix:after {
content: "";
display: block;
clear: both;
}
.clearfix {
zoom: 1;
}
4、父元素设置高度
2.2.position:
relative:相对定位,相对于自身原来的位置定位.
absolute:绝对定位,相对于第一个父级有定位(不是static)的元素进行定位 否则为相对于浏览器窗口。
1.盒子的绝对定位以最近的一个已定位的父级元素为基准;如果父级元素没有定位或没有父级元素,则以浏览器窗口为基准。
2.绝对定位的盒子会脱离标准文档流,不影响同一级的盒子元素位置。
fixed:固定定位,相对于浏览器窗口定位。
static:是position属性的默认值,表示块状元素保持在标准文档流中原有的位置,不做任何移动。就是按正常的布局流从上到下从左到右布局。
inherit:继承父元素的position属性
sticky:粘性定位,一个结合了 position:relative 和 position:fixed 两种定位功能于一体的特殊定位,适用于一些特殊场景。1.元素先按照普通文档流定位,然后相对于该元素在流中的 flow root(BFC)和 containing block(最近的块级祖先元素)定位。而后,元素表现为在跨越特定阈值前为相对定位,之后为固定定位。
2.这个特定阈值指的是 top, right, bottom 或 left 之一,换言之,指定 top, right, bottom 或 left 四个阈值其中之一,才可使粘性定位生效。否则其行为与相对定位相同。并且top优先级高于bottom;left优先级高于right。
Z-index规定页面重叠次序,仅能在有定位的时候有效(即不是static都可以)
元素可以拥有负的Z-index值,z-index是在同级中比较的(同级中z-index小的元素,无论内部的子元素z-index有多大,都会处在父级元素中z-index较大的元素的底层)
2.3.优先级:
1.!important优先级最高
2.行内样式,权重为1000
3.id选择器,权重为0100
4.类选择器或者伪类,权重为0010
5.元素和伪元素,权重为0001
6.通配符,0000
伪类与伪元素:
伪类:用于向某些选择器添加特殊的效果。使用两个冒号::first-line
伪元素:用于将某些特殊的效果添加到选择器。使用一个冒号:first-child
伪类: :link; :visited; :hover; :active; :first-child;
伪元素: :before; :after; :first-letter; :first-line;
目前为止,伪元素在一个选择器里只能出现一次,并且只能出现在末尾。实则,伪元素是选中了某个元素的符合逻辑的某个实际却不存在的部分,所以应用中也不会有人将其误写成多个。伪类则是像真正的类一样发挥着类的作用,没有数量上的限制,只要不是相互排斥的伪类,也可以同时使用在相同的元素上。